


MongoDB 集群
优质博文:IT-BLOG-CN
一、高可用架构
高可用性HA(High Availability)指的是缩短因正常运维或者非预期故障而导致的停机时间,提高系统可用性。
高可用量化衡量标准: 引出一个SLA的概念。SLA是Service Level Agreement(服务等级协议)的缩写。SLA就是用来量化可用性的协议,在双方认可的前提条件下,服务提供商与用户间定义的一种双方认可的协定。SLA是判定服务质量的重要指标。
SLA 是怎么量化的?其实就是按照停服时间进行计算?举个例子:
1 年 = 365 天 = 8760 小时
99.9 停服时间:8760 * 0.1% = 8760 * 0.001 = 8.76小时
99.99 停服时间:8760 * 0.0001 = 0.876 小时 = 52.6 分钟
99.999 停服时间:8760 * 0.00001 = 0.0876 小时 = 5.26分钟
也就是说,如果一家公有云厂商提供对象存储的服务,SLA协议指明提供5个9的高可用服务,那就要保证一年的时间内对象存储的停服时间少于5.26分钟,如果超过这个时间,就算违背了SLA协议,可以找公有云提出赔偿。
前面我们说过,无论是数据的高可靠,还是组件的高可用全都是一个解决方案:冗余。我们通过多个组件和备份导致对外提供一致性和不中断的服务。冗余是根本,但是怎么来使用冗余则各有不同。
以下我们就按照不同的冗余处理策略,可以总结出MongoDB几个特定的模式,这个也是通用性质的架构,在其他的分布式系统也是常见的。
我们从Mongo的三种高可用模式逐一介绍,这三种模式也代表了通用分布式系统下高可用架构的进化史,分别是Master-Slave,Replica Set,Sharding模式。
二、副本集群
MongoDB副本集架构通过部署多个服务器存储数据副本来达到高可用的能力,每一个副本集实例由一个Primary节点和一个或多个 Secondary节点组成。Primary角色是通过整个集群共同选举出来的,每个服务都可能成为Primary,每个服务最开始只是Secondary,而这个选举过程完全自动,不需要人为参与。
Primary节点: 负责处理客户端的读写请求。每个副本集架构实例中只能有一个Primary节点。
读请求默认是发到
Primary节点处理,如果需要故意转发到Secondary需要客户端修改一下配置(注意:是客户端配置,决策权在客户端)。
Secondary节点: 通过定期轮询Primary节点的oplog(操作日志)复制Primary节点的数据,类似于mysql的binlog。保证数据与Primary节点一致。在 Primary节点故障时,多个Secondary节点通过选举成为新的Primary节点,保障高可用。在每一个副本集的节点中,都会存在一个名为local.oplog.rs的特殊集合。 当Primary上的写操作完成后,会向该集合中写入一条oplog,而Secondary则持续从Primary拉取新的oplog并在本地进行回放以达到同步的目的。
下面,看看一条oplog的具体形式:
{
"ts" : Timestamp(1446017544, 2), #该字段不仅仅包含了操作的时间戳`timestamp`,还包含一个自增的计数器值。
"h" : NumberLong("1327359106895543098"), # 操作的全局唯一表示
"v" : 2, #oplog 的版本信息
"op" : "i", # 操作类型,比如 i=insert,u=update..
"ns" : "test.nosql", #操作集合,形式为 database.collection
"o" : { "_id" : ObjectId("543478v0b085733f34ab7698"), "name" : "mongodb", "score" : "100" } #指具体的操作内容,对于一个 insert 操作,则包含了整个文档的内容
}
MongoDB对于oplog的设计是比较仔细的,比如:
oplog必须保证有序,通过optime来保证。
oplog必须包含能够进行数据回放的完整信息。
oplog必须是幂等的,即多次回放同一条日志产生的结果相同。
oplog集合是固定大小的,为了避免对空间占用太大,旧的oplog记录会被滚动式的清理。
Secondary相互有心跳,Secondary可以作为数据源,Replica可以是一种链式的复制模式。
Arbiter仲裁者: 不存储数据,不会被选为主,只进行选主投票。使用Arbiter可以减轻在减少数据的冗余备份,又能提供高可用的能力。
副本集的系统架构图如下:
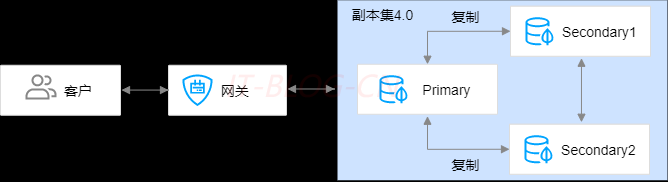
MongoDB的Replica Set副本集模式主要有以下几个特点:
【1】数据多副本,在故障的时候,可以使用完的副本恢复服务。注意:这里是故障自动恢复;
【2】读写分离,读的请求分流到副本上,减轻主Primary的读压力;
【3】节点直接互有心跳,可以感知集群的整体状态;
读写分离只能增加集群"读"的能力,对于写负载非常高的情况却无能为力。对此需求,使用分片集群并增加分片,或者提升数据库节点的磁盘
IO、CPU能力可以取得一定效果。
优缺点: 可用性大大增强,因为故障时自动恢复,主节点故障,立马就能选出一个新的Primary节点。但是有一个要注意的点:每两个节点之间互有心跳,这种模式会导致节点的心跳几何倍数增大,单个Replica Set 集群规模不能太大,一般来讲最大不要超过50个节点。参与投票节点数要是奇数,因为偶数会导致脑裂,也就是投票数对等的情况,无法选出Primary。
选举
MongoDB副本集通过Raft算法链接来完成主节点的选举,这个环节在初始化的时候会自动完成,如下面的命令:
config = {
_id : "my_replica_set",
members : [
{_id : 0, host : "rs1.example.net:27017"},
{_id : 1, host : "rs2.example.net:27017"},
{_id : 2, host : "rs3.example.net:27017"},
]
}
rs.initiate(config)
initiate命令用于实现副本集的初始化,在选举完成后,通过isMaster()命令就可以看到选举的结果:
> db.isMaster()
{
"hosts" : [
"192.168.126.41:27030",
"192.168.126.42:27030",
"192.168.126.43:27030"
],
"setName" : "myReplSet",
"setVersion" : 1,
"ismaster" : true,
"secondary" : false,
"primary" : "192.168.126.41:27030",
"me" : "192.168.126.41:27030",
"electionId" : ObjectId("7fffffff0000000000000001"),
"ok" : 1
}
心跳
在高可用的实现机制中,心跳heartbeat是非常关键的,判断一个节点是否宕机就取决于这个节点的心跳是否还是正常的。副本集中的每个节点上都会定时向其他节点发送心跳,以此来感知其他节点的变化,比如是否失效、或者角色发生了变化。利用心跳,MongoDB副本集实现了自动故障转移的功能。
默认情况下,节点会每2秒向其他节点发出心跳,这其中包括了主节点。 如果备节点在10秒内没有收到主节点的响应就会主动发起选举。
此时新一轮选举开始,新的主节点会产生并接管原来主节点的业务。整个过程对于上层是透明的,应用并不需要感知,因为Mongos会自动发现这些变化。
如果应用仅仅使用了单个副本集,那么就会由Driver层来自动完成处理。
三、分发集群
MongoDB分片集群Sharded Cluster架构在副本集的基础上,通过多组复制集群的组合,实现数据的横向扩展。每一个分片集群实例由 mongos节点、config server、shard节点等组件组成,解决大数据量问题。水平扩容扩展的容量仅需要根据需要添加其他服务器,这比垂直扩容一台高端硬件的机器成本还低,代价就是软件的基础结构要支持,部署维护要复杂。
纵向优化的方案非常容易到达物理极限,横向优化则对个体要求不高,而是群体发挥效果(但是对软件架构提出更高的要求)。
代理层mongos节点: 这是个无状态的组件,纯粹是路由功能。负责接收所有客户端应用程序的连接查询请求,并将请求路由到集群内部对应的分片上,同时会把接收到的响应拼装起来返回到客户端。您可以拥有多个mongos节点实现负载均衡及故障迁移。每一个分片集群实例可支持3个-32个mongos节点。应用节点可以通过同时连接多个Mongos来实现高可用,当然,连接高可用的功能是由Driver实现的。
配置中心config server节点: 代理层是无状态的模块,数据层的每一个Shard是各自独立的,那总要有一个集群统配管理的地方,这个地方就是配置中心。负责存储集群和Shard节点的元数据信息,如集群的节点信息、分片数据的路由信息、每个Shard里大概存储了多少数据量等。配置中心存储的就是集群拓扑,管理的配置信息。这些信息也非常重要,所以也不能单点存储,所以配置中心也是一个Replica Set集群,数据也是多副本的。ConfigServer节点规格固定为1核2GB,磁盘空间为20GB,默认3副本集,不可变更配置。
数据层shard节点: 负责将数据分片存储在多个服务器上。其实数据层就是由一个个Replica Set集群组成。这样的一个Replica Set我们就叫做 Shard。您可以拥有多个Shard节点来横向扩展实例的数据存储和读写并发能力。每一个分片集群实例可支持2个-20个Shard节点。
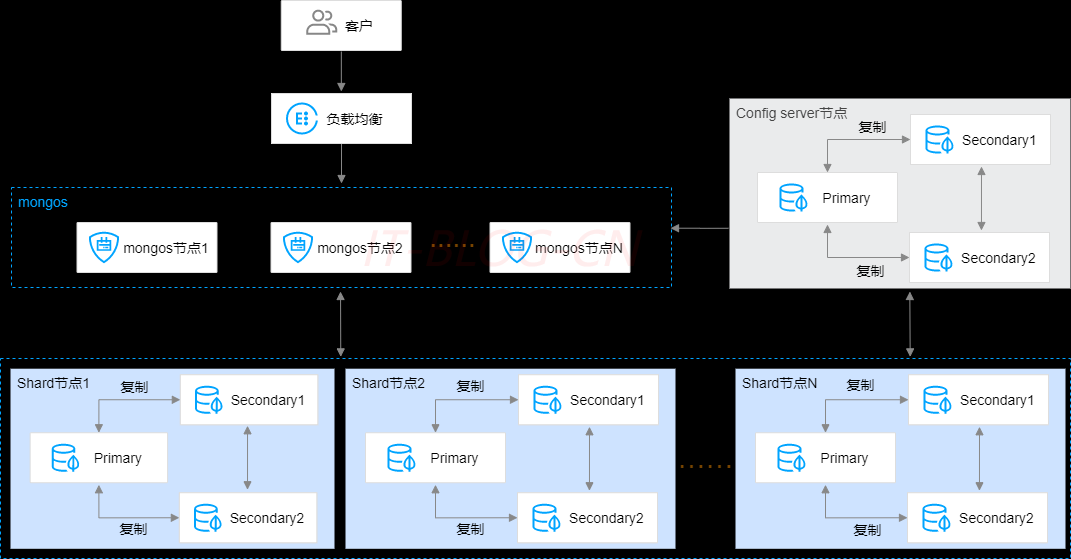
Sharding 模式怎么存储数据
我们说过,纵向优化是对硬件使用者最友好的,横向优化则对硬件使用者提出了更高的要求,也就是说软件架构要适配。
单Shard集群是有限的,但Shard数量是无限的,Mongo理论上能够提供近乎无限的空间,能够不断的横向扩容。那么现在唯一要解决的就是怎么去把用户数据存到这些Shard里?
首先,要选一个字段(或者多个字段组合也可以)用来做Key,这个Key可以是你任意指定的一个字段。我们现在就是要使用这个Key来,通过某种策略算出发往哪个Shard上。这个策略叫做:Sharding Strategy,也就是分片策略。
分片切分后的数据块称为
chunk,一个分片后的集合会包含多个chunk,每个chunk位于哪个分片Shard则记录在Config Server(配置服务器)上。分片策略则由分片键ShardKey+分片算法ShardStrategy组成。
我们把Sharding Key作为输入,按照特点的Sharding Strategy计算出一个值,值的集合形成了一个值域,我们按照固定步长去切分这个值域,每一个片叫做Chunk,每个Chunk出生的时候就和某个Shard绑定起来,这个绑定关系存储在配置中心里。
所以,我们看到MongoDB的用Chunk再做了一层抽象层,隔离了用户数据和Shard的位置,用户数据先按照分片策略算出落在哪个Chunk上,由于Chunk某一时刻只属于某一个Shard,所以自然就知道用户数据存到哪个Shard了。
Sharding模式下数据写入过程:
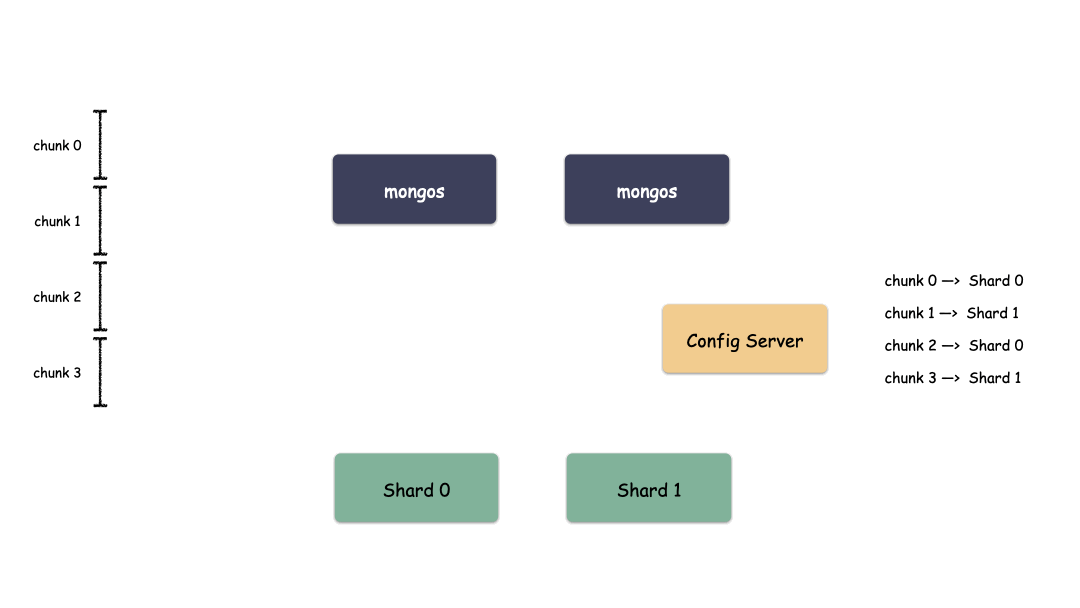
Sharding模式下数据读取过程:

通过上图我们也看出来了,mongos作为路由模块其实就是寻路的组件,写的时候先算出用户key属于哪个Chunk,然后找出这个Chunk属于哪个Shard,最后把请求发给这个Shard,就能把数据写下去。读的时候也是类似,先算出用户key属于哪个Chunk,然后找出这个Chunk属于哪个Shard,最后把请求发给这个Shard,就能把数据读上来。
实际情况下,mongos不需要每次都和Config Server交互,大部分情况下只需要把Chunk的映射表cache一份在mongos的内存,就能减少一次网络交互,提高性能。
为什么要多一层 Chunk 这个抽象?
为了灵活,因为一旦是用户数据直接映射到Shard上,那就相当于是用户数据和底下的物理位置绑定起来了,这个万一Shard空间已经满了,怎么办?
存储不了呀,又不能存储到其他地方去。有同学就会想了,那我可以把这个变化的映射记录下来呀,记录下来理论上行得通,但是每一个用户数据记录一条到Shard的映射,这个量级是非常大的,实际中没有可行性。
而现在多了一层Chunk空间,就灵活了。用户数据不再和物理位置绑定,而是只映射到Chunk上就可以了。如果某个Shard数据不均衡,那么可以把Chunk空间分裂开,迁走一半的数据到其他Shard,修改下Chunk到Shard的映射,Chunk到Shard的映射条目很少,完全Hold住,并且这种均衡过程用户完全不感知。
讲回Sharding Strategy是什么?本质上Sharding Strategy是形成值域的策略而已,MongoDB支持两种Sharding Strategy:
【1】Hashed Sharding的方式
【2】Range Sharding的方式
Hashed Sharding: 把Key作为输入,输入到一个Hash函数中,计算出一个整数值,值的集合形成了一个值域,我们按照固定步长去切分这个值域,每一个片叫做Chunk,这里的Chunk则就是整数的一段范围而已。
假设集合根据x字段来分片,x的取值范围为[minKey, maxKey](x为整型,这里的minKey、maxKey为整型的最小值和最大值),将整个取值范围划分为多个chunk,每个chunk(默认配置为64MB)
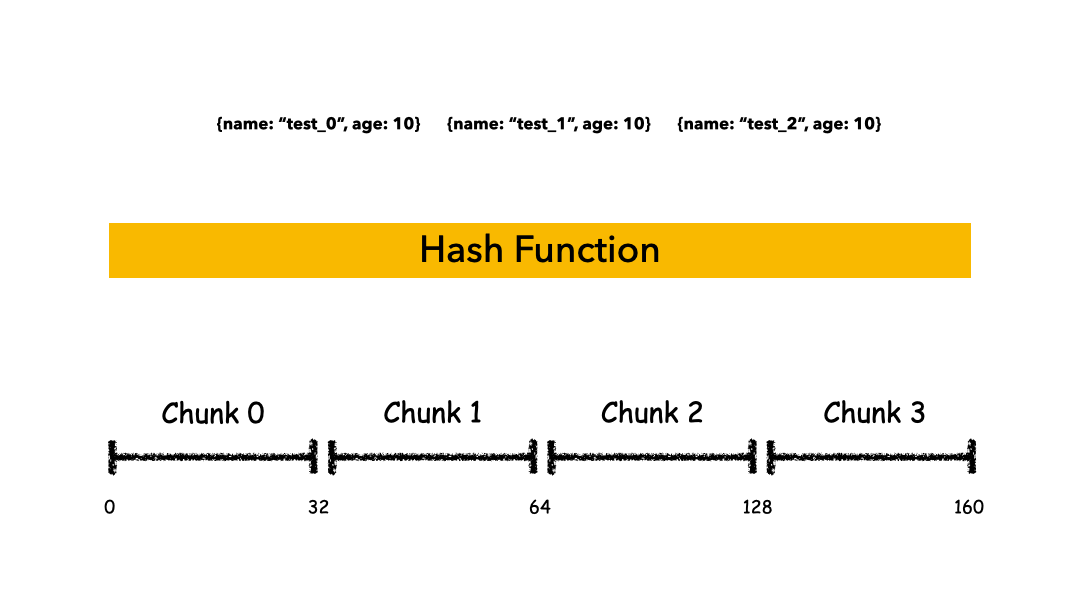
优点: 计算速度快、均衡性好,纯随机;
缺点: 正因为纯随机,排序列举的性能极差,比如你如果按照name这个字段去列举数据,你会发现几乎所有的Shard都要参与进来;
Range Sharding: Range的方式本质上是直接用Key本身来做值,形成的Key Space 。
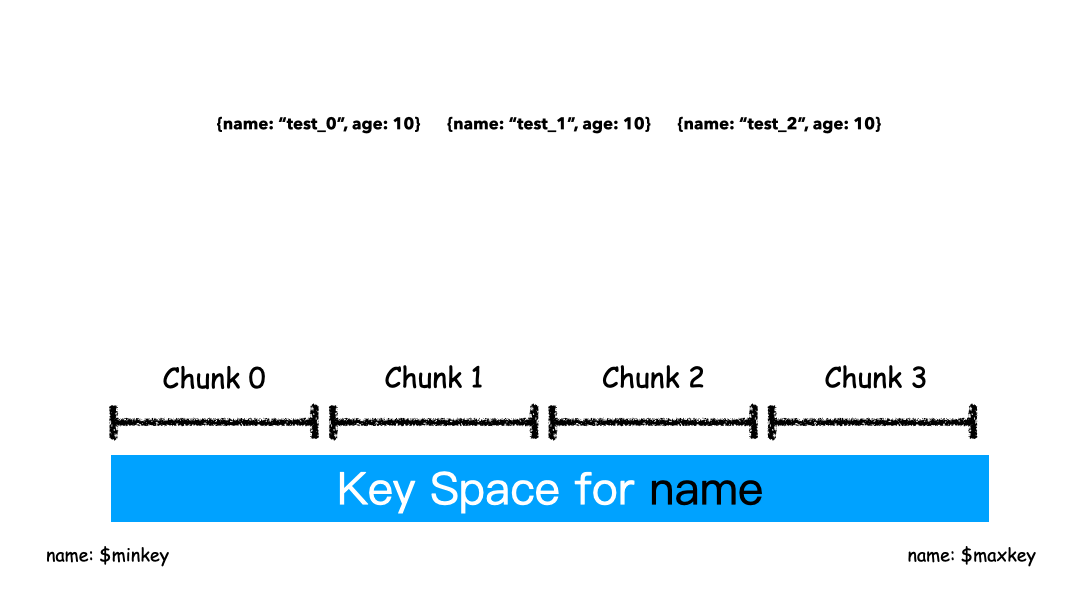
如上图例子,Sharding Key选为name这个字段,对于test_0,test_1,test_2这样的key排序就是挨着的,所以就全都分配在一个Chunk里。
这
3条Docuement大概率是在一个Chunk上,因为我们就是按照Name来排序的。
优点: 对排序列举场景非常友好,因为数据本来就是按照顺序依次放在Shard上的,排序列举的时候,顺序读即可,非常快速;
缺点: 容易导致热点,举个例子,如果Sharding Key都有相同前缀,那么大概率会分配到同一个Shard上,就盯着这个Shard写,其他Shard空闲的很,却帮不上忙;
为什么说Sharding模式不仅是容量问题得到解决,可用性也进一步提升?
因为Shard(Replica Set)集群个数多了,即使一个或多个Shard不可用,Mongo集群对外仍可以 提供读取和写入服务。因为每一个 Shard都有一个Primary节点,都可以提供写服务,可用性进一步提升。
如何保证均衡
数据是分布在不同的chunk上的,而chunk则会分配到不同的分片上,那么如何保证分片上的 数据chunk是均衡的呢?
在真实的场景中,会存在下面两种情况:
【1】全预分配: chunk的数量和shard都是预先定义好的,比如10个shard,存储1000个chunk,那么每个shard分别拥有100个chunk。此时集群已经是均衡的状态(这里假定)
【2】非预分配: 这种情况则比较复杂,一般当一个chunk太大时会产生分裂split,不断分裂的结果会导致不均衡;或者动态扩容增加分片时,也会出现不均衡的状态。 这种不均衡的状态由集群均衡器进行检测,一旦发现了不均衡则执行chunk数据的搬迁达到均衡。
MongoDB的数据均衡器运行于Primary Config Server配置服务器的主节点上,而该节点也同时会控制Chunk数据的搬迁流程。
对于数据的不均衡是根据两个分片上的Chunk个数差异来判定的,阈值对应表如下:
| Number of chuncks | Migration Threshold |
|---|---|
| < 20 | 2 |
| 20 - 79 | 4 |
| > 80 | 8 |
MongoDB的数据迁移对集群性能存在一定影响,这点无法避免,目前的规避手段只能是将 均衡窗口 对齐到业务闲时段。 |
参考文献:链接


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)