

MongoDB 架构
优质博文:IT-BLOG-CN
一、存储数据格式
MongoDB作为主流的NoSQL数据库之一,使用面向文档的数据存储方式,将数据以JSON和BSON的方式存储在磁盘中。BSON Binary JSON是一种基于JSON的二级制序列化格式,用于MongoDB存储文档并进行远程过程调用,作为网络数据交互的一种存储形式,类似于Protocol Buffer和Thrift。BSON是一种schema-less的存储形式,它的优点是灵活性高,但它的缺点是空间利用率不是很理想
一个Collection包含一个JSON和BSON文档:
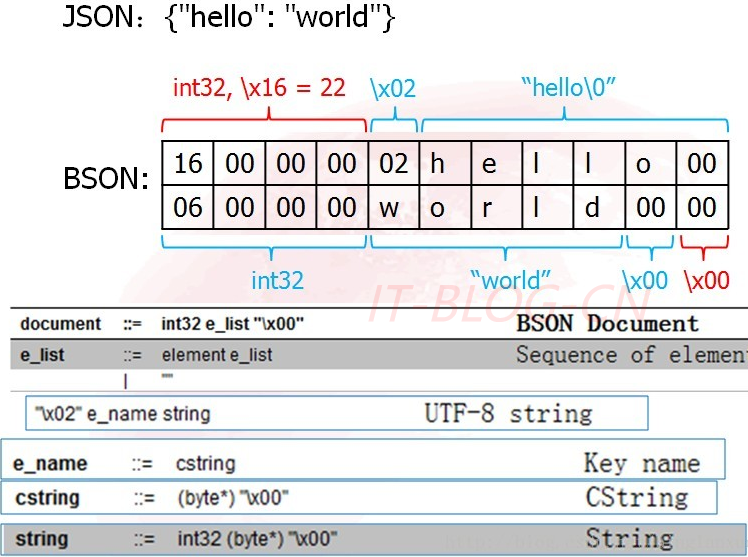
JSON和BSON之间最主要的区别如下表所示:
JSON |
BSON |
|---|---|
JSON是javascript对象表示法 |
BSON是二进制JSON |
| 是一种轻量级的、基于文本的、开放的数据交换格式 | 是一种二进制序列化文档格式 |
JSON包含一些基本数据类型,如字符串、数字、布尔值、空值 |
除了支持JSON中的类型外,BSON还包含一些额外的数据类型,例如日期Date、二进制BinData等 |
AnyDB、Redis等数据库将数据存储为JSON格式 |
MongoDB中将数据存储为BSON格式 |
| 主要用于传输数据 | 主要用于存储数据 |
| 没有响应的编码和解码技术 | 有专用的编码和解码技术 |
如果想从JSON文件中读取指定信息,需要遍历整个数据 |
在BSON中,可以使用索引跳过到指定内容 |
JSON格式不需要解析,因为它是人类可读的 |
BSON需要解析,因为它是二进制的 |
JSON是对象和数组的组合,其中对象是键值对的集合,而数组是元素的有序列表 |
BSON是二进制数据,在其中可以存储一些附加信息,例如字符串长度、对象类型等 |
二、架构视图
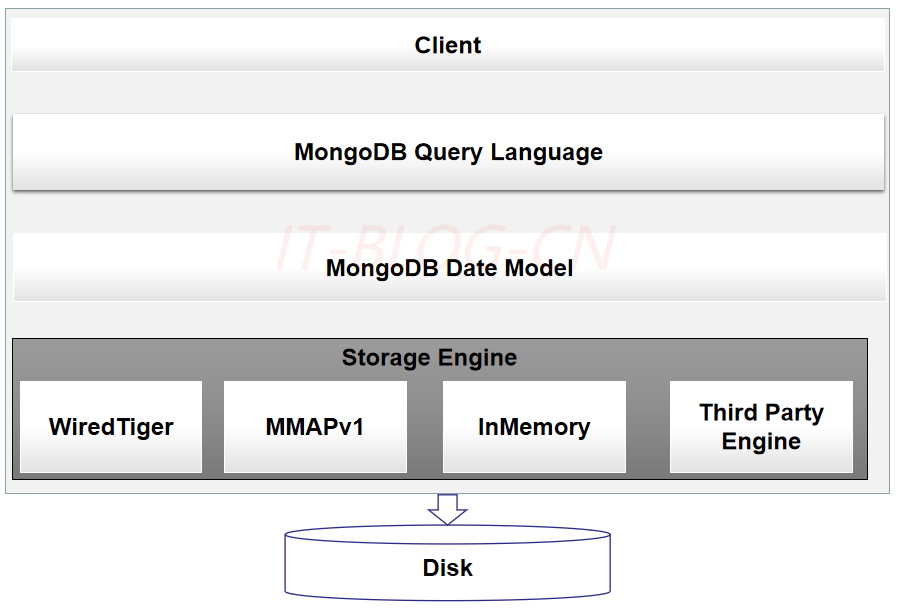
MongoDB与MySQL中的架构相似,底层都使用了可插拔的存储引擎以满足用户的不同需要。用户可以根据程序的数据特征选择不同的存储引擎,在最新版本的MongoDB中使用了WiredTiger作为默认的存储引擎,WiredTiger提供了不同粒度的并发控制和压缩机制,能够为不同种类的应用提供了最好的性能和存储率。
在存储引擎上层的就是MongoDB的数据模型和查询语言了,由于MongoDB对数据的存储与RDBMS:Relational Database Management System有较大的差异,所以它创建了一套不同的数据模型和查询语言。虽然MongoDB查询语言非常强大,支持的功能也很多,同时也是可编程的,不过其中包含的内容非常繁杂、API设计也不是非常优雅,所以还是需要一些学习成本的,对于长时间使用MySQL的开发者肯定会有些不习惯。
数据模型Data Model:
【1】内嵌: 内嵌的方式指的是把相关联的数据保存在同一个文档结构之中。MongoDB的文档结构允许一个字段或者一个数组内的值作为一个嵌套的文档。通常如下场景选择内嵌:
■ 数据对象之间有包含关系,一般是数据对象之间有一对多或者一对一的关系。
■ 需要经常一起读取的数据。
■ 有map-reduce/aggregation需求的数据放在一起,这些操作都只能操作单个collection。
【2】引用: 引用方式通过存储数据引用信息来实现两个不同文档之间的关联,应用程序可以通过解析这些数据引用来访问相关数据。通常如下场景选择内嵌引用:
■ 当内嵌数据会导致很多数据的重复,并且读性能的优势又不足于覆盖数据重复的弊端。
■ 需要表达比较复杂的多对多关系的时候。
■ 大型层次结果数据集嵌套不要太深。
三、存储引擎
存储引擎是MongoDB的核心组件,负责管理数据如何存储在硬盘和内存上。MongoDB支持的存储引擎有:MMAPv1、WiredTiger、InMemory。
InMemory存储引擎用于将数据只存储在内存中,只将少量的元数据meta-data和诊断日志Diagnostic存储到硬盘文件中,由于不需要Disk的IO操作,就能获取所需的数据,InMemory存储引擎大幅度降低了数据查询的延迟Latency。从mongodb3.2开始默认的存储引擎是WiredTiger,3.2版本之前的默认存储引擎是MMAPv1,mongodb4.x版本不再支持MMAPv1存储引擎。
storage:
journal:
enabled: true
dbPath: /data/mongo/
#是否一个库一个文件夹
directoryPerDB: true
##数据引擎
engine: wiredTiger
##WT引擎配置
WiredTiger:
engineConfig:
##WT最大使用cache(根据服务器实际情况调节)
cacheSizeGB: 2
##是否将索引也按数据库名单独存储
directoryForIndexes: true
journalCompressor:none (默认snappy)
##表压缩配置
collectionConfig:
blockCompressor: zlib (默认snappy,还可选none、zlib)
##索引配置
indexConfig:
prefixCompression: true
WiredTiger优势
【1】文档空间分配方式: WiredTiger使用的是BTree存储; MMAPV1线性存储需要Padding;
【2】并发级别:WiredTiger文档级别锁; MMAPV1引擎使用表级锁;
【3】数据压缩:snappy默认和zlib,相比MMAPV1无压缩空间节省数倍;
【4】内存使用:WiredTiger可以指定内存的使用大小,从MongoDB 3.2版本开始,WiredTiger内部缓存的使用量,默认值是:1GB或60%of RAM - 1GB ,取两值中的较大值(不同版本会有区别,具体参考版本配置文件说明);文件系统缓存的使用量不固定, MongoDB自动使用系统空闲的内存;
【5】Cache使用:WT引擎使用了二阶缓存WiredTiger Cache,File System Cache来保证Disk上的数据的最终一致性。而MMAPv1只有journal日志;
【6】文档级别的锁: MongoDB在执行写操作时, WiredTiger在文档级别进行并发控制,就是说,在同一时间,多个写操作能够修改同一个集合中的不同文档;当多个写操作修改同一个文档时,必须以序列化方式执行;这意味着,如果该文档正在被修改,其他写操作必须等待,直到在该文档上的写操作完成之后,其他写操作相互竞争,获胜的写操作在该文档上执行修改操作;
【7】检查点机制: 类似关系数据库的CheckPoint,在Checkpoint操作开始时, WiredTiger提供指定时间点point-in-time的数据库快照Snapshot,该Snapshot呈现的是内存中数据的一致性视图。当向Disk写入数据时,WiredTiger将Snapshot中的所有数据以一致性方式写入到数据文件中。同样MongoDB借助Journal日志文件也可以还原数据;
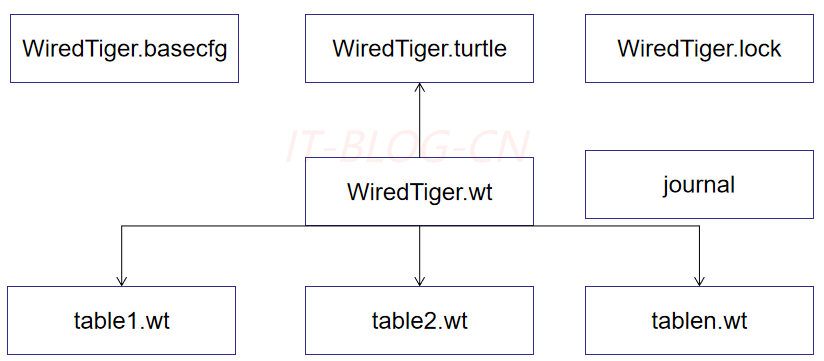
【1】WiredTiger.basecfg: 存储基本配置信息,与ConfifigServer有关系;
【2】WiredTiger.lock: 定义锁操作;
【3】table*.wt: 存储各张表的数据;
【4】WiredTiger.wt: 存储table*的元数据;
【5】WiredTiger.turtle: 存储WiredTiger.wt的元数据;
【6】journal: 存储WAL(Write Ahead Log);
WiredTiger存储引擎实现原理
Transport Layer是处理请求的基本单位。Mongo有专门的listener线程,每次有连接进来,listener会创建一个新的线程conn负责与客户端交互,它把具体的查询请求交给network线程,真正到数据库里查询由TaskExecutor来进行。

写请求:WiredTiger的写操作会默认写入Cache,并持久化到WAL (Write Ahead Log),每60s或Log文件达到2G做一次checkpoint(当然我们也可以通过在写入时传入j: true的参数强制journal文件的同步,writeConcern: { w: , j: , wtimeout: })产生快照文件。WiredTiger初始化时,恢复至最新的快照状态,然后再根据WAL恢复数据,保证数据的完整性。
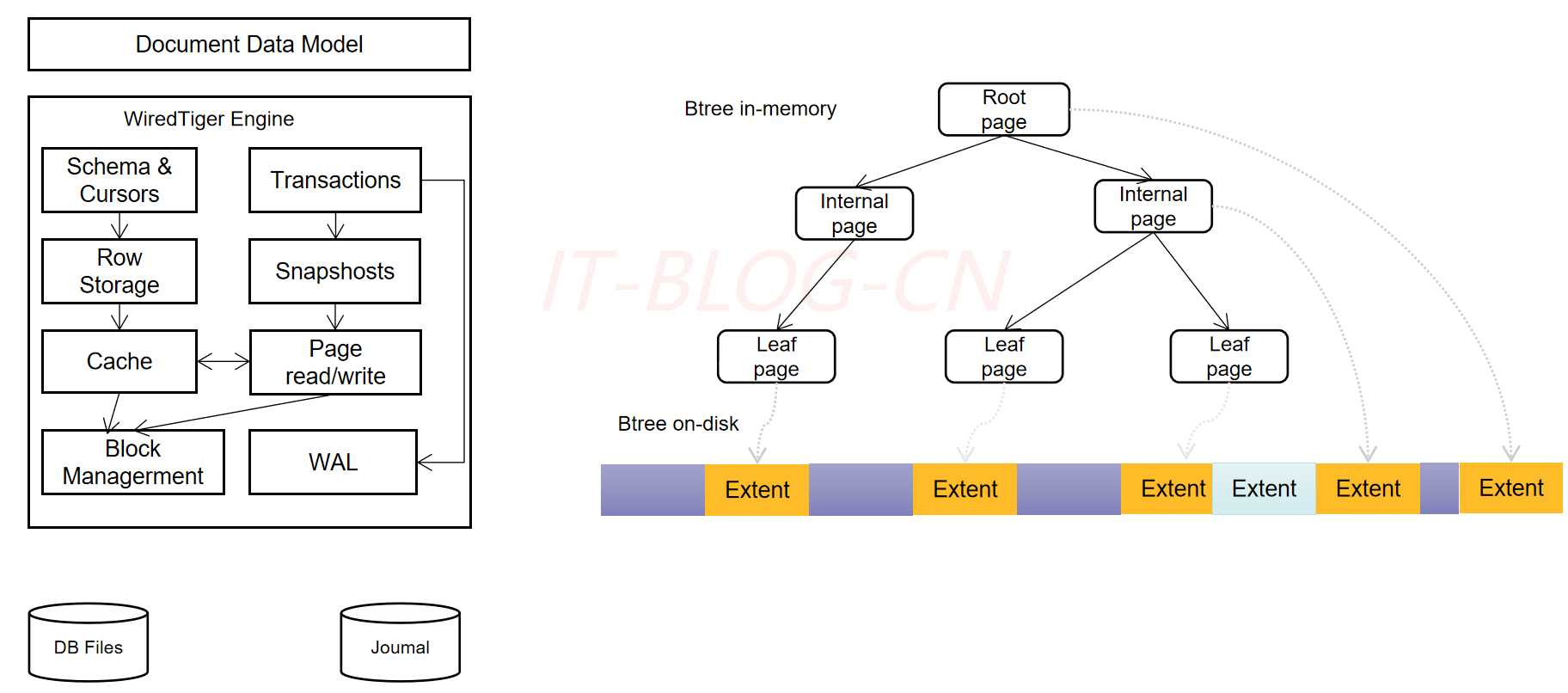
Cache是基于BTree的,节点是一个page,rootpage是根节点,internal page是中间索引节点,leaf page真正存储数据,数据以page为单位读写。
WiredTiger采用Copy on write的方式管理写操作insert、update、delete,写操作会先缓存在cache里,持久化时,写操作不会在原来的leaf page上进行,而是写入新分配的page,每次checkpoint都会产生一个新的rootpage。
checkpoint流程:
【1】对所有的table进行一次checkpoint,每个table的checkpoint的元数据更新至WiredTiger.wt
【2】对WiredTiger.wt进行checkpoint,将该tablecheckpoint的元数据更新至临时文件WiredTiger.turtle.set
【3】将WiredTiger.turtle.set重命名为WiredTiger.turtle
【4】上述过程如果中间失败,WiredTiger在下次连接初始化时,首先将数据恢复至最新的快照状态,然后根据WAL恢复数据,以保证存储可靠性
Journaling:在数据库宕机时,为保证MongoDB中数据的持久性,MongoDB使用了Write Ahead Logging向磁盘上的journal文件预先进行写入。除了journal日志,MongoDB还使用检查点checkpoint来保证数据的一致性,当数据库发生宕机时,我们就需要checkpoint和journal文件协作完成数据的恢复工作。
【1】在数据文件中查找上一个检查点的标识符;
【2】在journal文件中查找标识符对应的记录;
【3】重做对应记录之后的全部操作;
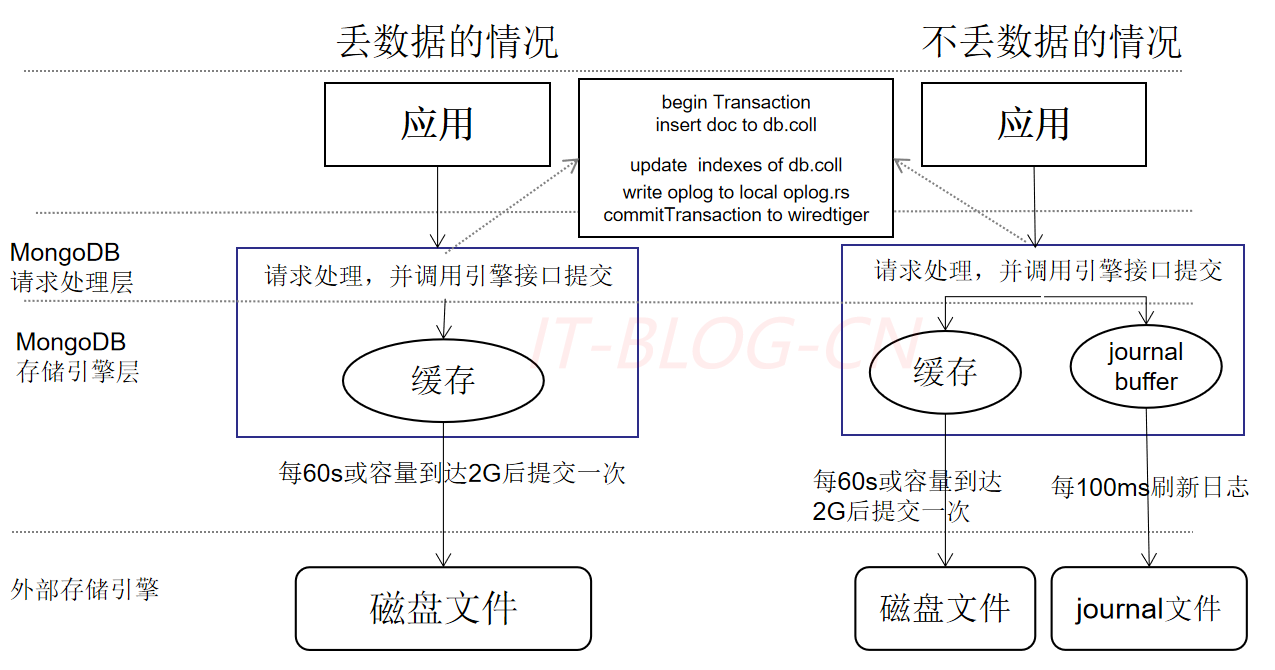
丢数据的情况: 写入数据时,引擎内部是先将数据存在内存中,每隔60s或内存存储容量达到2G后提交一次到磁盘中,因此在这60s期间如果机器宕机,则有极大的可能性会丢失数据
不丢数据的情况: 写入数据时,引擎内部是先将数据存在内存中,同时也会写一份操作日志到内存中,该日志会每个100ms持续化到磁盘文件,这种日志成为Journaling。Journaling类似于关系数据库中的事务日志。Journaling能够使MongoDB数据库由于意外故障后快速恢复。MongoDB2.4版本后默认开启了Journaling日志功能,mongod实例每次启动时都会检查journal日志文件看是否需要恢复。由于提交journal日志会产生写入阻塞,所以它对写入的操作有性能影响,但对于读没有影响。
四、写入策略
MongoDB的写入策略有多种方式,写入策略是指当客户端发起写入请求后,数据库什么时候给应答,MongoDB有三种处理策略:客户端发出去的时候,服务器收到请求的时候,服务器写入磁盘的时候。
【1】Unacknowledged:客户端发出请求丢到socket的时候就收到响应,这个时候客户端不需要等服务器的应答,但是的本地的驱动还是尽可能的通知客户端网络的异常,这和客户端操作系统的配置有关。
【2】Acknowledged:这种方式客户端发送接口会等待服务器给的确认,这种方式一定能确保服务器收到了客户端的请求,并且当服务器能够异常时,响应客户端。
【3】Journaled:Journaled方式相比Acknowledged的方式是要保证服务器端已经写入到硬盘文件了。对于Acknowledged的方式有可能服务收到请求数据相应客户端后的一瞬间当机了,这个数据就丢失了,但是对于Journaled方式,服务器保证写入到磁盘后再相应客户端,即使当机了,也不会导致数据丢失。
【4】Replica Acknowledged:这个方式和Acknowledged是一样的意思,适用于Replica sets模式。Acknowledged模式下只有一台机器收到了请求就返回了,对于复制集模式有多台机器的情况,可以要求有多台机器收到写入请求后再相应客户端。这种更安全,但是导致了客户端耗时增加,所以要结合自己的场景设置合适的策略。
可以通过下面的方式设置默认的策略,majority表示多数节点写入成功后才相应客户端,也可以替换成具体的数子,比如w:2表示至少写入2个节点才返回。wtimeout表示超时时间,还有一个参加j可以设置true,false表示是否是写入日志才返回。
cfg = rs.conf()
cfg.settings.getLastErrorDefaults = { w: "majority", wtimeout: 5000 }
rs.reconfig(cfg)
也可以通过客户端来指定具体的策略,如下: 至少要写入两个节点,超时时间是5s
db.products.insert(
{ item: "envelopes", qty : 100, type: "Clasp" },
{ writeConcern: { w: 2, wtimeout: 5000 } }
)
如果复制集是3台机器,写入两台机器,流程如下:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类