

Java 序列化的缺点
Java 提供的对象输入流(ObjectInputStream)和输出流(ObjectOutputStream),可以直接把 Java 对象作为可存储的字节数据写入文件,也可以传输到网络上。对于程序员来说,基于 JDK 默认的序列化机制可以避免操作底层的字节数组,从而提高开发效率。Java 序列化的主要目的是网络传输和对象持久化。
一、无法跨语言
无法跨语言,是 Java 序列化最致命的问题。对于跨进程的服务调用,服务提供者可能是 Java 意外的其他语言,当我们需要和异构语言交互时,Java 序列化就难以胜任
由于 Java 序列化技术是 Java 语言内部的私有协议,其他语言并不支持,对于用户来说它完全是个黑盒子。对于 Java 序列化后的字节数组,别的语言无法进行反序列化,这就严重阻碍了它的应用。
事实上,目前几乎所有流行的 Java RCP 通信框架,都没有使用 Java 序列化作为编解码框架,原因就在于它无法跨语言,而这些 RPC 框架往往需要支持跨语言调用。
二、序列化后的码流太大
【1】通过一个实例看下 Java 序列化后的字节数组大小。如下 UserInfo 对象是实现了序列化接口的对象,并生成了默认的序列号:serialVersionUID = 1L。说明 UserInfo 对象可以通过 JDK 默认的序列化机制进行序列化和反序列化。并创建了一个与之比较码流大小的方法 codeC ,此方法基于 ByteBuffer 的通用二进制编解码技术对 UserInfo 对象进行编码,编码结果也是 byte 数组。
【序列化 ID 问题】:两个客户端 A 和 B 试图通过网络传递对象数据,A 端将对象 C 序列化为二进制数据再传给 B,B 反序列化得到 C。
问题:C 对象的全类路径假设为 com.yintong.UserInfo,在 A 和 B 端都有这么一个类文件,功能代码完全一致。也都实现了 Serializable 接口,但是反序列化时总是提示不成功。
解决:虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID = 1L)。清单 1 中,虽然两个类的功能代码完全一致,但是序列化 ID 不同,他们无法相互序列化和反序列化。
【2】下面是测试程序,先调用两种编码接口对 UserInfo 进行编码,然后分别打印两者编码后的流大小进行对比。
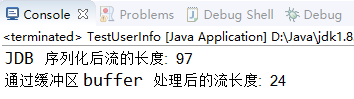
1 public class TestUserInfo { 2 3 public static void main(String[] args) throws Exception { 4 UserInfo info = new UserInfo(101, "zheng zhao xiang"); 5 //JDK 序列化流程 6 ByteArrayOutputStream bos = new ByteArrayOutputStream(); 7 ObjectOutputStream oos = new ObjectOutputStream(bos); 8 oos.writeObject(info); 9 oos.flush(); 10 oos.close(); 11 byte[] b = bos.toByteArray(); 12 System.out.println("JDB 序列化后流的长度: "+b.length); 13 bos.close(); 14 System.out.println("通过缓冲区 buffer 处理后的流长度: "+info.codeC().length); 15 } 16 }
【3】测试结果如下:采用 JDK 序列化机制编码后的二进制数组大小是通过缓冲区处理后的 4 倍。
![]()
三、序列化性能太低
【1】下面从序列化的性能角度看下 JDK 的表现如何。将之前的例子进行修改。对 UserInfo 中的 codeC 方法改造如下:
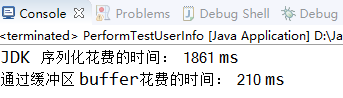
【2】对 Java 序列化和二进制编码分别进行性能测试,编码 100万次,然后统计消耗的总时间:
【3】结果展示:结果非常令人惊讶,Java 序列化的性能只有二进制编码的 11% 左右,可见原生序列化的性能很差。
![]()
四、结论
无论是序列化后的码流大小,还是序列化的性能,JDK 默认的序列化机制表现都很差。因此,我们通常不会选择 Java 序列化作为远程跨节点调用的编解码框架。而是使用业界提供的很多优秀的编解码框架,它们在克服了 JDK 默认的序列化框架缺点的基础上,还增加了很多亮点。例如:Google 的 Protobuf、Facebook 的 Thrift 和 JBoss 的 Marshalling 等等,我后期都会学习和整理相关的博文。

![]()
----架构师资料,关注公众号获取----

