



【java并发编程艺术学习】(三)第二章 java并发机制的底层实现原理 学习记录(一) volatile
章节介绍
这一章节主要学习java并发机制的底层实现原理。主要学习volatile、synchronized和原子操作的实现原理。Java中的大部分容器和框架都依赖于此。
Java代码 ==经过编译==》Java字节码 ==通过类加载器==》JVM(jvm执行字节码)==转化为汇编指令==》CPU上执行。
Java中使用的并发机制依赖于JVM的实现和CPU的指令。
volatile初探
volatile是是轻量级的synchronized,它在多处理器开发中保证了共享变量的可见性。可见性的意思就是 当一个线程修改了一个共享变量时候,另一个线程能够读取到这个值。volatile不会引起上下文的切换和调度。(需要具体理解下。。)
CPU相关术语说明:
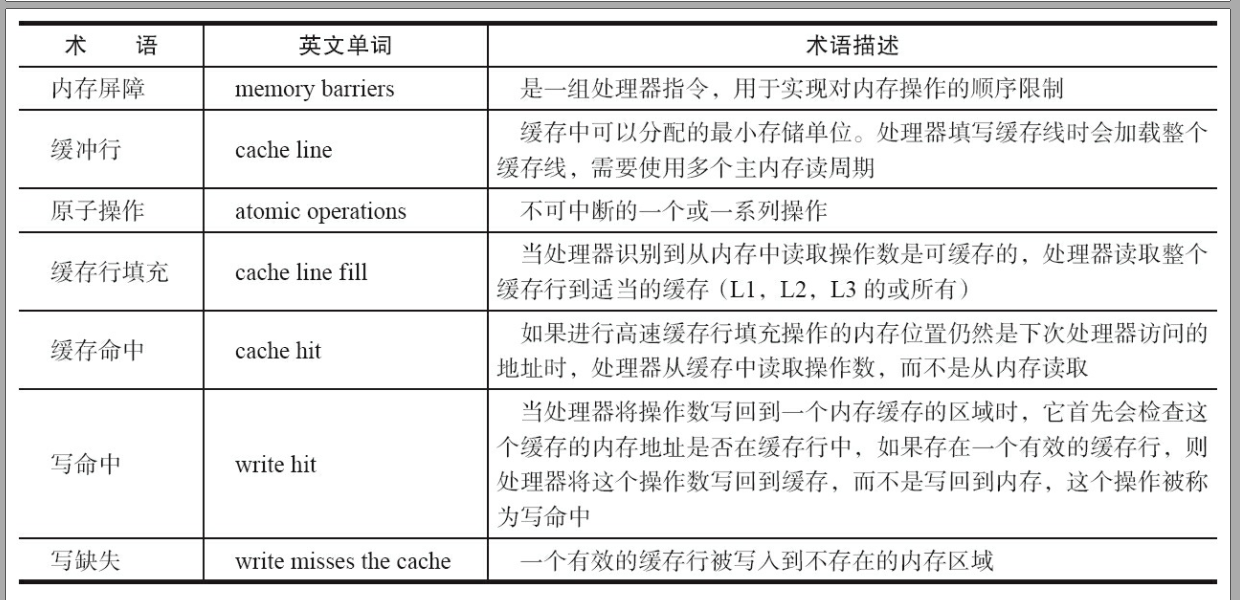
volatile定义:java编程语言允许线程访问共享变量,为了确保共享变量能被准确和一致的更新,线程应该确保通过排它锁单独获得这个变量。Java语言提供了volatile,在某些情况下比锁更加方便。如果一个字段被声明为volatile,Java线程内存模型确保所有线程看到这个变量的值是一致的。
volatile是如何保证可见性的呢?(可以通过汇编指令来查看对volatile进行操作时,cpu会做什么事情)
在对volatile修饰的变量进行写操作时,出现的汇编代码中会加上Lock关键字。Lock前缀的指令在多核处理器中会引发两件事情:(1)将当前处理器缓存行的数据写回到内存;(2)这个写回到内存的操作会使在其他cpu里缓存了该内存地址的数据无效。
具体操作为:如果对声明了volatile的变量进行写操作时,jvm会向处理器发出一条Lock前缀的指令,将这个变量所在缓存行的数据写回到内存。但是,此时虽然将数据写回到内存,但是其他处理器缓存的数据可能还是旧的,这样的话,再执行计算操作就有问题了。
所以在多处理下,为了保证各个处理器的缓存是一致的,就会实现缓存的一致性协议,每个处理器通过嗅探总线上传播的数据来检查自己缓存的值是不是过期了。如果,处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器中的缓存行 设置成无效状态。当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存中。
volatile的使用优化
介绍:Java并发编程大师Doug lea 在jdk7的并发包里新增一个队列集合类LinkedTransferQueue,它在使用volatile变量时,采用追加字节的方式优化队列出队和入队的性能。具体可以看下相关类的源码。
但是,并非有些情况,上述方法是无效的。(1)缓存行非64字节的处理器;(2)共享变量不会被频繁的写。(因为追加字节的方式需要处理器读取更多的字节到高速缓冲区,这本身就带来了一些性能的消耗。如果共享变量不会频繁写的话,锁的几率也非常小,就没必要使用追加字节的方式来避免互相锁定了)。
还有个问题,这种追加字节的方式在Java 7下可能不生效。
下一章节,学习synchronized,期待.....

