
利用新浪微博API的Search接口做微博锐推榜
郑昀 20100929
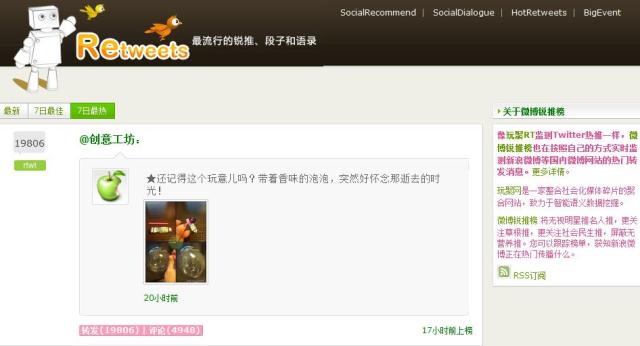
应用入口:http://t.rtmeme.com/
简单介绍下我们这个榜单与新浪自己的热门转发榜区别:
微博锐推榜 将无视明星推名人推,更关注草根推,更关注社会民生推,屏蔽无营养推。
微博锐推榜 将聚合以新浪微博为首的国内各大微博网站的热门转发消息。
1、新浪的接口
新浪微博的API提供了Search方法,如它的文档所示:
URL:
http://api.t.sina.com.cn/search.json格式:
仅支持json
GET是否需要登录:
true请求数限制:
true请求参数:
page: 选填参数,页码(从1开始, 默认1)
rpp:选填参数,每页返回的微博数,默认返回10条,最大200
虽然它称“需要登录”,但实际上只要传入AppKey即可,无需登录,无需OAuth,当然不排除以后新浪强制要求都OAuth登录,不过Twitter至今也没对Search接口做如此要求。
2、只抓转贴
我们只需要新浪微博里的转贴记录。
计算新浪微博锐推榜,与Twitter锐推榜相同之处:
- 都是只针对原帖正文做信息指纹提取;
- 上榜时只保留原帖内容和作者。
与Twitter锐推榜不同之处在于:
- 不需要保存所有转发者的转发文字(因为多半都是类似于“转发微博”这样的废话,没有必要大量存储),只需保存这些人的个人信息即可,如头像、ScreenName、Location等。
- 重要的是,知道最近几小时内有多少人转发即可,当要计算某条消息是否可以上榜时,将更进一步获取它的转发数和评论数。因为很古老的消息也会再次掀起转发高潮,所以鉴别原始消息发布时间很重要。
- 保存原消息缩略图、大图等多媒体信息。
3、榜单计算办法
默认存储的都是原始消息的数据(正文、作者、头像、缩略图、信息指纹),扫描到的转发者仅记录名称、头像、id。
定时统计最近4小时内信息指纹出现次数,如果次数足够多,比如5次,那么尝试获取(先数据库,后API)原始消息的转发数和评论数,如果转发数足够大,如大于40次,评论数又小于转发数,则准备上榜,做上榜前最后机器审核。
为了保持榜单的高质量,必须制定以下规则:
1、屏蔽某些原作者和转贴者的ID;
2、屏蔽某些关键词;
3、重点阻止娱乐界明星上推;
4、要求消息正文提取的标签数必须大于2,以此阻止无营养或过短的消息上榜;
5、屏蔽并尽可能识别那些刷屏聊天的,比如忽略那些转发者和原作者是同一个人的;
6、重点屏蔽星座推、生日推、节日推、找人推;
7、转发的原帖发布时间必须是最近N小时内的,防止老推翻新;
8、屏蔽某些垃圾信息源,比如:书签、分享、56.com、优酷、土豆网、关联博客等等;
9、屏蔽那些职业转贴人,比如XX语录,XX冷笑话等等。
10、原始消息中“@”“#”等字符过多,也必须屏蔽;
4、表结构
原始资讯都存储在 MongoDB 。榜单则存储在 MySql ,方便Web访问。
5、频率
由于新浪微博对Search接口的轮询频率有要求,比如每小时1000次,所以我们要尽量避免轮询过快。
统计上榜消息时,会调用新浪微博API的counts接口,也要注意调用频率。
微博锐推榜应用网址:
[完]

