


关于base64编码的原理和实现
在前文 Data URI 应用场景小结 中我们提到了一个概念,叫做 base64编码,今天我们就来聊聊 base64编码,揭开它的神秘面纱。
一句话解释:Base64是一种基于64个可打印字符来表示二进制数据的表示方法。
用记事本打开 exe、jpg、pdf 这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法。Base64 是一种最常见的二进制编码方法。
Base64的原理很简单,首先,准备一个包含 64 个字符的数组:
复制代码['A', 'B', 'C', ... 'a', 'b', 'c', ... '0', '1', ... '+', '/']
附 base64 索引表:
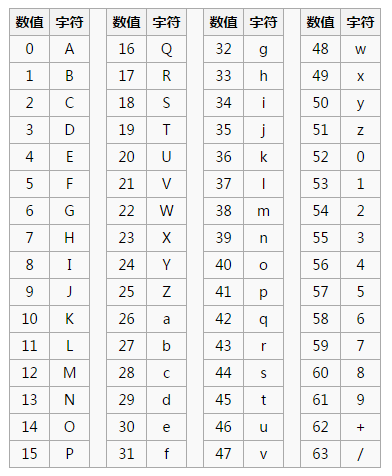
然后,对二进制数据进行处理,每 3 个字节一组(如果字节数不能被 3 整除,则用 0 补位),每个字节是 8 bits,一共是 3 x 8 = 24 bits,划为 4 组,每组正好 6 个 bits。将每组的 6 bits 转为十进制数字,这样我们得到 4 个数字作为索引(3->4,所以经过 base64 编码的图片会比原文件大 1/3,不过一般经过 gzip 压缩后跟原文件大小差不多),然后查表,获得相应的 4 个字符,就是编码后的字符串。
如果是字符串的 base64 编码,具体步骤为:
- 获取字符串每个字符的 ASCII 码,如果字符数不能被 3 整除,则末尾补 0
- 将步骤 1 获取的 ASCII 码转为 8 位 二进制码
- 每 6 bits 为一组,并将 6 位二进制码转为十进制
- 对照上面的 base64 索引表,得到编码后的字符串
需要注意的是:
- 要求被编码字符是 8bit 的,所以须在 ASCII 编码范围内,\u0000-\u00ff,中文就不行
- 如果被编码字符长度不是 3 的倍数的时候,则都用 0 代替,对应的输出字符为 =,而不是查表所得的 A(所以通过 base64编码 的图片最后有时会有 1-2 个 =)
举两个例子:
(1)字符长度能被 3 整除时,比如 'han':
复制代码 h a n
ASCII 104 97 110
8bit字节 01101000 01100001 01101110
6bit字节 011010 000110 000101 101110
十进制 26 6 5 46
对应编码 a G F u
(2)字符长度不能被 3 整除时,比如 'zichi':
复制代码 z i c h i
ASCII: 122 105 99 104 105
8bit字节: 01111010 01101001 01100011 01101000 01101001 00000000(补)
6bit字节: 011110 100110 100101 100011 011010 000110 100100 000000
十进制: 30 38 37 35 26 6 36 异常
对应编码: e m l j a G k =
事实上,高级浏览器已经内置了 atob (ASCII to Binary)以及 btoa (Binary to ASCII)函数分别用来处理解码和编码 base64 字符串。atob() 函数能够解码通过 base-64 编码的字符串数据。相反地,btoa() 函数能够从二进制数据“字符串”创建一个 base-64 编码的 ASCII 字符串。(PS:特别要注意的是 btoa 是编码,atob 是解码 o(╯□╰)o)
不幸的是某些版本的 IE 浏览器并不支持 atob() 以及 btoa() 函数,好在理解了上述的编码步骤,一个 base64编码、转码器也就不难实现了,可以猛戳 DEMO 进行查看(HTML 部分 fork 了岑安大大的代码,把 select 改成了 radio,个人觉得 radio 更方便)。代码放在了 Github。

