



大数据面试——HDFS
一、Hadoop1.0 与 Hadoop2.0的区别

![]()
二、写一个 WordCount 案例
【1】我在安装目录执行 hadoop jar "jar包" wordcount "统计文件目录" "输出目录(一定不要存在,会自动创建)",重点就是 wordcount ,在Linux 中也常常使用 wc 来统计行数,字符个数等。
[root@localhost hadoop-2.7.2]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount data/zzx data/output【2】进入输出目录,查看统计结果
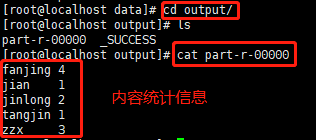
![]()
三、从多个文件 Grep 制定数据
【1】我在安装目录执行 hadoop jar "jar包" grep "统计文件目录" "输出目录(一定不要存在,会自动创建)" "'抓取文件时的规则'"
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'【2】进入输出目录,查看统计结果。统计的是input 文件下所有文件,符合正则的单词的数量。
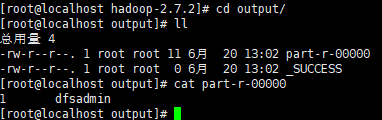
![]()
四、为什么不能一直格式化NameNode,格式化NameNode,要注意什么?
[zzx@hadoop101 hadoop-2.7.2]$ cd data/tmp/dfs/name/current/
[zzx@hadoop101 current]$ cat VERSION
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837
[zzx@hadoop101 hadoop-2.7.2]$ cd data/tmp/dfs/data/current/
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837如上图,DataNode 与 NameNode 的集群ID是相同的。如果格式化NameNode,会产生新的集群id,导致 NameNode和 DataNode的 集群id不同,集群找不到已往数据。就会出现启动了 NameNode 时,DataNode会挂掉。启动了DataNode时,NameNode会挂掉的问题。所以,格式NameNode时,一定要先删除 data数据和 log日志,然后再格式化NameNode。
五、HDFS 文件块大小
HDFS 中的文件在物理上是分块存储(Block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认在 Hadoop2.x版本中是 128M,老版本是 64M。
![]()
HDFS 块大小设置:为什么块的大小不能设置太小,也不能设置太大
【1】HDFS 块设置太小,会增加寻址时间,程序一直在找块的位置;
【2】如果块设置的太大,从磁盘传输数据的时间会明显大于块定位的时间。导致程序在处理块数据时,会非常慢。
总结:HDFS 块的大小设置取决于磁盘传输速率
六、setrep 设置副本数
如果设置了10个副本,但是目前只有三台服务器,如果后续增加了服务器,会怎样?
hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt
![]()
这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
七、HDFS 读数据流程
HDFS的读数据流程,如下图所示:
![]()
【1】客户端通过 Distributed FileSystem向 NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址进行返回。
【2】挑选一台 DataNode(就近原则,然后随机)服务器,请求读取数据。当第一次读取完成之后,才进行第二次块的读取。
【3】DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet为单位来做校验)。
【4】客户端以 Packet为单位接收,先在本地缓存,然后写入目标文件。
八、HDFS 写数据流程
HDFS 文件写入流程图如下:三个模块(客户端、NameNode、DataNode)
![]()
【1】校验:客户端通过 DistributedFileSystem 模块向 NameNode 请求上传文件,NameNode 会检查目标文件是否已经存在,父目录是否存在。
【2】响应:NameNode 返回是否可以上传的信号。
【3】请求 NameNode:客户端对上传的数据根据块进行切片,并请求第一块 Block 上传到哪几个 DataNode 服务器上。
【4】响应 DataNode节点信息:NameNode 根据副本数等信息返回可上传的DataNode节点,例如这里的 dn1,dn2,dn3。
【5】建立通道:客户端通过 FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
【6】DataNode 响应 Client:dn1、dn2、dn3逐级应答客户端。
【7】上传数据到DataNode:客户端开始往 dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以 Packet为单位,dn1收到一个 Packet就会传给 dn2,dn2传给 dn3;dn1每传一个 packet会放入一个应答队列等待应答。
【8】通知 NameNode上传完成:当一个 Block传输完成之后,客户端再次请求 NameNode上传第二个 Block的服务器。
【9】关闭输入输出流。

