


Nacos 实现 AP+CP原理[Raft 算法 NO]
来源于网络
一、什么是 Raft算法
Raft 适用于一个管理日志一致性的协议,相比于 Paxos 协议 Raft 更易于理解和去实现它。为了提高理解性,Raft 将一致性算法分为了几个部分,包括领导选取(leader selection)、日志复制(log replication)、安全(safety),并且使用了更强的一致性来减少了必须需要考虑的状态。
Raft算法将 Server划分为3种状态,或者也可以称作角色:
【1】Leader:负责 Client交互和 log复制,同一时刻系统中最多存在1个。
【2】Follower:被动响应请求RPC,从不主动发起请求RPC。
【3】Candidate:一种临时的角色,只存在于 Leader的选举阶段,某个节点想要变成 Leader,那么就发起投票请求,同时自己变成 Candidate。如果选举成功,则变为 Candidate,否则退回为 Follower
状态或者说角色的流转如下:

在 Raft中,问题分解为:领导选取、日志复制、安全和成员变化。
复制状态机通过复制日志来实现
日志:每台机器保存一份日志,日志来自于客户端的请求,包含一系列的命令
状态机:状态机会按顺序执行这些命令
一致性模型:分布式环境下,保证多机的日志是一致的,这样回放到状态机中的状态是一致的
Raft算法选主流程
Raft中有 Term的概念,Term类比中国历史上的朝代更替,Raft 算法将时间划分成为任意不同长度的任期(term)。

选举流程
1、Follower增加当前的term,转变为 Candidate。
2、Candidate投票给自己,并发送RequestVote RPC给集群中的其他服务器。
3、收到 RequestVote的服务器,在同一 term中只会按照先到先得投票给至多一个Candidate。且只会投票给 log至少和自身一样新的Candidate。
关于Raft更详细的描述,可以查看这里,从分布式一致性到共识机制(二)Raft算法
二、Nacos中的 CP一致性
Spring Cloud Alibaba Nacos 在 1.0.0 正式支持 AP 和 CP 两种一致性协议,其中 CP一致性协议实现,是基于简化的 Raft 的 CP 一致性。
如何实现 Raft算法
Nacos server在启动时,会通过 RunningConfig.onApplicationEvent()方法调用 RaftCore.init()方法。
启动选举

1 public static void init() throws Exception { 2 3 Loggers.RAFT.info("initializing Raft sub-system"); 4 5 // 启动Notifier,轮询Datums,通知RaftListener 6 executor.submit(notifier); 7 8 // 获取Raft集群节点,更新到PeerSet中 9 peers.add(NamingProxy.getServers()); 10 11 long start = System.currentTimeMillis(); 12 13 // 从磁盘加载Datum和term数据进行数据恢复 14 RaftStore.load(); 15 16 Loggers.RAFT.info("cache loaded, peer count: {}, datum count: {}, current term: {}", 17 peers.size(), datums.size(), peers.getTerm()); 18 19 while (true) { 20 if (notifier.tasks.size() <= 0) { 21 break; 22 } 23 Thread.sleep(1000L); 24 System.out.println(notifier.tasks.size()); 25 } 26 27 Loggers.RAFT.info("finish to load data from disk, cost: {} ms.", (System.currentTimeMillis() - start)); 28 29 GlobalExecutor.register(new MasterElection()); // Leader选举 30 GlobalExecutor.register1(new HeartBeat()); // Raft心跳 31 GlobalExecutor.register(new AddressServerUpdater(), GlobalExecutor.ADDRESS_SERVER_UPDATE_INTERVAL_MS); 32 33 if (peers.size() > 0) { 34 if (lock.tryLock(INIT_LOCK_TIME_SECONDS, TimeUnit.SECONDS)) { 35 initialized = true; 36 lock.unlock(); 37 } 38 } else { 39 throw new Exception("peers is empty."); 40 } 41 42 Loggers.RAFT.info("timer started: leader timeout ms: {}, heart-beat timeout ms: {}", 43 GlobalExecutor.LEADER_TIMEOUT_MS, GlobalExecutor.HEARTBEAT_INTERVAL_MS); 44 }
在 init方法主要做了如下几件事:
- 获取 Raft集群节点 peers.add(NamingProxy.getServers());
- Raft集群数据恢复 RaftStore.load();
- Raft选举 GlobalExecutor.register(new MasterElection());
- Raft心跳 GlobalExecutor.register(new HeartBeat());
- Raft发布内容
- Raft保证内容一致性
选举流程
其中,raft集群内部节点间是通过暴露的 Restful接口,代码在 RaftController 中。RaftController控制器是 Raft集群内部节点间通信使用的,具体的信息如下
1 POST HTTP://{ip:port}/v1/ns/raft/vote : 进行投票请求 2 3 POST HTTP://{ip:port}/v1/ns/raft/beat : Leader向Follower发送心跳信息 4 5 GET HTTP://{ip:port}/v1/ns/raft/peer : 获取该节点的RaftPeer信息 6 7 PUT HTTP://{ip:port}/v1/ns/raft/datum/reload : 重新加载某日志信息 8 9 POST HTTP://{ip:port}/v1/ns/raft/datum : Leader接收传来的数据并存入 10 11 DELETE HTTP://{ip:port}/v1/ns/raft/datum : Leader接收传来的数据删除操作 12 13 GET HTTP://{ip:port}/v1/ns/raft/datum : 获取该节点存储的数据信息 14 15 GET HTTP://{ip:port}/v1/ns/raft/state : 获取该节点的状态信息{UP or DOWN} 16 17 POST HTTP://{ip:port}/v1/ns/raft/datum/commit : Follower节点接收Leader传来得到数据存入操作 18 19 DELETE HTTP://{ip:port}/v1/ns/raft/datum : Follower节点接收Leader传来的数据删除操作 20 21 GET HTTP://{ip:port}/v1/ns/raft/leader : 获取当前集群的Leader节点信息 22 23 GET HTTP://{ip:port}/v1/ns/raft/listeners : 获取当前Raft集群的所有事件监听者 24 RaftPeerSet
心跳机制
Raft中使用心跳机制来触发 Leader选举。心跳定时任务是在 GlobalExecutor 中,通过 GlobalExecutor.register(new HeartBeat())注册心跳定时任务,具体操作包括:
- 重置 Leader节点的heart timeout、election timeout;
- sendBeat()发送心跳包
1 public class HeartBeat implements Runnable { 2 @Override 3 public void run() { 4 try { 5 6 if (!peers.isReady()) { 7 return; 8 } 9 10 RaftPeer local = peers.local(); 11 local.heartbeatDueMs -= GlobalExecutor.TICK_PERIOD_MS; 12 if (local.heartbeatDueMs > 0) { 13 return; 14 } 15 16 local.resetHeartbeatDue(); 17 18 sendBeat(); 19 } catch (Exception e) { 20 Loggers.RAFT.warn("[RAFT] error while sending beat {}", e); 21 } 22 23 } 24 }
简单说明了下Nacos中的Raft一致性实现,更详细的流程,可以下载源码,查看 RaftCore 进行了解。源码可以通过以下地址检出:链接

三、Nacos AP 实现
AP协议:Distro协议。Distro是阿里巴巴的私有协议,目前流行的 Nacos服务管理框架就采用了 Distro协议。Distro 协议被定位为 临时数据的一致性协议 :该类型协议, 不需要把数据存储到磁盘或者数据库 ,因为临时数据通常和服务器保持一个session会话, 该会话只要存在,数据就不会丢失 。
Distro 协议保证写必须永远是成功的,即使可能会发生网络分区。当网络恢复时,把各数据分片的数据进行合并。
Distro 协议具有以下特点:
-
专门为了注册中心而创造出的协议;
-
客户端与服务端有两个重要的交互,服务注册与心跳发送;
-
客户端以服务为维度向服务端注册,注册后每隔一段时间向服务端发送一次心跳,心跳包需要带上注册服务的全部信息,在客户端看来,服务端节点对等,所以请求的节点是随机的;
-
客户端请求失败则换一个节点重新发送请求;
-
服务端节点都存储所有数据,但每个节点只负责其中一部分服务,在接收到客户端的“写”(注册、心跳、下线等)请求后,服务端节点判断请求的服务是否为自己负责,如果是,则处理,否则交由负责的节点处理;
-
每个服务端节点主动发送健康检查到其他节点,响应的节点被该节点视为健康节点;
-
服务端在接收到客户端的服务心跳后,如果该服务不存在,则将该心跳请求当做注册请求来处理;
-
服务端如果长时间未收到客户端心跳,则下线该服务;
-
负责的节点在接收到服务注册、服务心跳等写请求后将数据写入后即返回,后台异步地将数据同步给其他节点;
-
节点在收到读请求后直接从本机获取后返回,无论数据是否为最新。
Distro协议服务端节点发现使用寻址机制来实现服务端节点的管理。在 Nacos中,寻址模式有三种:
单机模式:StandaloneMemberLookup
文件模式:FileConfigMemberLookup -- 利用监控 cluster.conf文件的变动实现节点的管理。核心代码如下: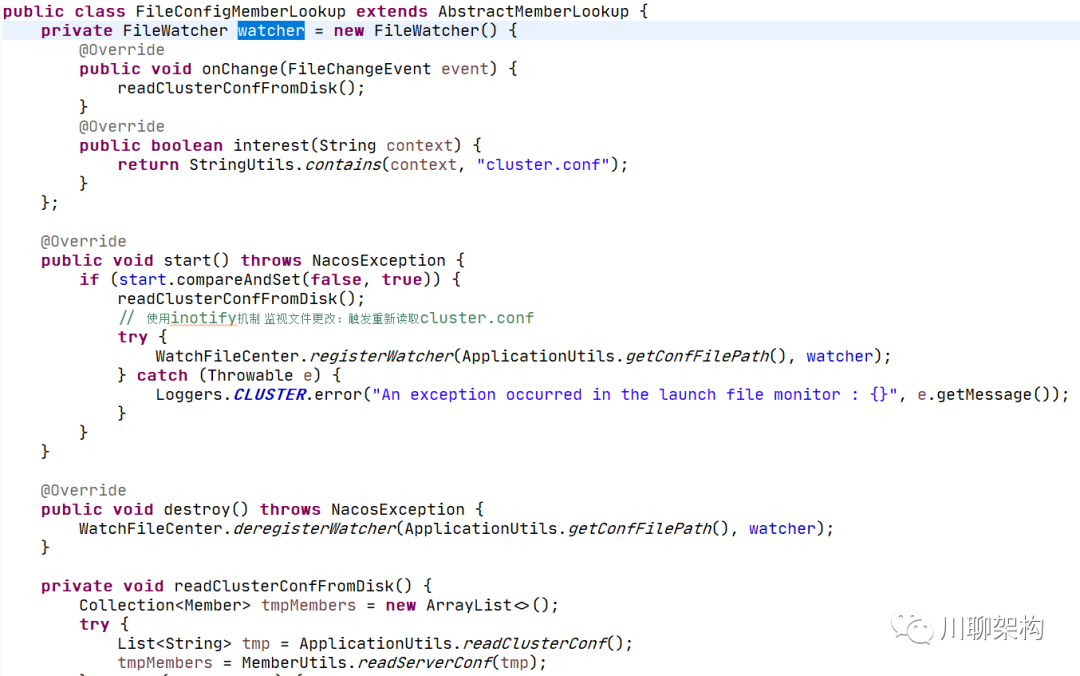
服务器模式:AddressServerMemberLookup – 使用地址服务器存储节点信息,服务端节点定时拉取信息进行管理

核心代码:

初始全量同步
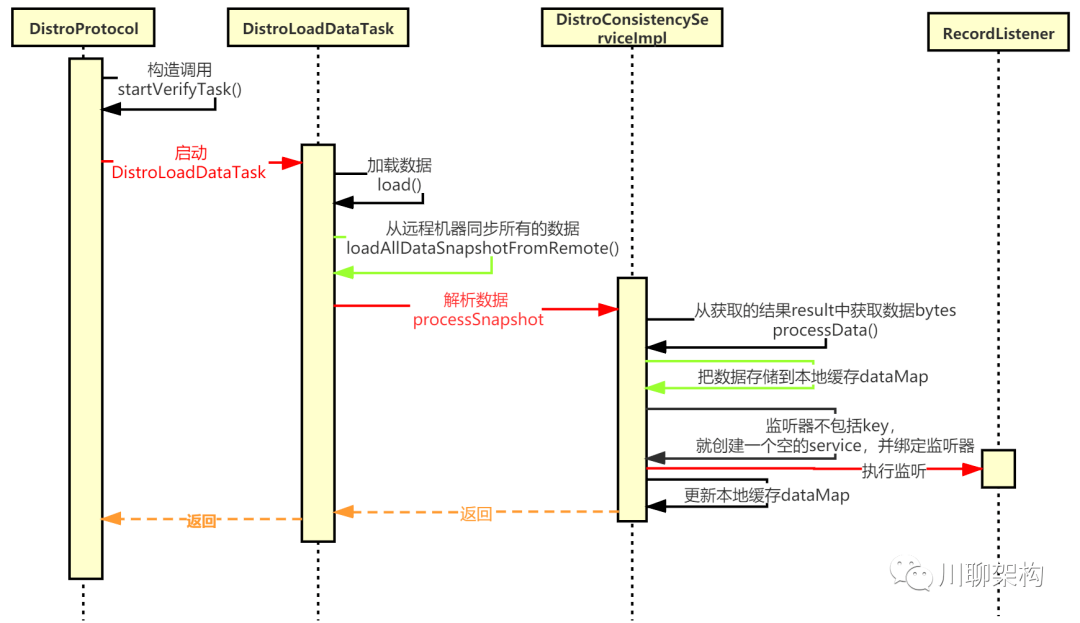
Distro协议节点启动时会从其他节点全量同步数据。在 Nacos中,整体流程如下:
-
启动一个定时任务线程 DistroLoadDataTask加载数据,调用 load()方法加载数据
-
调用 loadAllDataSnapshotFromRemote()方法从远程机器同步所有的数据
-
从 namingProxy代理获取所有的数据data
-
构造 http请求,调用 httpGet方法从指定的 server获取数据
-
从获取的结果 result中获取数据 bytes
-
-
处理数据 processData
-
从data反序列化出 datumMap
-
把数据存储到 dataStore,也就是本地缓存 dataMap
-
监听器不包括 key,就创建一个空的 service,并且绑定监听器
-
-
监听器 listener执行成功后,就更新 data store
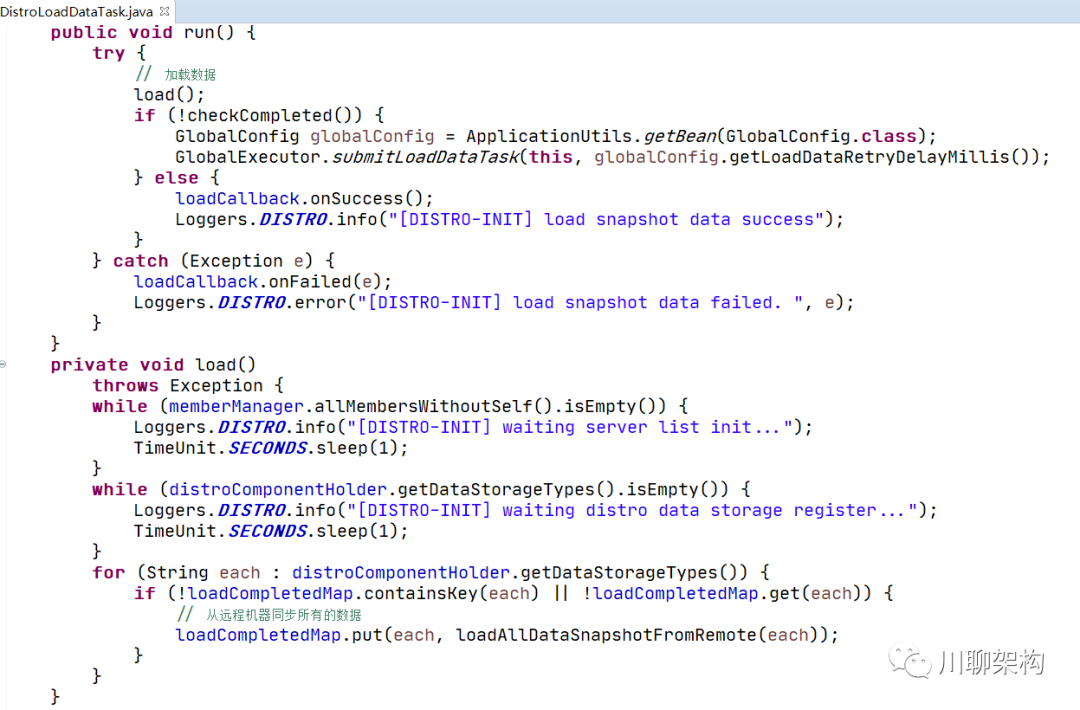
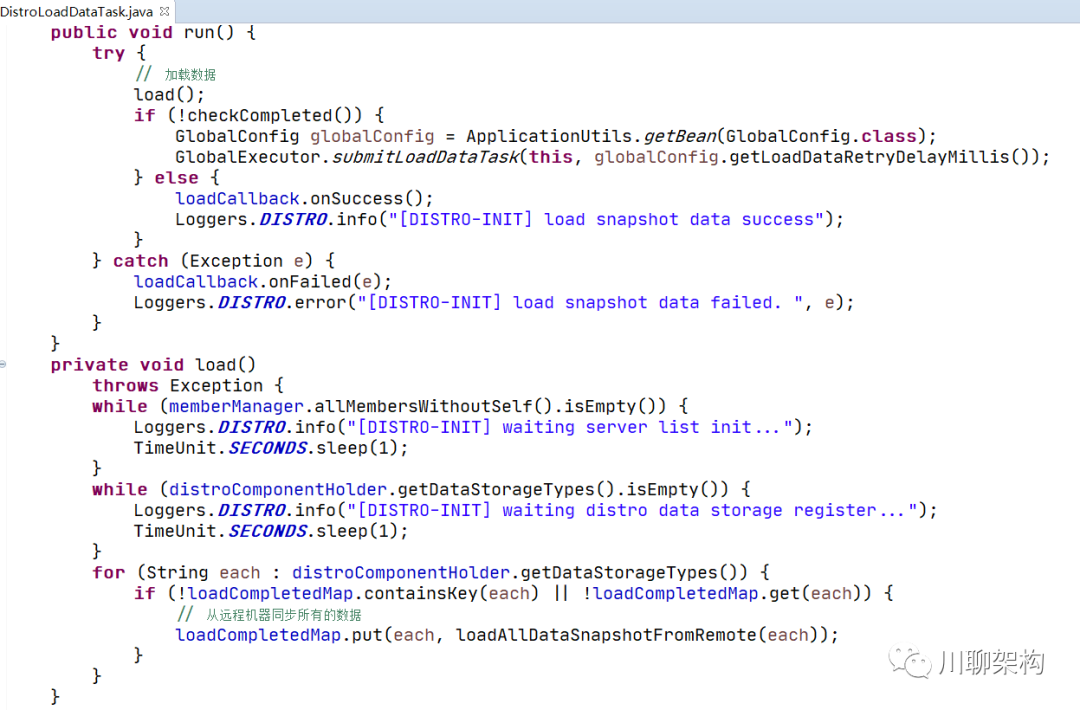
核心代码如下:


增量同步
新增数据使用异步广播同步:
-
DistroProtocol 使用 sync() 方法接收增量数据
-
向其他节点发布广播任务
-
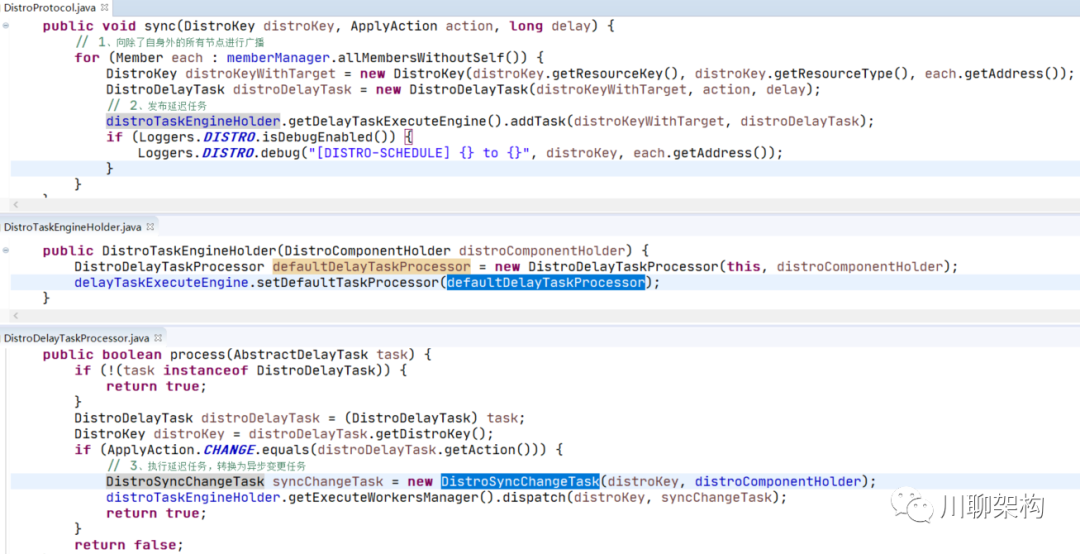
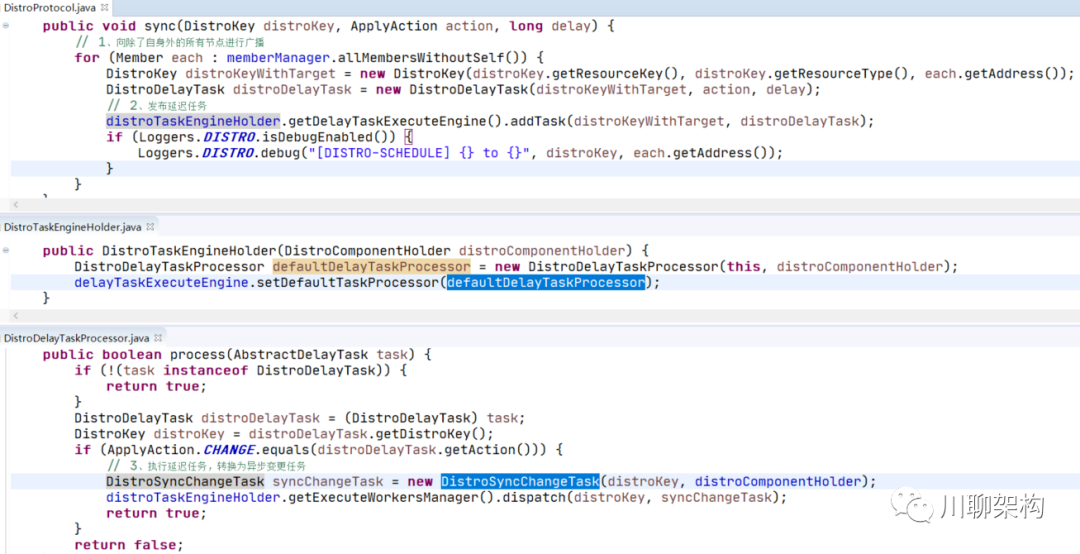
调用 distroTaskEngineHolder 发布延迟任务
-
-
调用 DistroDelayTaskProcessor.process() 方法进行任务投递:将延迟任务转换为异步变更任务
-
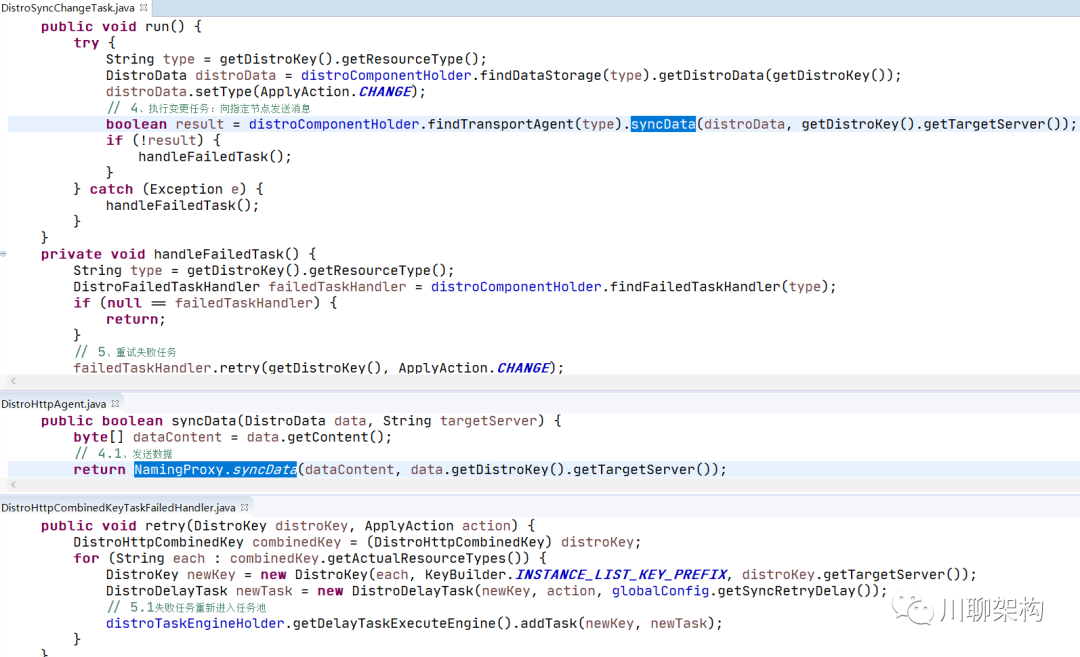
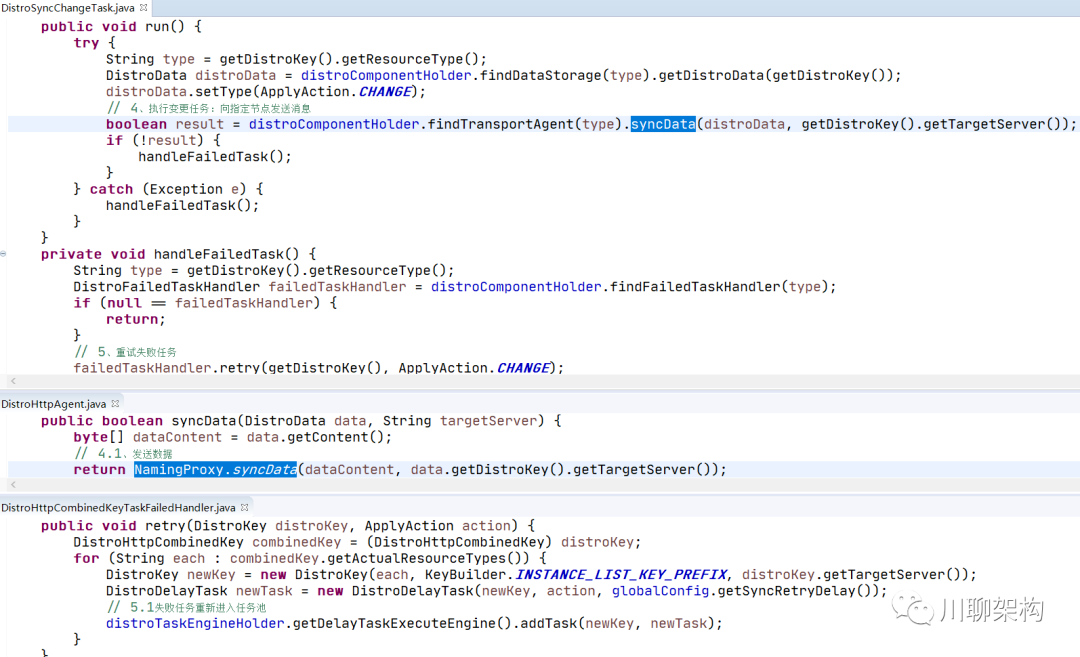
执行变更任务 DistroSyncChangeTask.run() 方法:向指定节点发送消息
-
调用 DistroHttpAgent.syncData() 方法发送数据
-
调用 NamingProxy.syncData() 方法发送数据
-
-
异常任务调用 handleFailedTask() 方法进行处理
-
调用 DistroFailedTaskHandler 处理失败任务
-
调用 DistroHttpCombinedKeyTaskFailedHandler 将失败任务重新投递成延迟任务。
-
核心代码如下:
Distro协议是阿里的私有协议,但是对外开源框架只有Nacos。所有我们只能从Nacos中一窥Distro协议。Distro协议是一个比较简单的最终一致性协议。整体由节点寻址、数据全量同步、异步增量同步、定时上报client所有信息、心跳探活其他节点等组成。
本文中的Nacos源码版本为Nacos 1.3.2 ,属于优化过的源码,抽象出一致性协议抽象接口,和JRaft共用节点寻址模式。
Distro协议是阿里的私有协议,但是对外开源框架只有Nacos。所有我们只能从Nacos中一窥Distro协议。Distro协议是一个比较简单的最终一致性协议。整体由节点寻址、数据全量同步、异步增量同步、定时上报client所有信息、心跳探活其他节点等组成。
本文中的Nacos源码版本为Nacos 1.3.2 ,属于优化过的源码,抽象出一致性协议抽象接口,和JRaft共用节点寻址模式。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现