#研发解决方案#分布式并行计算调度和管理系统Summoner
郑昀 创建于2015/11/10 最后更新于2015/11/12
关键词:佣金计算、定时任务、数据抽取、数据清洗、数据计算、Java、Redis、MySQL、Zookeeper、azkaban2、oozie、mesos
提纲:
- 为什么要做“数据”并行计算调度?
- 他山之玉:azkaban2/oozie/mesos
- Summoner的特性
Summoner 是国玺部门推出的基于 MySQL+Redis+Zookeeper 的分布式并行计算调度和管理系统,李红红主设。
大家都可能做过基于 MySQL 数据库的,大规模的、有步骤的、步骤与步骤之间有依赖关系的数据计算。你可能定义了一堆彼此依赖的定时任务,也可能写成一个大进程跑。
举一个实际场景吧,在我们 O2O 业务体系下,我要做人员规模三四千人、有多条业务线、组织结构为大区-区域-城市-销售组的销售团队的昨日佣金和当月佣金,这里的挑战是:
- 涉及到商户、门店、交易、折扣、核销物料等等,数据量很大,至少每天都要算一次,要算得快,
- 激励政策和佣金计算公式随着竞争态势变化,一般一两个月变一次,
- 数据抽取尽可能少影响正常业务,
- 计算逻辑调整后要能快速部署和运行。
那么,以前可能会定义一些定时任务,每天凌晨从各个业务数据库(毕竟全都拆库分表了)里抽取:
- 人员组织架构
- 大区、区域和城市的对照关系
- 合同以及合同拥有者
- 商户和门店
- 门店下的收单交易
- 佣金计算公式、规则以及各种权重因子
- ……
既有全量数据,也有增量数据,所以数据量是很大的。
先算签约数、开店数、交易量等,再把业绩归结在 BD 身上,根据不同业务线的佣金计算公式依次对 BD、BD主管、城市经理等展开各种计算。
虽然我们的 JobCenter 是很优秀的定时任务调度和管理平台,但它没有步骤(即定时任务之间的依赖关系)的概念,所以以前我们只好拍脑袋定 Job1 凌晨1点执行,Job2 凌晨2点执行,Job3和Job4放在3点执行,显然这只是无奈之举,万一 Job1 跑到凌晨3点才算完怎么办?万一 Job1 执行失败了怎么办?
什么是步骤?我们可以用下图来理解一个大计算任务下步骤之间的依赖关系:
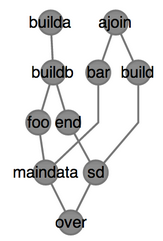
图1
为了应对这种数据量很大的抽取和一环套一环的计算,我们需要另行发展一个界面友好的、有步骤概念的、有集群调度的数据计算系统,以充分利用机器资源。
0x01,他山之玉:azkaban2/oozie/mesos
计算资源的调度,好学生有不少,如针对 hadoop 集群调度和管理的 azkaban2 和 oozie,抽象能力更高的分布式资源管理框架 apache mesos。
项目开始之初,我希望借鉴 oozie 和 azkaban2 的一些优秀设计思路,我们其实也是做调度和管理,只不过它们基于 hadoop,我们基于 mysql 而已。
给我深刻印象的调度系统特性有:
- 计算任务有步骤定义,输入输出都有灵活的定义,适合于数据收集、清洗、聚合、计算等各种常见计算场景;
- 步骤可以通过依赖关系来定义串行还是并行;
- 可以很直观地看到当前任务执行时跑到了哪一个步骤,或者哪些计算小任务;
- 如 oozie 的界面
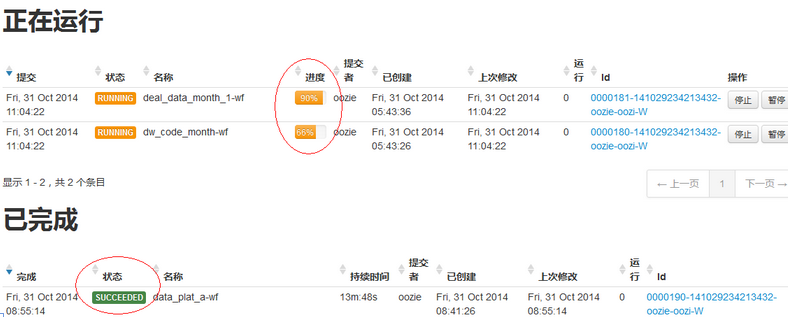
- 可以很直观地收集和展示当前任务里的输出流以及异常日志流;
- 可以很方便地暂停、终止、重启任务,无需担心遗留垃圾中间数据;
- 有报警机制,有一些简单指标展示;
- 计算任务的步骤定义视觉化
- 如 azkaban2 的界面
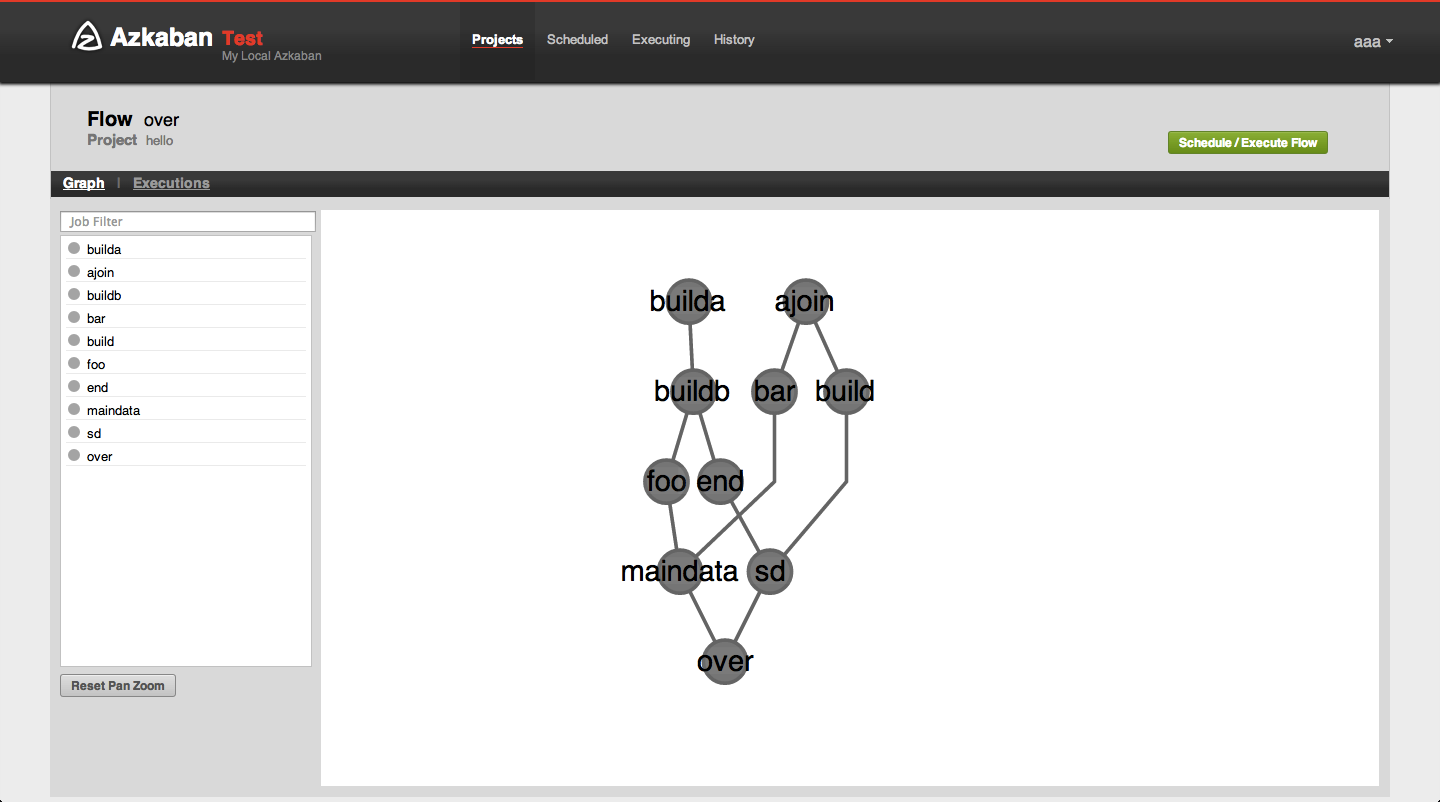
于是,国玺李红红他们开始动手设计。最终出来的效果还不错,下面介绍一下。
后来我们的容器私有云用了 apache mesos,我觉得 mesos 这种高度抽象的资源调度和管理系统非常适合我们的数据并行计算应用场景,于是假想了一番:我们写调度器去和 mesos 通信,告诉它要去执行什么命令,它去负责在整个 cluster 里调度;我们写的工程以及控制台有点儿像 marathon,依托于 mesos+chronos;我们写的从不同数据源抽取原始数据、计算佣金的代码,打成 jar 包后放在 mesos master 上,配置好后,mesos slave 真的接到调度指令去运行时,会自己从 master 节点下载 jar 包并执行,blabla……这样 mesos 能替我们省了不少开发工作。
0x02,Summoner的特性
下面介绍一下我们针对数据计算的分布式并行计算调度系统——Summoner(魔法师)。
我们命名一个大计算任务为『工作流』,工作流下有多个任务,任务彼此之间可以可视化地建立依赖关系。
工作流可以设定 Quartz cron 表示式从而定期执行,可以直观地看到任务执行的进度,执行日志、异常日志,状态。
我们还可以复用任务,一个任务可以隶属于多个工作流。这样当佣金计算规则变化时,我们只需要复用一部分任务,新增一些任务,另建一个新工作流把任务串起来即可,同时把原来的工作流禁用,这样进退自如。
负责执行任务的客户端(jar包)能够自动注册(通过 Zookeeper),于是系统知道现在有多少个机器节点可以执行某一个任务。
于是,假如任务B有了10个客户端注册,任务A抽取了一千万条交易记录,系统将这批记录分拆为十份,发给10个任务B客户端,于是任务B将在多个机器节点上并行计算,然后系统再去调度任务C。
它的菜单功能有:
- 资源配置管理
- 工作流管理
- 任务管理
- 依赖关系管理
- 注册管理(客户端注册和服务器端注册)
- 任务调度管理
- 调度管理
- 实时数据管理
- 工作流执行情况
- 调度日志管理
- 调度日志
下面是首页工作台,我们可以看到自己帐号下有多少个工作流执行完成/失败/暂停执行/取消执行,以及系统报警和信息的通知。

图2 summoner首页工作台
首先,我们需要建立工作流:
图3 资源配置管理-工作流管理
我们还要把任务建起来,任务真正的执行者是一个 Java 实现的任务处理类:
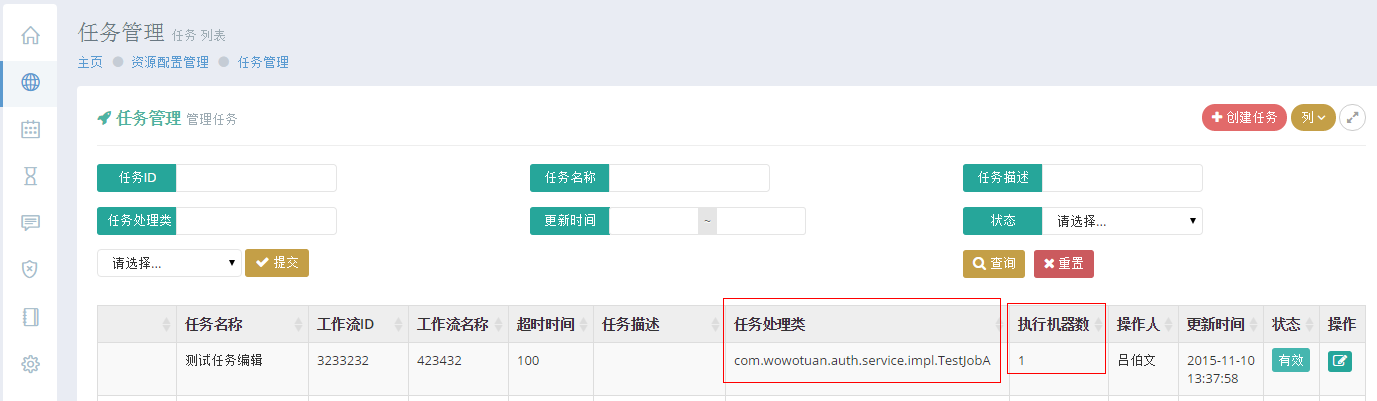
图4 任务管理
图5 编辑任务
其次,我们要任务之间的依赖关系建立起来:
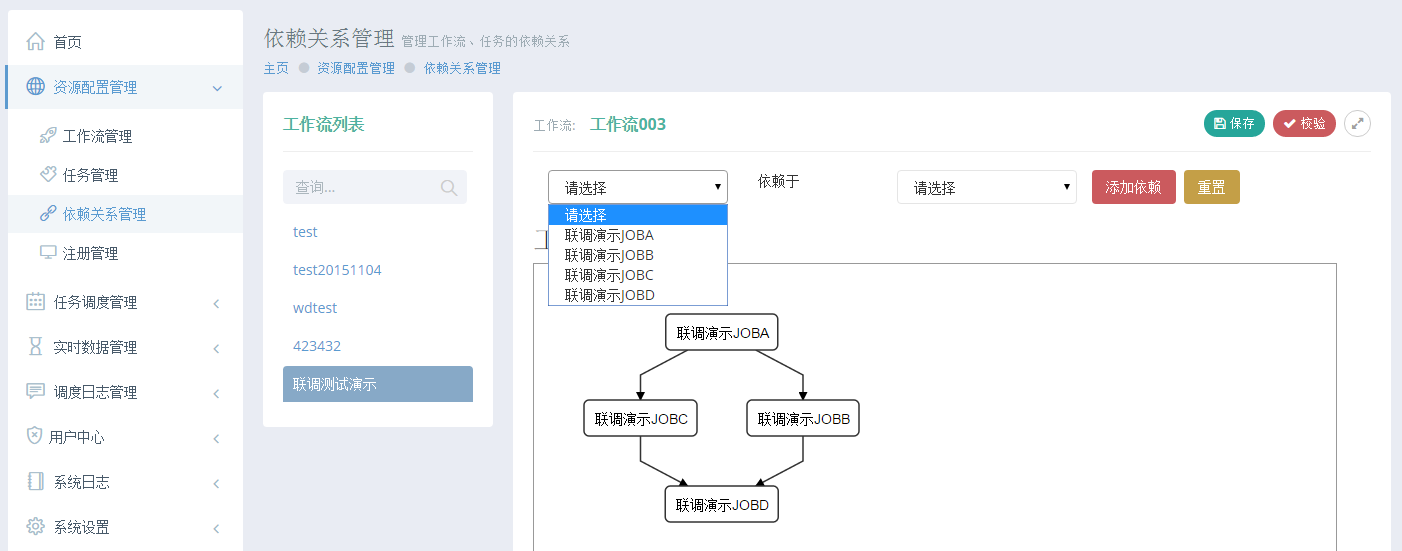
图6 依赖关系管理
然后管理工作流:
图7 工作流图管理
我们可以让工作流立即执行,来观察它的进度:
图8 调度日志管理
以及每一个任务的进度:
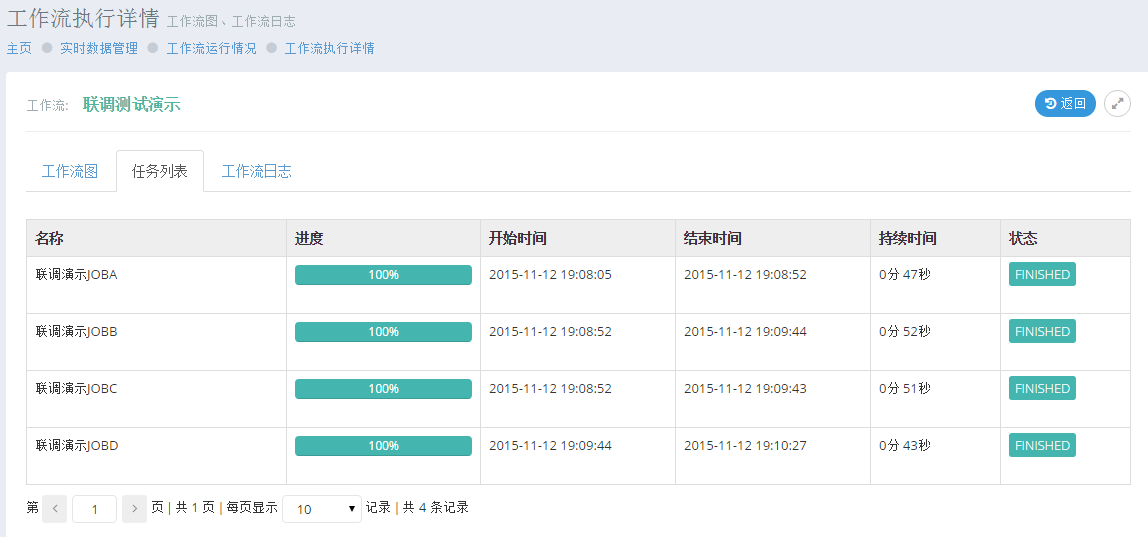
图9 工作流执行详情
集群里不同节点都可能会卷入工作流执行,它们产生的日志会被 flume 聚合,之后在平台上实时展示:

图10 工作流执行日志
图11 客户端注册
图12 服务器端注册
图13 系统通知
Summoner 是 JobCenter 的延伸和有益补充,它们各自有各自的应用场景。我们还会借鉴 mesos 的先进理念,进一步提升 Summoner 的集群调度能力。
-EOF-
欢迎阅读我的其他电商文章:
- 内部Hybrid App经验解读
- iDB是如何运转的 一
- #研发解决方案#iDB-数据库自动化运维平台
- 容器私有云和持续发布都要解决哪些基础问题 第二集
- 容器私有云和持续发布都要解决哪些基础问题 第一集
欢迎订阅我的微信订阅号『老兵笔记』,请扫描二维码关注:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号