
结对作业——第二次作业
结对作业——第二次作业
标签: 软工实践 结对项目
结对成员
031502404 陈邡
031502443 郑书豪
Github项目地址
数据生成
生成原理
使用C++的Json库对数据进行Json格式的输出。
students部分free_time:将空闲时间字符串分为三段字符串进行拼接。在常量字符串数组中存入周一到周日对应的字符串,每次随机取出一条作为字符串第一段。开始时间段和结束时间段使用随机数生成整数,再转为字符串,最后在适当位置加上字符拼接成目标字符串;student_no:将学号字符串按照各段表示的信息分段处理,各段使用随机数在规定范围内生成,再转化为字符串。其中,12位表示学院号,34位表示级数,56位表示专业号,7位表示班级号,89位表示班级内编号。这样可以保证生成全校各个学院各个班级的学生学号;applications_department:在常量字符串数组中存入各个部门对应的字符串,每次随机取出一条作为目标字符串;tags:在常量字符串数组中存入各个标签对应的字符串,每次随机取出一条作为目标字符串。departments部分event_schedules:与上文的free_time生成原理相同;member_limit:在规定范围内取随机数生成;department_no:在规定范围内取随机数生成;tags:与上文的tags生成原理相同。
考虑因素
students部分free_time:考虑到学生的正常作息时间,将空闲时间段的生成控制在8:00 a.m.~22:00 p.m.,学生空闲时间段设置为每段2小时,限制生成数量为10~20;student_no:根据FZU真实情况对各段的随机生成做了控制,更加贴近真实情况;applications_department:对每个学生的学生志愿部门生成做了去重处理,限制生成数量为1~5;tags:对每个学生的标签生成做了去重处理,限制生成数量为2~10。departments部分event_schedules:考虑到部门的正常活动习惯,将活动时间段的生成控制在8:00 a.m.~22:00 p.m.,部门活动时间段设置为每段1小时,限制生成数量为3~10;member_limit:纳新人数限制生成控制为10~15;department_no:对各部门的部门号生成做了去重处理;tags:对每个部门的标签生成做了去重处理,限制生成数量为2~5。
数据建模
类视图
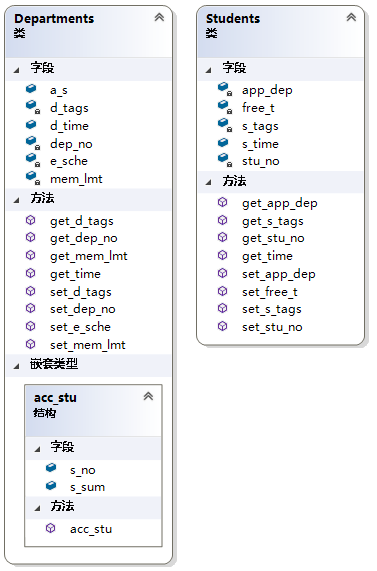
Students类
- 字段
free_t[]:空闲时间stu_no:学生号app_dep[]:志愿部门s_tags[]:标签s_time[][]:空闲时间(转为时间戳后)- 方法
set_xxxx():赋值函数(xxxx表示该类具体字段,下同)get_xxxx():取值函数get_time():将空闲时间字符串转为时间戳(简化后续计算等操作)
Departments类
- 字段
e_sche[]:活动时间mem_lmt:纳新人数dep_no:部门号d_tags:标签d_time[][]:活动时间(转为时间戳后)- 方法
set_xxxx():赋值函数get_xxxx():取值函数get_time():将空闲时间字符串转为时间戳(简化后续计算等操作)- 嵌套类型
acc_stu结构体,存储部门预纳入的学生编号(数组内编号,不是学生号)和优先级数值(下文说明),acc_stu()为初始化函数 s_no:学生编号s_sum:优先级数值
匹配思路
进行六轮匹配,前五轮在所有学生中进行志愿优先匹配,让大部分同学先进入自己志愿的部门。第六轮在未被任何部门纳入的学生中兴趣优先匹配。六轮匹配中均包含个人优先级淘汰机制,即在部门满员后,优先级较高的新进部员可以将部门中优先级最低的部员淘汰。
优先级(前五轮):按照志愿位置、时间匹配次数、标签匹配次数进行权重计算,权重分别为 10、5、2。
优先级(第六轮):按照时间匹配次数、标签匹配次数进行权重计算,权重分别为 1、2。
实现方式
流程图
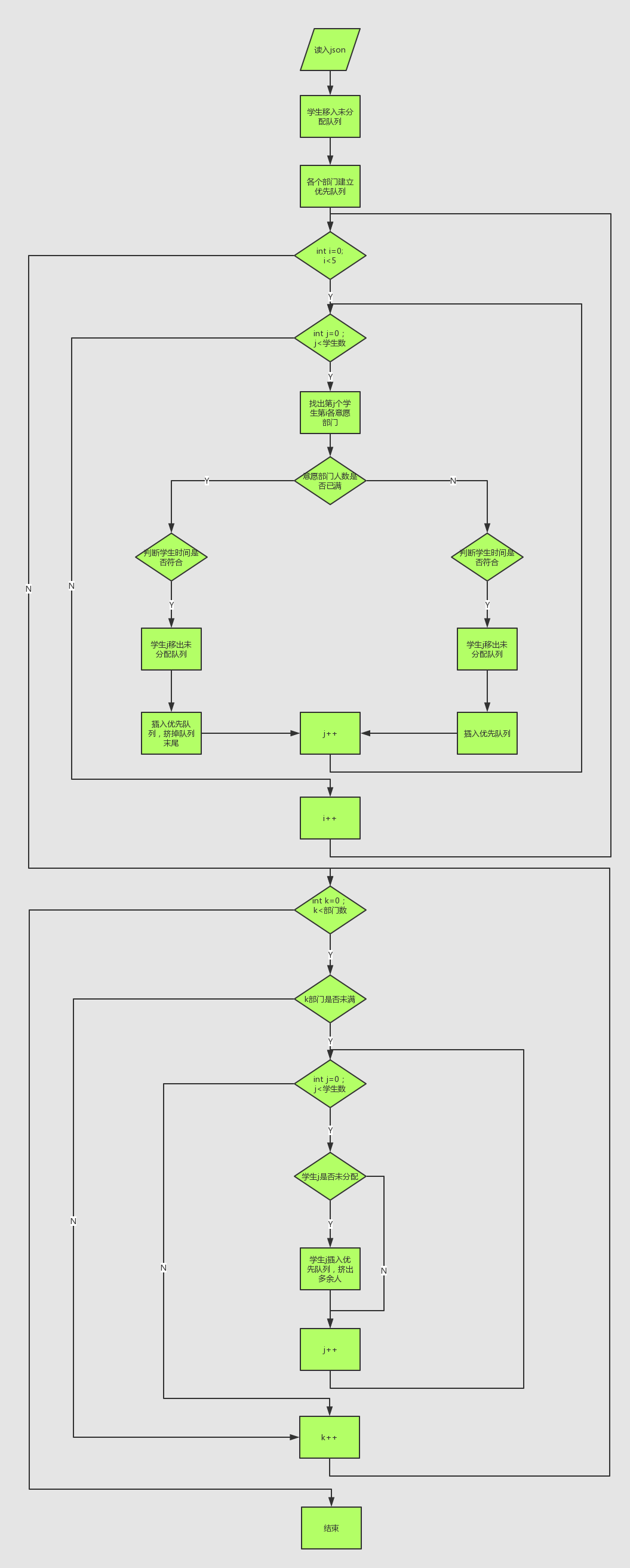
1.第一志愿匹配
将每个学生的第一志愿与部门进行匹配,若一名学生匹配且满足以下条件:
- 志愿部门纳新人数未满
- 学生空闲时间和部门活动时间至少匹配一次
则计算该生的优先级并将该学生加入志愿部门。
若志愿部门纳新人数已满,且该学生个人优先级大于志愿部门纳新中个人优先级最低的部员,则将优先级最低部员淘汰,并纳入该学生。
2.第二志愿匹配
将每个学生的第二志愿(若有)与部门进行匹配,与第一轮进行一样的纳新操作。
3.第三志愿匹配
将每个学生的第三志愿(若有)与部门进行匹配,与第一轮进行一样的纳新操作。
4.第四志愿匹配
将每个学生的第四志愿(若有)与部门进行匹配,与第一轮进行一样的纳新操作。
5.第五志愿匹配
将每个学生的第五志愿(若有)与部门进行匹配,与第一轮进行一样的纳新操作。
6.兴趣优先匹配
将所有未被任何部门纳入的学生与未满员的部门进行匹配,若一名学生匹配且满足以下条件:
- 志愿部门纳新人数未满
- 学生空闲时间和部门活动时间至少匹配一次
- 学生标签和部门标签至少匹配一次
则计算该生的优先级并将该学生加入志愿部门。
若志愿部门纳新人数已满,且该学生个人优先级大于志愿部门纳新中个人优先级最低的部员,则将优先级最低部员淘汰,并纳入该学生。
代码规范
参考结合了《构建之法》第4章中推荐的代码风格规范
1.缩进:4个空格
2.行宽:无限制
3.运算符间隔:一元运算符不做间隔处理,二元运算符前后各加一个空格

4.断行与空白{ }行:在多层嵌套结构中,某一层只有一条语句时,不加入{ }行,一条以上语句,”{“和”}“独占一行

5.分行:禁止多条语句和多个变量定义同行

6.命名:简化命名,使用下划线分隔命名前缀

7.大小写:变量单词全部小写,函数单词第一个字母大写,用动词或动宾结构组合词来表示


结果评估
| 次数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 平均 |
| 学生总数 | 300 | 300 | 300 | 300 | 300 | 300 | 300 | 300 | 300 | 300 | 300 |
| 目标纳新数 | 236 | 249 | 253 | 251 | 243 | 247 | 245 | 251 | 237 | 252 | 246 |
| 部门数 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
| 未匹配学生 | 22 | 15 | 18 | 14 | 23 | 9 | 15 | 27 | 20 | 20 | 18 |
| 未匹配部门 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 未匹配率 | 7.3% | 5.0% | 6.0% | 4.7% | 7.7% | 3.0% | 5.0% | 9.0% | 6.7% | 6.7% | 6.0% |
结对感受
这次结对编程过程中,完成了数据生成程序的主要编码以及匹配程序的部分编码过程。Get了用C++的Json库对Json进行读写的技能,进一步提高了人肉模拟算法过程找bug的能力(233,也和对友加深了感♂情。
最大的感受就是在编码的过程中,边写边注释是一个好习惯,否则不仅是你的对友,甚至是你自己回过神来都不知道自己之前写的是什么(233。注释清晰完整的代码在交付给对友时,可以大大缩短读代码的时间,而且没有注释的代码在debug时常常会让你做很多无用之功(别问我为什么知道,我不想说orz)。
总之结对编程的模式还是很不错的,两个人互相监督,谁都不能心安理得地摸鱼,可以很大程度提高编程的效率。
最后分享一点小小的建议,结对过程中两个人一定要多讨论,在思想上达成统一之后再开始编码,不要等对友编到一半了再去提出自己的异议,大改代码,浪费时间。还有就是做为对友应该对彼此负责,做好自己手头工作的前提下要尽量去帮助自己的对友,提高结对的效率。

