

Erlang 进程被抢占的条件——一个进程长时霸占调度器的极端示例
最近研究 binary 的实现和各种操作对应的 beam 虚拟机汇编指令,发现有一些指令序列是不可重入的,比如说有的指令构造一个上下文(也就是某种全局状态),然后下一条指令会对这个上下文做操作(具体的场景示例参见这篇博文)。而上下文是调度器内部私有的全局变量。而我们一直在说,Erlang 调度器是抢占式调度器,进程耗光了 reduction 配额之后就会被抢占,那么调度器是怎么保证不可重入的指令序列不会被破坏呢?
关键在于,Erlang 调度器的抢占只会发生在一些特定的点上,像上面的指令序列之间是不会发生抢占的。
在 beam_emu.c 文件中,上下文切换(抢占必然要上下文切换)是通过 Dispatch()、Dispatchx() 和 Dispatchfun() 三个宏完成的,暂不用纠缠这些宏的区别和细节。比如说第一个宏 Dispatch():
1 #define DispatchMacro() \ 2 do { \ 3 BeamInstr* dis_next; \ 4 dis_next = (BeamInstr *) *I; \ 5 CHECK_ARGS(I); \ 6 if (FCALLS > 0 || FCALLS > neg_o_reds) { \ 7 FCALLS--; \ 8 Goto(dis_next); \ 9 } else { \ 10 goto context_switch; \ 11 } \ 12 } while (0) 13 14 # define Dispatch() DispatchMacro()
在 if 语句的 else 分句部分,可以看出 FCALLS 不够了就要 goto 到 context_switch,FCALLS 表示剩余的 reduction 数,context_switch 那里就要调用调度器切换进程了。
在这个文件中搜索一下,差不多可以看出哪些地方调用了这些宏,比如说下面几条和函数调用相关的指令:
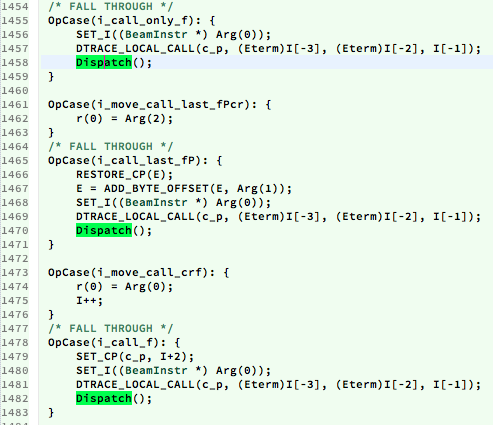
基本上都是和函数调用相关的指令,还有 call_bif,apply 之类的。这说明一个关键点:那就是 Erlang 虚拟机不会在任意指令之间或指令中抢占进程,而是在特定的点会发生抢占。
好消息是,Erlang 的设计使得 Erlang 会经常到达这些特定的点。比如说,Erlang 中没有循环结构,循环是通过递归调用自己实现的,那么这就可以保证超长的“循环”可以被抢占,而这在其他非函数式语言中可能就不好实现了。
再举一个例子,比如说前一篇博文提到的 binary comprehension,代码如下:
1 bc(Input) -> 2 << <<0, 1, 2, Bin:8/binary>> || <<Bin:8/binary>> <= Input >>.
我一开始担心,这一行中间也没有任何调用,要是 Input 很大该怎么办呢?会不会导致霸占调度器时间过长?不过看了编译器生成的汇编码就不用担心了:

可以看到,在第 12 步,有一条 call_only 指令。尽管第 8 到第 11 步中间的那些指令的序列在 Erlang 虚拟机看来是“原子”的,不会被打断,但是第 12 步就有可能发生抢占。
但是要特别注意的是,我们不能就此完全放心了,中间的这些指令可都是不消耗 reduction 的啊,这些指令还涉及到复制操作,所以如果复制的时间很长,那么这个函数霸占调度器的时间也会更长了。
下面举一个很变态的例子:
1 binary_append_longrun(Bin0) -> 2 Bin1 = <<Bin0/binary, Bin0/binary, Bin0/binary, Bin0/binary>>, 3 Reds1 = erlang:process_info(self(), reductions), 4 Bin2 = <<Bin1/binary, Bin1/binary, Bin1/binary, Bin1/binary>>, 5 Reds2 = erlang:process_info(self(), reductions), 6 Bin3 = <<Bin2/binary, Bin2/binary, Bin2/binary, Bin2/binary>>, 7 Reds3 = erlang:process_info(self(), reductions), 8 Bin4 = <<Bin3/binary, Bin3/binary, Bin3/binary, Bin3/binary>>, 9 Reds4 = erlang:process_info(self(), reductions), 10 Bin5 = <<Bin4/binary, Bin4/binary, Bin4/binary, Bin4/binary>>, 11 Reds5 = erlang:process_info(self(), reductions), 12 Bin6 = <<Bin5/binary, Bin5/binary, Bin5/binary, Bin5/binary>>, 13 Reds6 = erlang:process_info(self(), reductions), 14 Bin7 = <<Bin6/binary, Bin6/binary, Bin6/binary, Bin6/binary>>, 15 Reds7 = erlang:process_info(self(), reductions), 16 Bin8 = <<Bin7/binary, Bin7/binary, Bin7/binary, Bin7/binary>>, 17 Reds8 = erlang:process_info(self(), reductions), 18 Bin9 = <<Bin8/binary, Bin8/binary, Bin8/binary, Bin8/binary>>, 19 Reds9 = erlang:process_info(self(), reductions), 20 Bin10 = <<Bin9/binary, Bin9/binary, Bin9/binary, Bin9/binary>>, 21 Reds10 = erlang:process_info(self(), reductions), 22 Bin11 = <<Bin10/binary, Bin10/binary, Bin10/binary, Bin10/binary>>, 23 Reds11 = erlang:process_info(self(), reductions), 24 Bin12 = <<Bin11/binary, Bin11/binary, Bin11/binary, Bin11/binary>>, 25 Reds12 = erlang:process_info(self(), reductions), 26 Bin13 = <<Bin12/binary, Bin12/binary, Bin12/binary, Bin12/binary>>, 27 Reds13 = erlang:process_info(self(), reductions), 28 Bin14 = <<Bin13/binary, Bin13/binary, Bin13/binary, Bin13/binary>>, 29 Reds14 = erlang:process_info(self(), reductions), 30 Bin15 = <<Bin14/binary, Bin14/binary, Bin14/binary, Bin14/binary>>, 31 Reds15 = erlang:process_info(self(), reductions), 32 Bin16 = <<Bin15/binary, Bin15/binary, Bin15/binary, Bin15/binary>>, 33 Reds16 = erlang:process_info(self(), reductions), 34 Res = {Reds1, Reds2, Reds3, Reds4, Reds5, Reds6, Reds7, Reds8, Reds9, Reds10, Reds11, Reds12, Reds13, Reds14, Reds15, Reds16, byte_size(Bin16)}, 35 Res.
这个变态的函数接受一个 binary Bin0 作为参数。然后 Bin1 变成 4 个 Bin0那么大,Bin2 变成 4 个 Bin1 那么大,以此类推,最后 Bin16 就有 \(4^{16}\) 个 Bin0 那么大了。Bin0 是 1 字节的话,Bin16 就有 4G 字节那么大。Bin15 有 1G 字节那么大。在第 32 行,即使有预分配内存的优化,这一行还得复制 3 次 1G 字节的数据。显然这是非常费时的操作。
为了观察 reduction 的变化,在中间安插了一些 bif 调用获得当前进程的 reduction 值。我们看一下运行结果:
461> spawn(fun() -> Res = bin_test:binary_append_longrun(<<0>>), io:format("~p~n", [Res]) end).
{{reductions,63},
{reductions,65},
{reductions,67},
{reductions,69},
{reductions,71},
{reductions,73},
{reductions,75},
{reductions,77},
{reductions,79},
{reductions,81},
{reductions,83},
{reductions,85},
{reductions,87},
{reductions,89},
{reductions,91},
{reductions,93},
4294967296}
<0.175.1>
在终端 spawn 了一个进程,让新进程去跑这个函数,跑完之后打印最后的结果。结果按下回车之后,shell 失去响应。等了好一阵子之后,才把结果打印出来。从结果可以看出,这个新创建的进程跑到结束也才用了几十个 reduction。而且,整个调度器都失去了响应。怎么说呢?如果调度器有响应的话,新建进程的 pid,也就是 spawn 的返回值,应该很快在 shell 中打印出来,但是直到新进程执行完了才打印出来。而且如果之前打开了 observer 或 etop 之类的工具,GUI 也是在这个进程执行期间没有反应的。可以说,这个进程在跑的时候,Erlang 就没法“实时”了,连“软实时”都没了。
当然,我们在实际写程序的时候不太可能会写出这样变态的极端情况。可是万一呢。。。有些情况下,例如追加特别大的 binary 的情况,而且需要反复执行多次的时候,这个进程扣的 reduction 并不多,所以这种进程可能会破坏系统的响应能力。
