

浅谈java类集框架和数据结构(1)
在另外一篇博客我简单介绍了java类集框架相关代码和理论。
这一篇博客我主要分析一下各个类集框架的原理以及源码分析。
一:先谈谈LinkedList
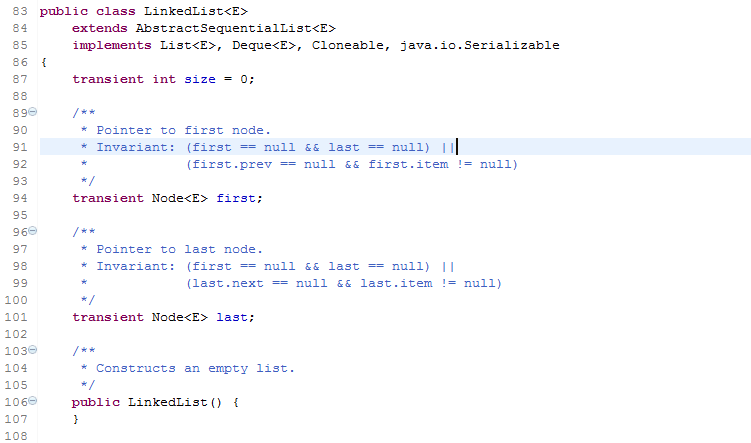
这是LinkedList源码的开头,我们能看到几点,1.它的继承关系,实现了哪些接口,Deque<E>就是Quene队列的子类.
2.他的Node属性都是transient关键字,transient即代表在串行化的时候不会持久化数据,LinkedList是实现了序列化接口的,但是这个transient关键字决定了在串行化过程中Node的结果。
继续往下看:
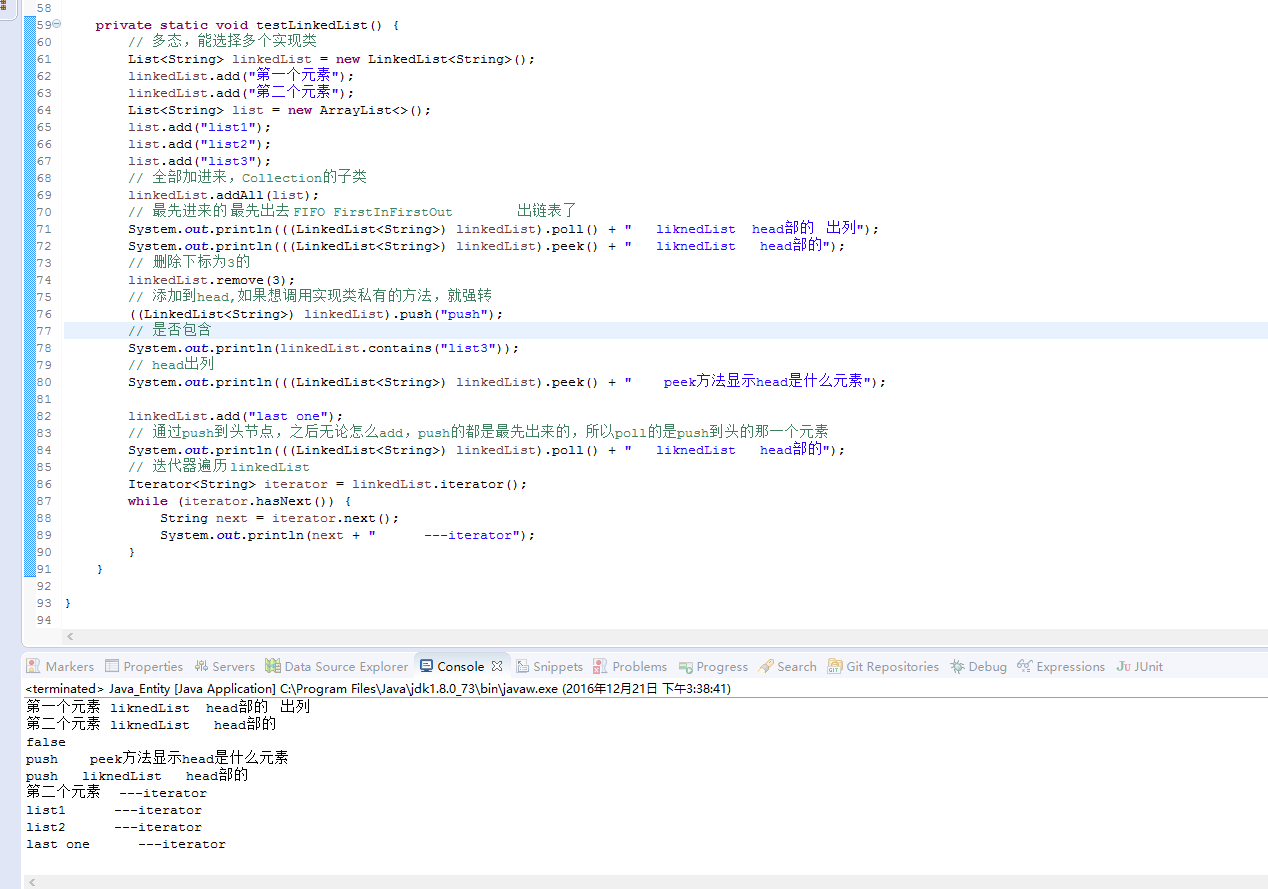
上面代码是我写的测试方法,调用main方法的代码就不展示了,这样比较直观的对应输出关系。
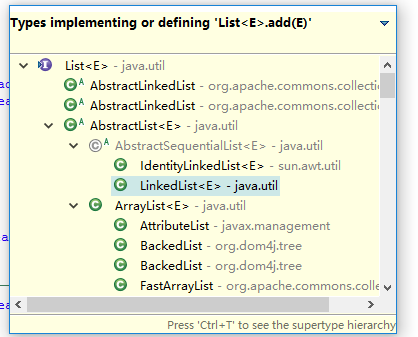
可以看到Collection<E>类集List<E> 的add方法种类,这里选择LinkedList进去看源码。
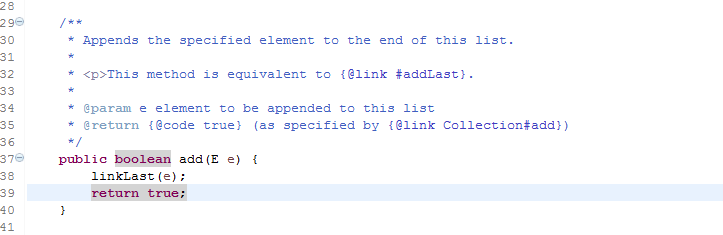
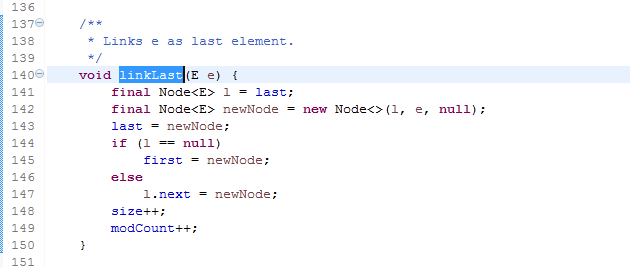
add调的是linkLast方法,现在我来解释一下这个方法。
LinkedList在add添加元素的时候调用了这个方法,这个方法的意思是:
首先介绍一下Node节点这个数据结构,含有 前(prev) 值(element) 后(next),这三个属性,我习惯称为火车头,数据,火车尾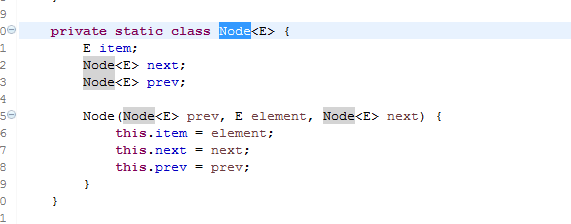
当添加元素的时候,如果是第一个头元素(l==null,l代表火车尾),Node的first节点就是该元素,如果火车尾不是空的,也就是代表火车尾挂着一个节点,那么就讲这个元素挂到next节点,像挂火车那样挂。
这里要注意的是链表的数据结构是会挂一个空车厢做车头,也就是说第一次add的元素就会做第一节车厢,接下来判断last都不为空,那么都一节一节往后挂车厢,这就是链表的数据结构,其余的方法看我贴的代码应该可以理解,注释的很细。
二:谈谈HashMap
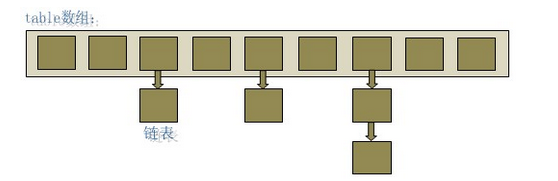
这个图是我刚才网上截下来的,这也是大家看到最多的hashmap的数据结构,没错就是个table数组挂链表,“链表散列”数据结构,其实原理也很容易解释,在table数组上有很多的位置,每个位置都是一个entry,每个位置就是一个burket篮子,放entry用的。
entry保存的就是key value的建值对,这就是hashmap的数据结构,那么实现这个数据结构的原理就是利用hash算法进行burket的确定,利用hash算法决定这条建值对存放在哪一个篮子里面,如果hashcode冲突的情况下进行equals方法的比较,如果hashcode一样且equals也相等,就在数组的基础上挂链表,解决hash冲突问题。
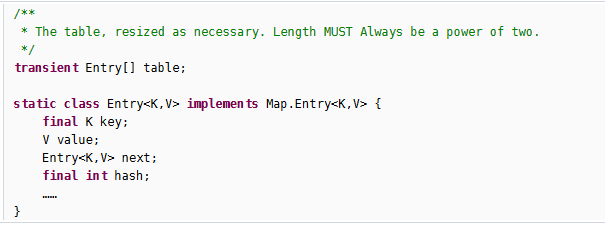
附带一句,hashmap是线程不安全的,异步的,Set底层使用的是hashmap的key存放数据,value存放Object类型的没什么用(个人理解)的标记。
hashtable则是线程安全的同步。
三:ArrayList和Stack
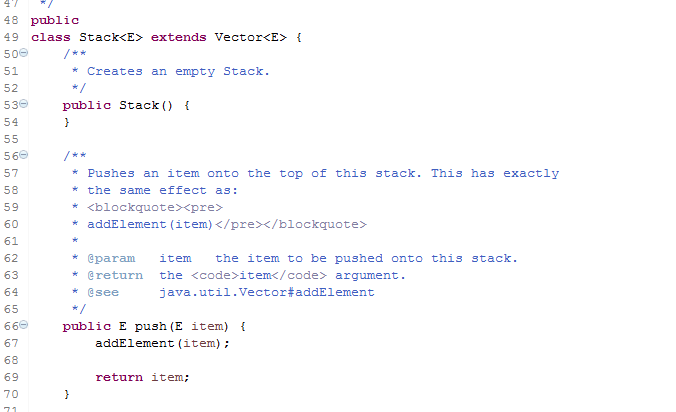
栈没什么好讲的,先进先出,压栈就可以形容这种数据结构,就像把砖块一块一块的叠高,最后叠的最先拿走,也就是First In First Out的由来FIFO。
栈是继承了Vector这个古老的类,Vector和ArrayList几乎没什么区别,我个人理解是ArrayList是在Vector的基础上做了变动衍生的类,因为ArrayList和Vector继承和实现结构都一致,方法大多一样,显而易见的区别只有add等方法Vector使用了同步关键字。
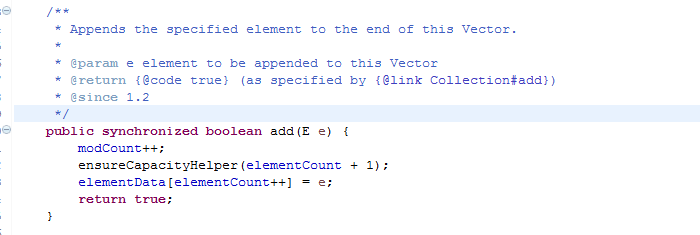


还有一点区别是ArrayList扩容的时候是增加50%的数组长度,Vector是直接增加一倍的容量,这一点来说ArrayList更节省内存、
另外要提的一点就是ArrayList在查找方面的性能明显优于LinkedList,因为get方法源码调的是Object数组进行二分查找,而LinkedList无论查哪一位都要从火车头找下去,一节一节的去按顺序遍历。
而LinkedList在插入方面性能高于ArrayList,而且ArrayList不适合频繁的插队数据以及删除数据,链表这种顺序队列结构更适合于频繁插队。
今天先讲这么多,改天再说剩下的,讲的比较随意,网上很多介绍的东西我就没赘述了,主要说一说个人理解。

