

MySQL 高级查询截取分析
慢日志分析流程如下:
【1】观察(至少跑一天),看看生产慢 SQL 情况。
【2】开启慢查询日志,设置阈值,比如对超过5秒的 SQL 语句进行抓取。
【3】explain+慢 SQL 分析。
【4】show profile 查询慢 SQL 在 MySQL 中的执行细节和生命周期情况。
【5】运维经理 or DBA 对数据库参数进行调优。
一、查询优化
【1】永远小表驱动大表(存在连接问题),类似嵌套循环 Nested Loop。例如:当 B表的数据集小于 A表时,用 In 优于 Exist。因为先执行B表在执行A表。
SELECT * FROM A WHERE ID IN (SELECT ID FROM B)
当 A表的数据集小于 B表的时候,用 Existsl 优于 In。因为先执行 A表在执行 B表。
SELECT * FROM A WHERE EXISTS (SELECT 1 FROM B WHERE B.ID = A.ID)
该语法可以理解为将主查询的数据,放到子查询中做条件验证,根据验证的结果(TURE OR FLASE)来解决主查询的数据结果是否保留。
【2】order by 关键字优化:尽量使用 Index 方式进行排序,效率高因为 MySQL 是通过扫描索引进行排序,避免使用fileSort(文件排序) 方式排序。使用 index 的前提:
■ order by 语句使用了索引最左前缀规则;
■ where 子句与 order by 子句条件列组合满足索引最左列;
【filesort 有两种算法】:如果不在索引列上,MySQL就要启动双路排序和单路排序。
■ 双路排序:MySQL4.1 之前使用的是双路排序,字面意思就是两次扫面磁盘,最终得到数据。读取指针和 order by 所含的列,对他们进行排序,然后扫描已经排好的列表,按照列表中排好的值重新从列表中读取对应的数据输出。一句话,从磁盘读取排序字段,在 buffer 进行排序,在从磁盘读取其他字段。
■ 单路排序:从磁盘读取查询所需要的列,按照 order by 列在 buffer 上对它们进行排序,然后扫描排序中的列输出。它的效率快,避免了二次读取数据。
【结论及引申出的问题】:单路总体上优于双路算法。但是单路算法有问题:当获取的数据的总大小 > sort_buffer 的容量时,就需要多次获取排序(多路),反而不如双路排序高效。
【优化策略】:①、增大 sort_buffer_size 参数的设置。②、增大 max_length_for_sort_data(因为单路排序为将要排序的每一行创建了固定的缓冲区,varchar 列的最大长度是 max_length_for_sort_data 规定的值,而不是排序数据的实际大小)参数的设置。③、当使用 order by 时忌讳使用 select * 查询。
【总结】:![]()
【3】group by 关键字优化:①、group by 实质是先排序再分组,遵循最左前缀法则;
②、无法使用索引列的时候也要增大 sort_buffer_size 参数和 max_length_for_sort_size 参数设置;
③、where 高于 having 能写在 where 限定条件里面的就不要写在 having 限定中;

二、慢查询日志
【1】what 慢查询日志:MySQL 的慢查询日志是 MySQL 提供的一种日志记录,它用来记录在 MySQL 中相应时间超过阈值的语句,具体指运行时间超过 long_query_time 值得 SQL,则会被记录在慢查询日志中。默认值为:10s,通常设置为 2s或 5s;
【2】默认情况下:MySQL 数据库没有开启慢查询日志,需要手动开启。当然,如果不是调优需要的话,一般不建议开启,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件。
show VARIABLES like '%slow_query_log%';
开启:set global slow_query_log = 1; 只对当前数据库生效,如果重启 MySQL 则会失效。如果要永久生效,就必须设置配置文件 my.cnf。在 [mysqlid] 下添加:
slow_query_log=1; slow_query_log_file=/var/lib/mysql/xxx-slow.log
查看设置的阈值时间,在 MySQL 中判断查询时间是否大于阈值时间,大于则记录。
show VARIABLES like '%long_query_time%';
设置阈值时间,修改后需要重新连接或者重开会话才生效。
set global long_query_time=2
可以通过 select sleep(4),进行测试,日志文件内容如下: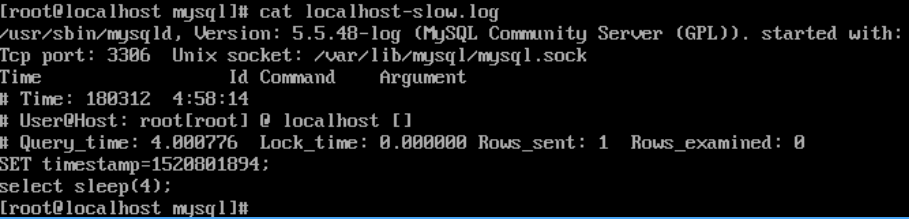
查询当前系统有多少条慢查询记录
show global status like '%slow_queries %';
如果想永久设置 time 在[mysqlid]下:
long_query_time=3; log_output=FILE;
【3】MySQL 分析工具 mysqldumpslow:查看 sql 的帮助信息。常用命令如下:
①、得到返回记录集最多的10条记录:mysqldumpslow -s r -t 10 /var/lib/mysql/xxx.log
②、得到访问次数最多的10个SQL:mysqldumpslow -s c -t 10 /var/lib/mysql/xxx.log
③、得到按照时间排序的前10条含有左连接的查询语句:mysqldumpslow -s t -t 10 -g 'left join' /var/lib/mysql/xxx.log
④、建议使用这些命令的时候结合|和more使用,否则会出现爆屏的情况:mysqldumpslow -s r -t 10 /var/lib/mysql/xxx.log | more
三、批量数据脚本
函数与存储过程的区别:函数有且一个返回值,存储过程可以有0至n个返回值。
【1】设置参数 log_bin_trust_function_creators(当二进制日志启用后,这个变量就会启用。它控制是否可以信任存储函数创建者,不会创建写入二进制日志引起不安全事件的存储函数。如果设置为0(默认值),用户不得创建或修改存储函数,除非它们具有除 CREATE ROUTINE 或 ALTER ROUTINE特权之外的 SUPER 权限。 设置为0还强制使用 DETERMINISTIC 特性或READS SQL DATA或NO SQL特性声明函数的限制。 如果变量设置为1,MySQL不会对创建存储函数实施这些限制。 此变量也适用于触发器的创建)创建函数的时候如果报错:this function has none of DETERMINISTIC......
由于开启慢日志查询也开启了 bin-log,就必须为 function 指定一个参数。查看是否开启:如果未开启则开启如下,如果要长期设置和上面配置一样在配置文件中配置。
show variables like '%log_bin_trust_function_creators%'; set global log_bin_trust_function_creators=1;
【2】创建函数保证每条数据都不同:①、返回随机字符串:
1 DELIMITER $$ 2 CREATE FUNCTION rand_string(n INT) RETURNS(255) 3 BEGIN 4 DECLARE chars_str VARCHAR(100) DEFAULT 'QWERTYUIOPLKJHGFDSAZXCVBNMmnbvcxzasdfghjklpoiuytrewq'; 5 DECLARE return_str DEFALUT ''; 6 DECLARE i INT DEFALUT 0; 7 WHILE i<n DO 8 SET return_str = CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1)); 9 SET i=i+1; 10 END WHILE; 11 RETURN retrun_str; 12 END $$
删除function:drop function xxx;
②、创建存储过程:
1 DELIMITER $$ 2 CREATE PROCEDURE insert_emp(IN start INT(10),IN max_num INT(10)) 3 BEGIN 4 DECALRE i INT DEFAULT 0; 5 SET autocommit = 0; 6 REPEAT 7 SET i = i+1; 8 INSERT INTO emp() VALUES(); 9 UNIT i = max_num 10 END REPEAT; 11 COMMIT 12 END $$
③、调用存储过程
CALL insert_emp(100,10);
四、Show Profile
是 MySQL 提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于 SQL 的调优的测量。默认是关闭状态,并保存最近15次的运行结果。
【分析步骤】:
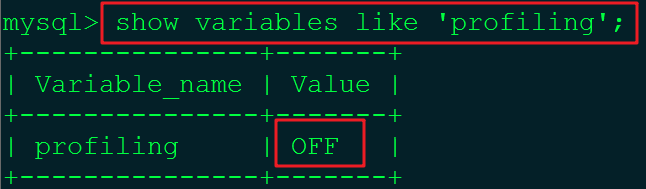
■ 是否支持,看看当前 MySQL 的版本是否支持。show variables like 'profiling';
![]()
■ 打开:set profiling=on;

![]()
■ 运行SQL;
■ 查看结果:show profiles;

![]()
■ 诊断SQL:show profiles cpu,block io for query id号;

![]()
show profile 的常用查询参数:① ALL:显示所有的开销信息。
② BLOCK IO:显示块IO开销。
③ CONTEXT SWITCHES:上下文切换开销。
④ CPU:显示CPU开销信息。
⑤ IPC:显示发送和接收开销信息。
⑥ MEMORY:显示内存开销信息。
⑦ PAGE FAULTS:显示页面错误开销信息。
⑧ SOURCE:显示和 Source_function,Source_file,Source_line相关的开销信息。
⑨ SWAPS:显示交换次数开销信息。
【结论】:①、converting HEAP to MYISAM 查询结果太大,内存不够用了往磁盘上搬了。②、Creating tmp table 创建临时表。③、Copying to tmp table on disk 把内存中临时表复制到磁盘。④、locked。
【Explain 语句分析链接】
五、全局查询日志:(永远不要在生产环境开启此功能)
【1】配置启用:my.cnf 配置文件中。
1 #开启 2 general_log=1 3 #记录日志文件路径 4 general_log_file=/path/logfile 5 #输出格式 6 log_output=FILE
【2】编码:命令:set global general_log=1;set global log_output='TABLE';之后编写的 SQL 语句,将被记录与 MySQL 库中的 general_log 表。查看命令:select * from mysql.general_log;

