hadoop 文件参数配置
准备环境(省略)
- 上传实验所需的压缩包
- 配置网络信息
- 修改主机名
- 配置域名解析
- 关闭防火墙与SELinux(在所有节点上执行)代码如下:
systemctl disable --now firewalld
setenforce 0
vim /etc/selinux/config
修改:SELINUX=disabled
保存退出
(1)在 Master 节点上安装 Hadoop
步骤一:解压缩 hadoop-2.7.1.tar.gz安装包和jdk-8u152-linux-x86.tar.gz到/usr目录下

步骤二:将 hadoop-2.7.1文件夹和jdk-8u152文件夹重命名为 hadoop和jdk

步骤三:配置 Hadoop环境变量
注意:在第二章安装单机 Hadoop 系统已经配置过环境变量,先删除之前配置后添加

- 在文件末尾添加以下配置信息
分别将JAVA_HOME和HADOOP_HOME指向 JAVA安装目录;JAVA安装目录和HADOPOP安装目录加入 PATH路径

步骤四:使配置的 Hadoop的环境变量生效
- 切换进hadoop用户
- 使环境变量生效

步骤五:执行以下命令修改 hadoop-env.sh配置文件

- 在文件中间添加以下配置信息

(2)配置 hdfs-site.xml 文件参数
- 执行以下命令修改 hdfs-site.xml配置文件

- 在文件中
和 一对标签之间追加以下配置信息
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
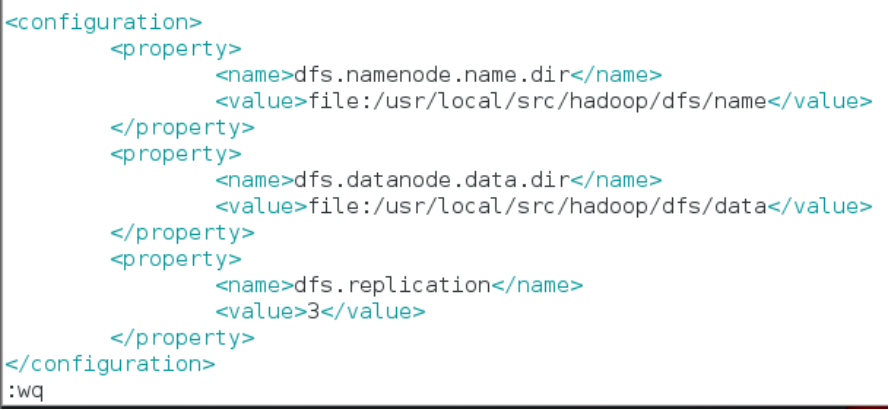
对于 Hadoop 的分布式文件系统 HDFS 而言,一般都是采用冗余存储,冗余因子通常为3,也就是说,一份数据保存三份副本。所以,修改 dfs.replication的配置,使 HDFS文件的备份副本数量设定为 3个
-
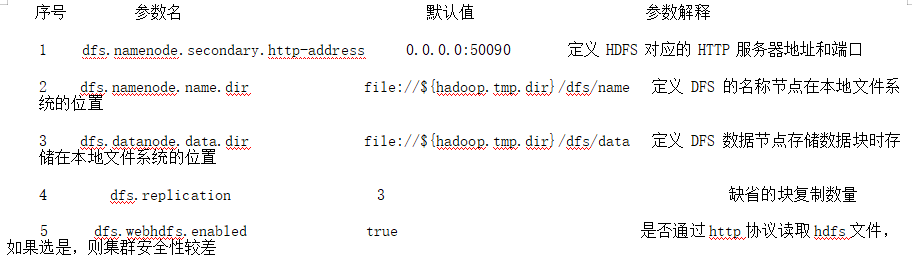
该配置文件中主要的参数、默认值、参数解释如下表所示:
hdfs-site.xml配置文件主要参数:
(3)配置 core-site.xml 文件参数
- 执行以下命令修改 core-site.xml配置文件
- 在文件中
和 一对标签之间追加以下配置信息
**此处master 为虚拟机IP,也可为自己域名解析内配置的hostname **
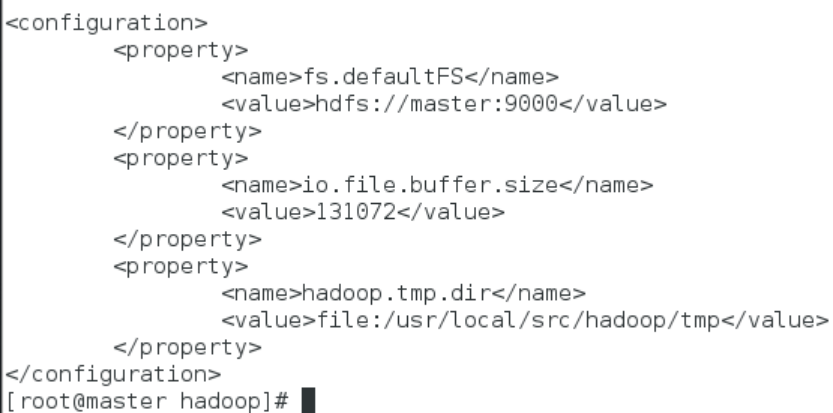
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop/tmp</value>
</property>
</configuration>
如没有配置 hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoop-hadoop。该目录在每次 Linux系统重启后会被删除,必须重新执行 Hadoop文件系统格式化命令,否则 Hadoop运行会出错
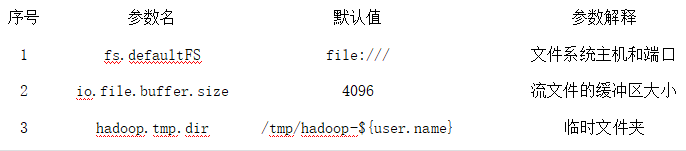
- 该配置文件中主要的参数、默认值、参数解释如下表所示:
core-site.xml配置文件主要参数:
(4)配置 mapred-site.xml
在“/usr/local/src/hadoop/etc/hadoop”目录下有一个 mapred-site.xml.template,需要修改文件名称,把它重命名为 mapred-site.xml,然后把 mapred-site.xml文件配置成如下内容
- 执行以下命令修改 mapred-site.xml配置文件
确保在该路径下执行此命令

- 在文件中
和 一对标签之间追加以下配置信息
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>

- 该配置文件中主要的参数、默认值、参数解释如下表 所示:
mapred-site.xml配置文件主要参数:

- Hadoop 提供了一种机制,管理员可以通过该机制配置 NodeManager 定期运行管理员提供的脚本,以确定节点是否健康。管理员可以通过在脚本中执行他们选择的任何检查来确定节点是否处于健康状态。如果脚本检测到节点处于不健康状态,则必须打印以字符串 ERROR开始的一行信息到标准输出。NodeManager 定期生成脚本并检查该脚本的输出。如果脚本的输出包含如上所述的字符串ERROR,就报告该节点的状态为不健康的,且由NodeManager将该节点列入黑名单,没有进一步的任务分配给这个节点。但是,NodeManager继续运行脚本,如果该节点再次变得正常,该节点就会从ResourceManager黑名单节点中自动删除。节点的健康状况随着脚本输出,如果节点有故障,管理员可用 ResourceManager Web界面报告,节点健康的时间也在 Web界面上显示
(5)配置 yarn-site.xml
- 执行以下命令修改 yarn-site.xml配置文件

- 在文件中
和 一对标签之间追加以下配置信息
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>

该配置文件中主要的参数、默认值、参数解释如下表 所示:

很显然,很多参数没有专门配置,多数情况下使用默认值。例如,可以追加以下两个参数 配 置 项yarn.resourcemanager.hostname( 即 资 源 管 理 器 主 机 ) 和“yarn.nodemanager.aux-services”(即 YARN节点管理器辅助服务),若要将主节点也作为资源管理主机配置,则配置值分别为“Master_hadoop”、“mapreduce_shuffle”。
在 yarn-site.xml 中可以配置相关参数来控制节点的健康监测脚本。如果只有一些本地磁盘出现故障,健康检查脚本不应该产生错误。NodeManager有能力定期检查本地磁盘的健康状况(特别是检查 NodeManager本地目录和NodeManager日志目录),并且在达到基于“yarn.nodemanager.disk-health-checker.min-healthy-disks”属性的值设置的坏目录数量阈值之后,整个节点标记为不健康,并且这个信息也发送到资源管理器。无论是引导磁盘受到攻击,还是引导磁盘故障,都会在健康检查脚本中标识
(6)Hadoop 其它相关配置
配置 masters文件
- 加入以下配置信息

- master主机 IP地址

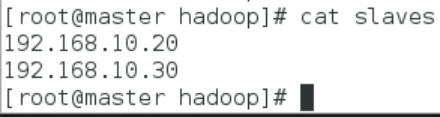
配置 slaves文件
本教材 Master 节点仅作为名称节点使用,因此将 slaves 文件中原来的 localhost 删除,并添加 slave1、slave2节点的 IP地址
- 删除 localhost,加入以下配置信息

- slave1主机 IP地址

- slave2主机 IP地址
新建目录
- 执行以下命令新建/usr/local/src/hadoop/tmp、/usr/local/src/hadoop/dfs/name、/usr/local/src/hadoop/dfs/data三个目录

修改目录权限
- 执行以下命令修改/usr/local/src/hadoop目录的权限


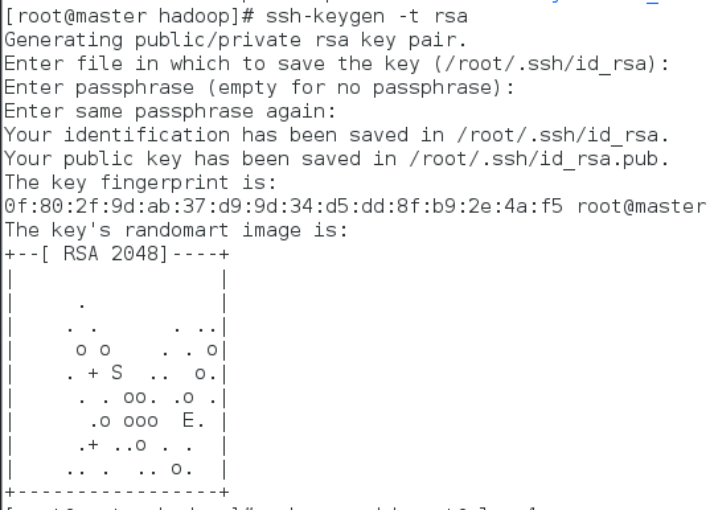
配置master能够免密登录所有slave节点
ssh-keygen -t rsa
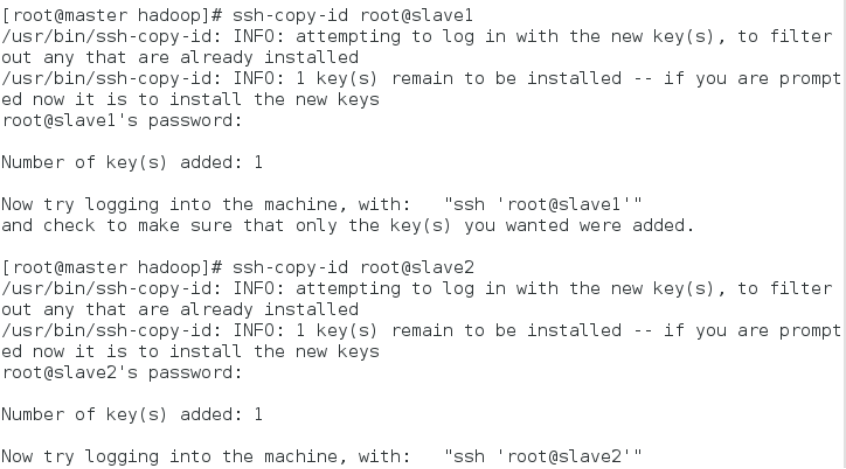
ssh-copy-id root@slave1
ssh-copy-id root@slave2
同步配置文件到 Slave节点
-
上 述 配 置 文 件 全 部 配 置 完 成 以 后 , 需 要 执 行 以 下 命 令 把 Master 节 点 上 的“/usr/local/src/hadoop”文件夹复制到各个 Slave节点上,并修改文件夹访问权限
-
将 Master上的 Hadoop安装文件同步到 slave1、slave2

-
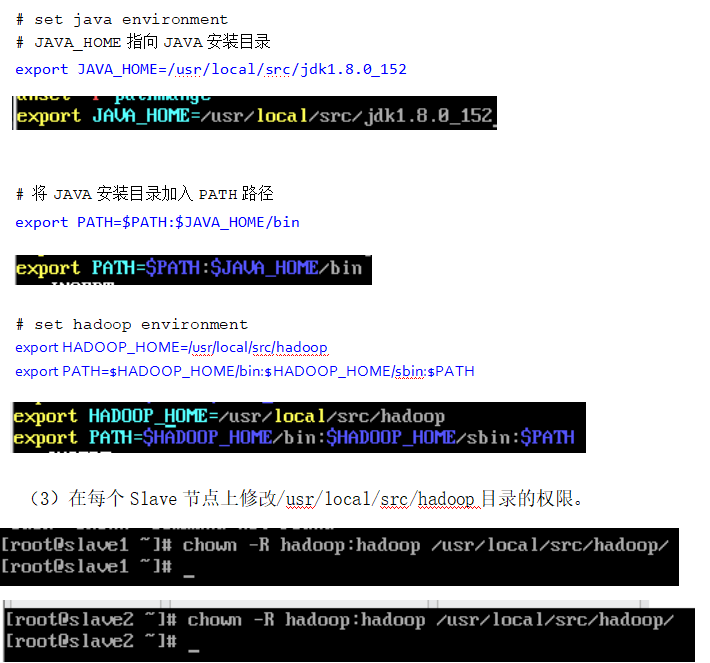
在每个 Slave节点上配置 Hadoop的环境变量
注意:若 slave1,slave2 在/usr/local/src/目录下jdk1.8.0_152 文件,需返回第二章安装好 Java环境 -
分别进入slave节点


-
分别在slave1和slave2主机文件的末尾添加
-
在每个 Slave节点上切换到 hadoop用户
-
使每个 Slave节点上配置的 Hadoop的环境变量生效