
mysql系列04---索引及性能分析
1、索引的结构
mysql索引的数据结构,对经典的B+Tree进行了优化,在原B+Tree上增加了一个指向相邻叶子结点的链表指针,就形成了一个带有顺序指针的B+Tree,提高了区间访问的性能。

选择B+Tree的优点:
a、相对于二叉树,层级更少,搜索效率更高
b、相对于B-Tree,B+Tree只在叶子节点上存储数据,而B-Tree在非叶子节点上也存了数据,这样存储的键减少,层级更高。
c、hash索引不支持排序和范围操作。
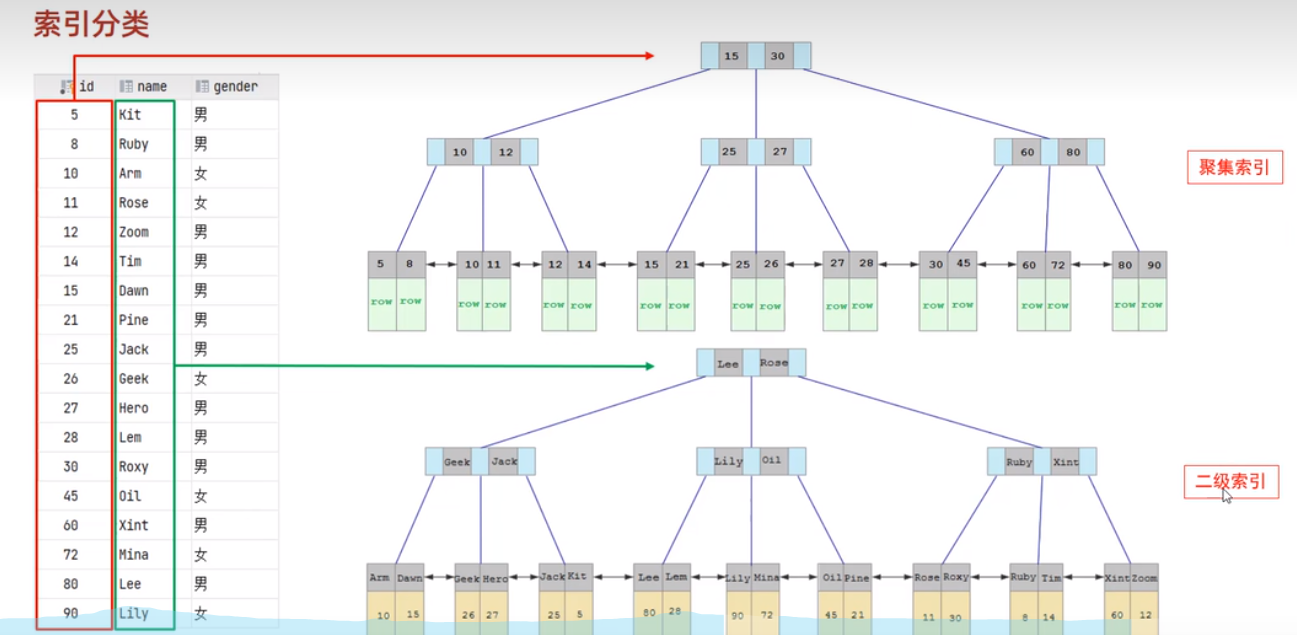
2、索引的分类
聚集索引:又叫主键索引,叶子节点保存这一行的数据
非聚集索引:又叫常规索引、二级索引,叶子节点保存这一行的主键
3、性能分析工具---explain
a、使用方式:在select语句前加上explain
b、执行计划各字段的含义:

id: 表的执行顺序,值相同执行顺序从上到下,值越大越先执行。
select_type:表示select的类型,simple表示单表查询;primary表示主查询也就是最外层的查询;union表示join的表;SUBQUERY子查询
type: 连接类型,性能由好到差的连接类型:NULL、system、const、eq_ref、ref、range、index、all
NULL不访问任何表
system访问系统表
const使用主键索引
eq_ref唯一索引
ref非唯一索引
range
index虽然用了索引,但全遍历所有的索引
all全表扫描
possible_keys:可能用到的索引
key:实际用到的索引
key_len:索引字段的长度
rows:扫描的行数,只是一个估值,并不太准确
filtered:返回的行数占总行数的百分比,值越大越好
extra:额外的信息
4、使用规则
最左前缀法则:主要是针对联合索引的顺序
索引失效的原因:
a、在索引字段上计算;
b、字符串不加单引号;
c、头部模糊匹配;
d、or条件前如有索引,后面条件没有索引,则前面索引失效;
e、mysql评估扫描全表比使用索引快,则不会走索引
5、设计原则

 浙公网安备 33010602011771号
浙公网安备 33010602011771号