

HTTP----HTTP简介
1. 网络基础
TCP/IP
通常使用的网络是在TCP/IP协议簇基础上运作的. HTTP属于它内部的一个子集.
TCP/IP分为4个层次, 应用层, 传输层, 网络层, 链路层.
(Application layer, Transport layer, Internet layer, Link layer)
按层次分, IP位于网络层. IP协议的作用是包各种数据包传送给对方, 要正确传送数据包, 需要满足
2个重要的条件: IP地址和MAC地址. ARP协议可以把IP地址解析成MAC地址.
按层次分, TCP位于传输层, 提供可靠的字节流服务. TCP的三次握手是指: 发送端首先发送一个带有
SYN标志的数据包给对方, 接受端收到后回传一个带有SYN/ACK标志的数据包表示确认信息, 最后发送
端再回传一个带有ACK标志的数据包, 代表"握手"结束.
HTTP
Hypertext Transfer Protocol (HTTP), 是应用层协议.
HTTP/1.1版本是第一个被广泛使用的版本并且目前仍被广泛使用, 该版本目前有3个规范, 分别是
RFC2068(1997), RFC2616(1999), 前2个版本规范已被RFC7230-RFC7235所替代.
HTTP/2发布于2015, 规范为RFC7540.
DNS
Domain Name System (DNS), 服务和HTTP协议一样位于应用层. 提供域名到ID地址之间的解析服务.
URI, URL, and URN
Uniform Resource Locator (URL), 统一资源定位符.
Uniform Resource Identifier (URI), 统一资源标识符.
Uniform Resource Name (URN), 统一资源名称.
我们先来看示例, 在RFC3986中给出以下URI的示例.
- ftp://ftp.is.co.za/rfc/rfc1808.txt
- http://www.ietf.org/rfc/rfc2396.txt
- ldap://[2001:db8::7]/c=GB?objectClass?one
- mailto:John.Doe@example.com
- news:comp.infosystems.www.servers.unix
- tel:+1-816-555-1212
- telnet://192.0.2.16:80/
- urn:oasis:names:specification:docbook:dtd:xml:4.1.2
上面这些全部属于URI, 但是有些属于URL, 比如1和2.有些属于URN比如5, 6, 7.
由上可以总结出, URI可以表示1个资源的位置或者名称, 也可以同时表示两者.
URL表示资源的位置, 也就是我们一般所说的网址.
URN表示资源的名字, 比如isbn, mailto.
URI的格式
hierarchical part
┌───────────────────┴─────────────────────┐
authority path
┌───────────────┴───────────────┐┌───┴────┐
abc://username:password@example.com:123/path/data?key=value&key2=value2#fragid1
└┬┘ └───────┬───────┘ └────┬────┘ └┬┘ └─────────┬─────────┘ └──┬──┘
scheme user information host port query fragment
urn:example:mammal:monotreme:echidna
└┬┘ └───────────────┬──────────────┘
scheme path从网址到页面
- DNS服务器把域名解析成对应的IP地址.
- 根据HTTP协议, 生成针对目标Web服务器的HTTP请求报文.
- 根据TCP协议, 将HTTP请求报文分割成报文段.
- 根据IP协议搜索对方的地址, 一边中转一边传送.
- 服务器接受到报文段, 重组成原来的报文.
- 根据客户端HTTP请求报文, 服务器进行处理, 并把处理结果同样利用TCP/IP协议进行回传.
2. HTTP简单概括
通过实例看HTTP
通过使用谷歌浏览器和火狐浏览器自带的调试工具, 带你真实体验下, HTTP协议到底长什么样.
准备工具: 谷歌浏览器最新版
我使用的版本是: Chrome 60.0.3112.113(64-bit)
OK, 用谷歌浏览器器打开http://example.org/, 按F12打开开发者工具, 选到Network选项
卡, 按F5刷新一下页面, 你应该看到如下内容:

从中可以看到, example.org是我们请求的URL, 200是状态码代表请求成功. 点开example.org,
在Response Headers和Request Headers的右边把view source. 像下面这样:
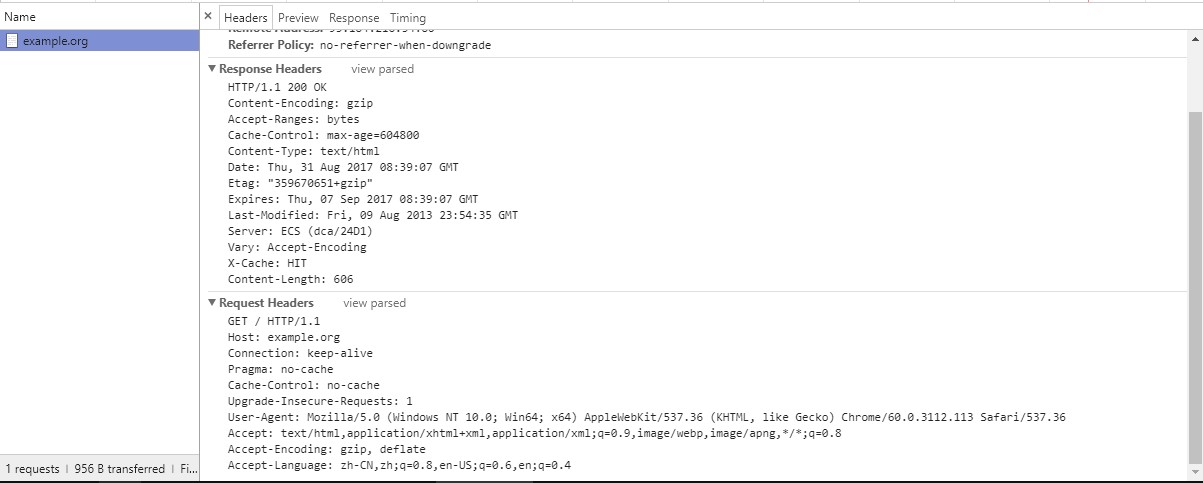
接下来就到了关键的时刻了, 如果我们对HTTP协议一无所知的话, 肯定想问: 这些是什么? 把这些简单
看懂, HTTP协议也就入门了.
我们知道, HTTP协议是向服务器请求数据用的, 说白了就是下载文件的. 看图中Request Headers部
分, 这是请求头部, 有很多行, 只有第2行, 是我们明明白白在浏览器的地址栏中输入的, 其它的部分,
显然是浏览器自动为我们添加上去的. 第1行, 代表请求的方法和使用HTTP的版本. 第2行, 很明显是请求
的URL, 第7行User-Agent, 如果是做网站的是不是非常熟悉这个, 用户代理, 由于一些历史原因想要
根据用户代理直接得出用户使用的具体浏览器, 不是那么靠谱. 接下来Accept, Accept-Encoding,
Accept-Language, 分别代表客户端(也即是浏览器)能够接受的数据格式, 数据压缩格式, 以及语言.
从客户端向服务器端的请求, 我们分析完了. 接下来看看, 从服务器端到客户端的响应, 也就是
Response Headers, 我们可以看出, 通信使用的HTTP版本, 200是状态码, 代表成功响应, OK是状态
码对应的原因短语.Content-type代表服务器返回的数据格式, Server代表服务器类型.
Content-Length代表返回数据的大小. 显然我们可以看到Response Headers说了一大堆, 都是在
告诉我们, 服务器返回的数据是什么样的, 但返回的数据到底在哪? 点击Response选项卡, 就能看到服
务器具体返回的数据内容了.像下图这样:
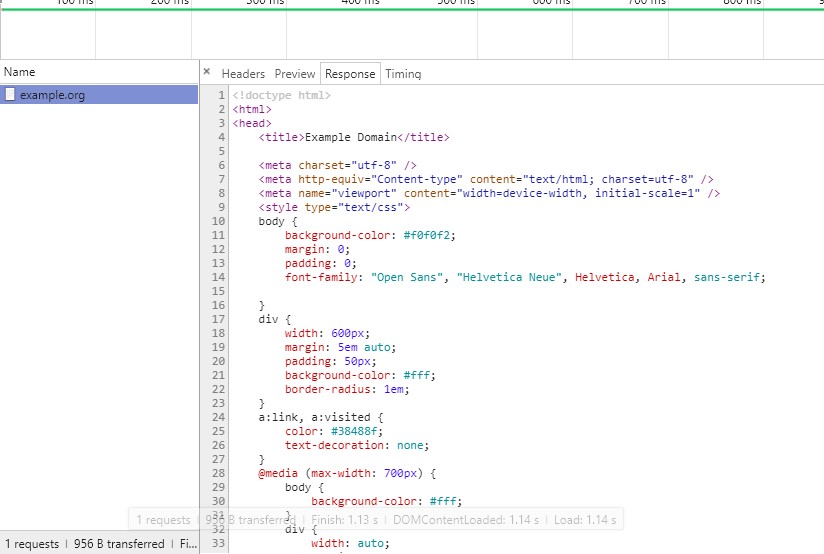
返回的是源代码, 经过浏览器解析, 就会生成响应的视觉效果.
HTTP报文组成
客户端的HTTP报文叫做请求报文, 服务器的返回的叫做响应报文, HTTP报文本身是由多行(换行使用CRLF)
数据构成的字符串文本. 请求报文和响应报文, 都可以分为3个部分: 报文首部, 空行(CRLF), 报文主体.
报文主体非必须, 可省略, 尤其是对于请求报文, 经常没有报文主体.
下面是一段完整的请求报文和响应报文的实例:
GET / HTTP/1.1
Host: example.org
Connection: keep-alive
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.4
HTTP/1.1 200 OK
Content-Encoding: gzip
Accept-Ranges: bytes
Cache-Control: max-age=604800
Content-Type: text/html
Date: Thu, 31 Aug 2017 09:25:34 GMT
Etag: "359670651"
Expires: Thu, 07 Sep 2017 09:25:34 GMT
Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT
Server: ECS (dca/2469)
Vary: Accept-Encoding
X-Cache: HIT
Content-Length: 606
<!doctype html>
<html>
<head>
<title>Example Domain</title>
</head>
<body>
省略部分响应报文主体内容.....
</body>
</html>请求报文首部的第1行, 叫做请求行. 包含用于请求的方法, 请求的URI和HTTP版本.
响应报文首部的第1行, 叫做状态行. 包含表明响应结果的状态码, 原因短语和HTTP版本.
请求报文和响应报文都包含有各种首部字段, 一般响应报文会包含响应报文主体, 其
和响应报文首部用1个CRLF空行隔开.
看到这里, 不知道大家有没有1个想法. 既然HTTP协议, 就是由请求报文首部(Request Headers),
响应报文首部(Response Headers), 响应报文主体(Response Payload). 而且这3者是配套存在,
属于对应关系. 那么只要我们能够知道不同响应报文首部, 得出的响应报文首部和响应报文主体, 分
别是什么, 有什么区别. 那就可以认为我们基本掌握了HTTP.
那么问题来了首先我们得有个工具, 能够让我们随意修改请求报文首部才行, 如果你跟我想的一样,
那我们真是志同道合, 我尝试了各种工具什么postman, wireshark, 甚至是打开Linux虚拟机,
安装HTTPie, 结果发现这些工具都不能让我满意, 不是图形化界面严重就是该显示的信息显示不全.
到最后我偶然打开, Firefox的调试工具, 结果发现, 握草, 这不正是我要找的工具吗?
3. 使用Firefox修改请求首部
我使用的Firefox版本是: 55.0.3(64-bit)
在Firefox中打开http://example.org/, 在控制台中可以看到HTTP报文信息如下:
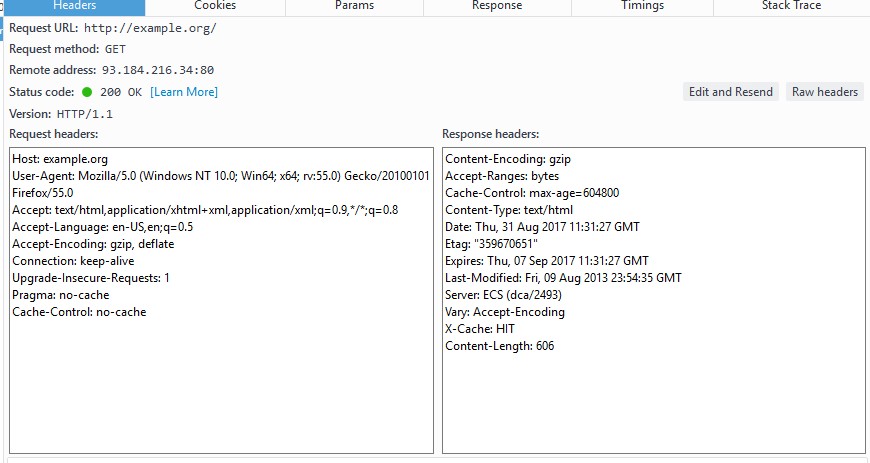
可以看到, 虽然我点了Raw headers, 但是Firefox给出的请求首部和响应首部, 仍和我们在上
面看到的完整报文示例有些细微区别, 有点遗憾. 为了演示修改请求报文首部, 服务器将返回不用
的响应, 我在这里介绍一个请求报文首部Range: bytes=500-800, 这条首部的意思就是请求服
务器返回500-800这部分内容, 也就是获取部分内容范围请求.
点击Edit and Resend, 在请求报文首部的最后, 添加一行Range: bytes=500-800,如下图
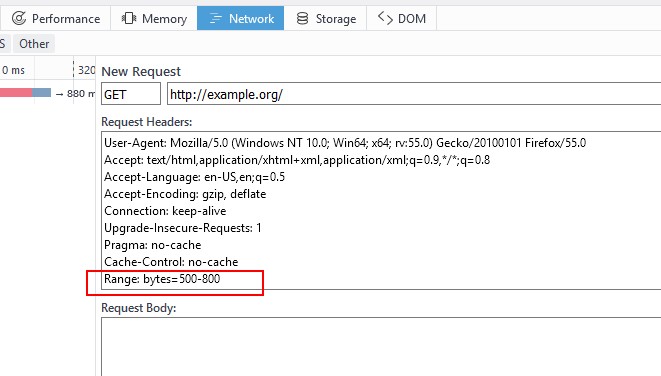
添加完之后点击Send, 可以看到服务返回了如下图所示的首部.
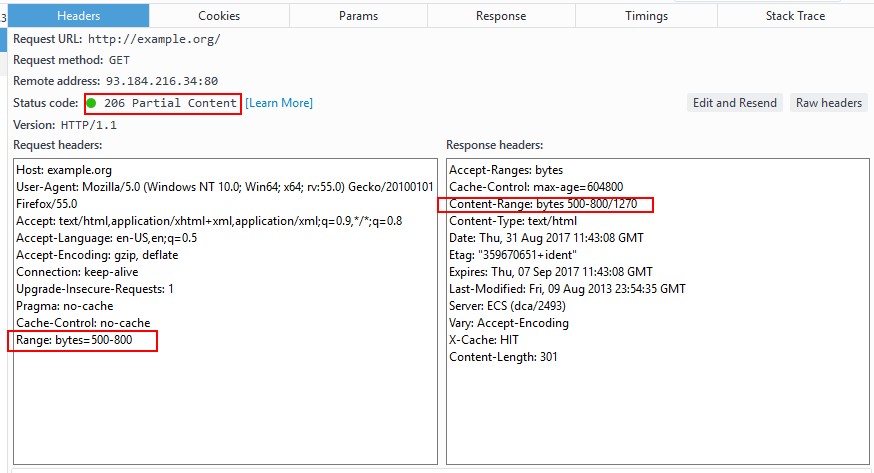
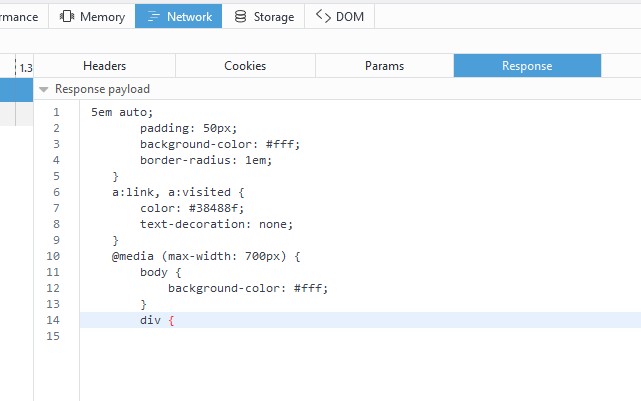
点击Response可以看到, 响应报文主体确实只返回了部分内容. 证明通过使用不用的报文首部
向服务器发出请求, 服务器将返回不用的响应.
看到这里, 大家已经可以展开联想, 进行各种尝试, 看看会发生什么. 比如修该用户代理, 是不是
就能达到伪装身份的功能.
4. 请求方法
GET
GET 查询字符串是在GET请求的URL中发送的
GET 请求可被缓存
GET 请求保留在浏览器历史记录中
GET 请求可被收藏为书签
GET 请求不应在处理敏感数据时使用
GET 请求有长度限制, 一般URL最大长度为2048
GET 请求只应当用于取回数据
POST
POST 查询字符串是在POST请求的HTTP消息主体中发送的
POST 请求不会被缓存
POST 请求不会保留在浏览器历史记录中
POST 不能被收藏为书签
POST 请求对数据长度没有要求
其他 HTTP 请求方法
HEAD - 与GET相同, 但只返回HTTP报头, 不返回文档主体.
PUT - 用来传输文件.
DELETE - 删除服务器端指定资源.
OPTIONS - 返回服务器支持的HTTP方法.
服务器端支持哪些HTTP方法, 由服务器端的配置决定.
5. 请求报文首部
下面简单列举一些, HTTP请求报文首部字段及其含义.
Host 请求资源所在服务器
Cache-Control 控制缓存的行为
Date 创建报文的日期时间
Upgrade 升级为其它协议
Via 代理服务器的相关信息
Warning 错误通知
Accept 用户代理和处理的媒体类型
Accept-Charset 优先的字符集
Accept-Encoding 优先的的内容编码
Accept-Language 优先的语言
If-Modified-Since 比较资源的更新时间
Range 实体的字节范围请求
User-Agent 用户代理信息 6. 响应状态码
HTTP状态码比较重要, 通过它可以很方便的得知HTTP请求的返回结果, 标记服务器的处理是否正常,
出现了什么错误等.HTTP状态码出现在响应报文首部的第1行.
状态码的类别
1xx Informational(信息性状态码) 请求成功接受, 正在处理中.
2xx Successful(成功状态码) 请求正常处理完毕.
3xx Redirection(重定向状态码) 需要附加的操作以完成请求.
4xx Client Error(客户端错误状态码) 请求的语法等不正确, 服务器端无法处理.
5xx Server Error(服务器内部错误) 请求语法应该正确, 但是服务器内部出现了某种错误.13个常用HTTP状态码简要介绍
200 OK 请求被正常处理
204 No Content 请求被正常处理, 但不返回实体部分
206 Partial Content 返回指定范围的实体内容
301 Moved Permanently 永久性重定向
302 Found 临时性重定向
304 Not Modified 资源未修改, 直接使用缓存
307 Temporary Redirect 临时性重定向
400 Bad Request 请求报文中存在语法错误
403 Forbidden 请求被服务器拒绝
404 Not Found 服务器上找不到请求的资源
408 Request Timeout 请求超时
500 Internal Server Error 服务器内部错误
503 Service Unavailable 服务器暂时无法提供服务7. 响应报文首部
下面简单列举一些, HTTP响应报文首部字段及其含义.
Accept-Ranges 是否接受字节范围请求
ETag 资源的匹配信息
Location 令客户端重定向至指定URI
Server HTTP服务器的安装信息
Allow 资源可支持的HTTP方法
Content-Encoding 实体主体适用的编码方式
Content-Language 实体主体的自然语言
Content-Length 实体主体的大小(单位: 字节)
Content-Type 实体主体的媒体类型
Content-Range 实体主体的位置范围
Expires 实体主体过期的日期时间
Last-Modified 资源最后修改日期时间 8. HTTP特点及瓶颈
特点
- 应用HTTP协议, 必定一端是客户端而另一端是服务器端.
- 请求必定是客户端发出而服务器端回复响应.
- HTTP是一种不保存状态, 即无状态(stateless)协议.
瓶颈
- 一条连接上只可发送1个请求.
- 请求只能从客户端开始. 客户端不可以接收除响应以为的指令.
- 请求/响应首部未经压缩就发送. 首部信息越多, 延迟越大.
- 发送冗长的首部. 每次互相发送相同的首部造成的浪费较多.
- 可任意选择数据压缩格式. 非强制压缩发送.
解决方法
Ajax技术可以异步发送HTTP请求, 并实现局部更新页面.
Comet技术可以把从客户端收到的请求暂时挂起(延迟响应). 可以实现推送功能.
WebSocket可以实现浏览器和服务器的全双工通信.
参考链接
https://tools.ietf.org/html/rfc7231#page-49
https://tools.ietf.org/html/rfc7231
https://tools.ietf.org/html/rfc3986
https://en.wikipedia.org/wiki/Uniform_Resource_Identifier#Syntax
http://www.w3school.com.cn/tags/html_ref_httpmethods.asp


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!