



线程池的实现原理
系统性学习,移步IT-BLOG
线程池做的工作主要是控制运行的线程数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数超过了最大数量超出数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
什么是线程池
线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL。线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
Java 中的线程池是运用场景最多的并发框架,几乎所有需要异步或并发执行任务的程序都可以使用线程池。在开发过程中,合理地使用线程池能够带来4个好处:
1)、降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
2)、提高响应速度。当任务达到时,任务可以不需要等到线程创建就能立即执行。
3)、提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是,要做到合理利用线程池,必须对其实现原理了如指掌。
4)、提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
线程池解决的问题是什么
线程池解决的核心问题就是资源管理问题。在并发环境下,系统不能够确定在任意时刻中,有多少任务需要执行,有多少资源需要投入。这种不确定性将带来以下若干问题:
【1】频繁申请/销毁资源和调度资源,将带来额外的消耗,可能会非常巨大;
【2】对资源无限申请缺少抑制手段,易引发系统资源耗尽的风险;
【3】系统无法合理管理内部的资源分布,会降低系统的稳定性;
为解决资源分配这个问题,线程池采用了“池化”(Pooling)思想。池化,顾名思义,是为了最大化收益并最小化风险,而将资源统一在一起管理的一种思想。在计算机领域中的表现为:统一管理IT资源,包括服务器、存储、和网络资源等等。除了线程池,还有其他比较典型的几种使用策略包括:
【1】内存池(Memory Pooling):预先申请内存,提升申请内存速度,减少内存碎片。
【2】连接池(Connection Pooling):预先申请数据库连接,提升申请连接的速度,降低系统的开销。
【3】实例池(Object Pooling):循环使用对象,减少资源在初始化和释放时的昂贵损耗。
线程池核心设计与实现
Java中的线程池核心实现类是 ThreadPoolExecutor,还有一个工具类 Excutors。本章基于JDK 1.8的源码来分析Java线程池的核心设计与实现。我们首先来看一下 ThreadPoolExecutor的UML类图,了解下ThreadPoolExecutor的继承关系。
![]()
![]()
ThreadPoolExecutor 实现的顶层接口是Executor,顶层接口 Executor提供了一种思想:将任务提交和任务执行进行解耦。用户无需关注如何创建线程,如何调度线程来执行任务,用户只需提供 Runnable对象,将任务的运行逻辑提交到执行器(Executor)中,由 Executor框架完成线程的调配和任务的执行部分。
ExecutorService接口增加了一些能力:(1)扩充执行任务的能力,补充可以为一个或一批异步任务生成 Future的方法;(2)提供了管控线程池的方法,比如停止线程池的运行。
AbstractExecutorService则是上层的抽象类,将执行任务的流程串联了起来,保证下层的实现只需关注一个执行任务的方法即可。最下层的实现类 ThreadPoolExecutor实现最复杂的运行部分。
ThreadPoolExecutor将会一方面维护自身的生命周期,另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
线程池生命周期
线程池运行的状态,并不是用户显式设置的,而是伴随着线程池的运行,由内部维护。线程池内部使用一个32 位的整数维护两个值:运行状态(runState)和线程数量 (workerCount) 两个参数维护在一起,其中高 3位用于存放线程池状态,低 29 位表示线程数(CAPACITY)。如下代码所示:
ThreadPoolExecutor 的运行状态有5种,其生命周期转换如下入所示:
![]()
【1】RUNNING:能接收新提交的任务,也能处理阻塞队列中的任务;
【2】SHUTDOWN:关闭状态,不再接收新提交的任务,但却可以继续处理阻塞队列中已保存的消息;
【3】STOP:不接受任务,也不处理阻塞队列中的消息,会中断正在执行的任务;
【4】TIDYING:所有的任务已终止,workerCount(有效线程数为0);
【5】TERMINATED:在 terminated()方法执行完后进入该状态;
线程池处理任务的流程
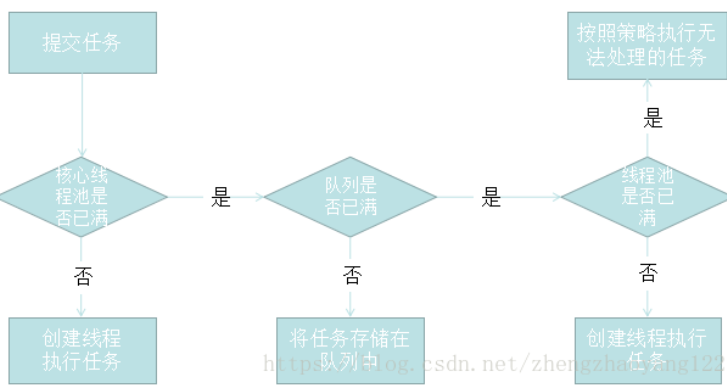
ThreadPoolExecutor是如何运行,如何同时维护线程和执行任务的呢?线程池处理任务的流程图如下:
![]() 、
、
【从图中可以看出,当提交一个任务到线程池时,线程池处理流程如下】:
1)、首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在 RUNNING的状态下执行任务。
2)、线程池判断核心线程池里的线程数是否已达到上限,如果没有,就创建新线程执行任务。如果已达到上限,进入步骤3。
3)、线程池判断工作队列是否已满。如果工作队列没满,就将任务存储在队列中。如果队列满了,则进入步骤4。
4)、线程池判断线程池中的线程数是否已达上限,没有就创建新线程执行任务,如果已满则根据饱和策略处理此任务。默认的处理方式是直接抛异常。
ThreadPoolExecutor 执行 execute() 方法的示意图,如下所示:

![]()
ThreadPoolExecutor 执行 execute 方法分下面4中情况:
1)、如果当前运行的线程少于 corePoolSize,则创建新线程来执行任务(执行需要获取全局锁)。
2)、如果运行的线程等于或大余 corePoolSize,则将任务加入 BlockingQueue。
3)、如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务(需要获取全局锁)
4)、如果创建新线程将使当前运行的线程超过 maximumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecutor() 方法。
ThreadPoolExecutor 采取上述步骤的总体设计思路,是为了在执行 execute() 方法时,尽可能地避免获取全局锁(那将会是一个严重的可伸缩瓶颈)。在 ThreadPoolExecutor 完成预热之后(当前运行线程数大于等于 corePoolSize),几乎所有的 execute()方法调用都是执行步骤2,而步骤2不需要获取全局锁。
源码分析
通过上面流程图的分析直观的了解了线程池的工作原理,下面就通过源码看看是如何实现的,方法如下:
我们下面看一下 addWorker是如何创建线程的:
代码中的 retry: 就是一个标记,标记对一个循环方法的操作(continue和break)处理点,功能类似于goto,所以 retry一般都是伴随着 for循环出现,retry:标记的下一行就是for循环,在for循环里面调用continue(或者break)再紧接着 retry标记时,就表示从这个地方开始执行 continue(或者break)操作
这里主要是列举了几个条件不能创建新的 worker的情况:
【1】线程池状态大于 SHUTDOWN,其实也就是 STOP, TIDYING, 或 TERMINATED;
【2】firstTask != null;
【3】workQueue.isEmpty() 如果线程池处于 SHUTDOWN,但是 firstTask 为 null,且 workQueue 非空,那么是允许创建 worker 的;
如果传入的 core参数是 true代表使用核心线程数 corePoolSize 作为创建线程的界限,也就说创建这个线程的时候,如果线程池中的线程总数已经达到 corePoolSize,那么不能响应这次创建线程的请求;如果是false,代表使用最大线程数 maximumPoolSize 作为界限;
如果 CAS失败并不是因为有其他线程在操作导致的,那么就直接在里层循环继续下一次的循环就好了,如果是因为其他线程的操作,导致线程池的状态发生了变更,如有其他线程关闭了这个线程池,那么需要回到外层的 for循环;
如果是小于 SHUTTDOWN 那就是 RUNNING,则继续往下继续,或者状态是 SHUTDOWN但是传入的 firstTask为空,代表继续处理队列中的任务
addWorkerFailed:将 workers集合里面的 worker移除,然后 count减1,
工作线程
线程池创建线程时,会将线程封装成工作线程 Worker,Worker是继承 AQS对象的,在创建 Worker对象的时候会传入一个Runnable对象,并设置 AQS的 state状态为 -1,并从线程工厂中新建一个线程。调用 thread.start方法会调用到 Worker的 run方法中。
Worker 在执行完任务后,还会循环获取工作队列里的任务来执行。我们可以从Worker 类的 run()方法里看到这点。
Worker的 run方法会调用到 ThreadPoolExecutor的 runWorker方法
传入一个 Worker首先去校验 firstTask是不是 null,如果是那么就调用 getTask方法从 workQueue队列里面获取,然后判断一下当前的线程是否需要中断,如需要的话执行钩子方法,然后调用 task的 run方法执行 task;
如果 while循环里面 getTask获取不到任务的话,就结束循环调用 processWorkerExit方法执行关闭;如果是异常原因导致的 while循环退出,那么会调用 processWorkerExit并传入为 true;
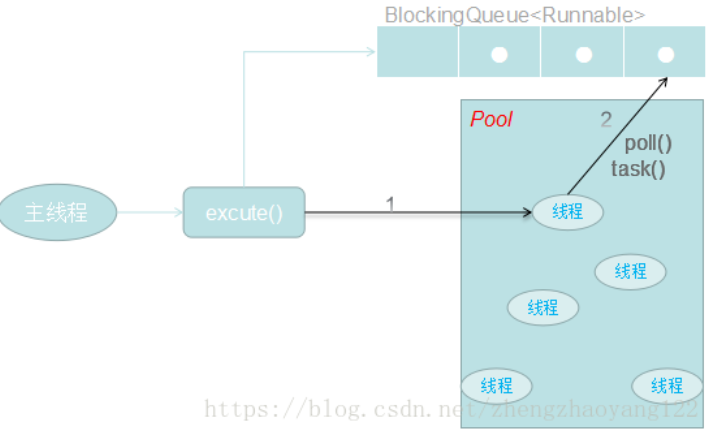
ThreadPoolExecutor 中线程执行任务的示意图如下:
![]()
线程池中的线程执行分为两种情况,如下:
【1】在 execute() 方法中创建一个线程时,会让这个线程执行当前任务。
【2】这个线程完成1的任务后,会反复从BlockingQueue 获取任务来执行。
【Java 线程池中的核心线程是如何被重复利用的】:看一下 runWorker()方法的代码,有一个 while循环,当执行完 firstTask后task==null了,那么就会执行判断条件 (task = getTask()) != null,我们假设这个条件成立的话,那么这个线程就不止只执行一个任务了,可以执行多个任务了,也就实现了重复利用了。答案呼之欲出了,接着看 getTask()方法。
从以上代码可以看出,getTask()的作用:如果当前活动线程数大于核心线程数,当去缓存队列中取任务的时候,如果缓存队列中没任务了,则等待 keepAliveTime的时长,此时还没任务就返回null,这就意味着 runWorker()方法中的 while循环会被退出,其对应的线程就要销毁了,也就是线程池中少了一个线程了。因此只要线程池中的线程数大于核心线程数就会这样一个一个地销毁这些多余的线程。如果当前活动线程数小于等于核心线程数,同样也是去缓存队列中取任务,但当缓存队列中没任务了,就会进入阻塞状态,直到能取出任务为止,因此这个线程是处于阻塞状态的,并不会因为缓存队列中没有任务了而被销毁。这样就保证了线程池有N个线程是活的,可以随时处理任务,从而达到重复利用的目的。
上面方法返回 null有如下几种情况:
【1】当前状态是 SHUTDOWN并且 workQueue队列为空;
【2】当前状态是 STOP及以上;
【3】池中有大于 maximumPoolSize 个 workers 存在(通过调用 setMaximumPoolSize 进行设置);
processWorkerExit 方法源码:
【1】判断是否是意外退出的,如果是意外退出的话,那么就需要把 WorkerCount–;
【2】加完锁后,同步将 completedTaskCount进行增加,表示总共完成的任务数,并且从 WorkerSet中将对应的 Worker移除;
【3】调用tryTemiate,进行判断当前的线程池是否处于 SHUTDOWN状态,判断是否要终止线程;
【4】判断当前的线程池状态,如果当前线程池状态比 STOP大的话,就不处理;
【5】判断是否是意外退出,如果不是意外退出的话,那么就会判断最少要保留的核心线程数,如果allowCoreThreadTimeOut被设置为true的话,那么说明核心线程在设置的KeepAliveTime之后,也会被销毁;
【6】如果最少保留的 Worker数为0的话,那么就会判断当前的任务队列是否为空,如果任务队列不为空的话而且线程池没有停止,那么说明至少还需要1个线程继续将任务完成;
【7】判断当前的 Worker是否大于min,也就是说当前的 Worker总数大于最少需要的 Worker数的话,那么就直接返回,因为剩下的 Worker会继续从 WorkQueue中获取任务执行;
【8】如果当前运行的 Worker数比当前所需要的 Worker数少的话,那么就会调用 addWorker,添加新的 Worker,也就是新开启线程继续处理任务;
![]()
----关注公众号,获取更多内容----

