Python for Infomatics 第13章 网页服务一(译)
注:文章原文为Dr. Charles Severance 的 《Python for Informatics》。文中代码用3.4版改写,并在本机测试通过。
一旦利用程序通过HTTP协议获得并分析文档变得简单,那么开发生成一个特殊设计的、供其他程序使用的文档(不是在浏览器中显示HTML)的方法也不用花太长时间。
我们使用的通过网页互换数据的通用格式有这么两种:扩展标记语言XML和JSON(见 www.json.org)。XML已经应用多年,最适合互换文档样式数据。当程序之间只想互换字典、列表或者其它内部信息,它们使用JSON。我们将审视这两种格式。
13.1 扩展标记语言-XML
13.1 eXtensible Markup Language - XML
XML看起来和HTML非常相似,但是XML比HTML更加结构化,下面是一个XML文档的示例:
<person>
<name>Chuck</name>
<phone type="intl">
+1 734 303 4456
</phone>
<email hide="yes"/>
</person>
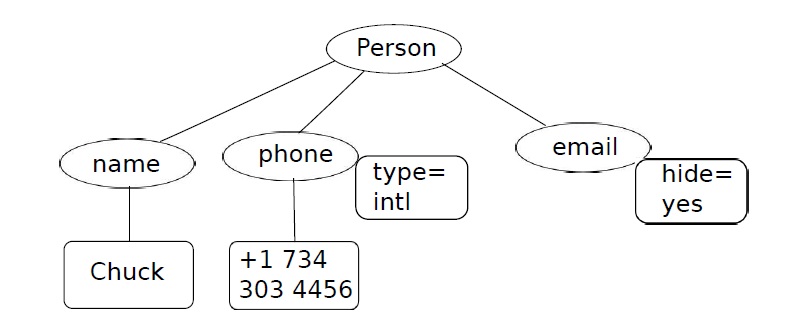
用结构树来看待XML往往比较有益。下图中顶层父标签是Person,phoned、name是父节点的孩子。
13.2 分析XML
下面是一个从XML中分析并抓取一些元数据的简单程序:
import xml.etree.ElementTree as ET data=''' <person> <name>Chuck</name> <phone type="intl"> +1 734 303 4456 </phone> <email hide="yes"/> </person>''' tree = ET.fromstring(data) print('Name:', tree.find('name').text) print('Attr:', tree.find('email').get('hide'))
运行代码的输出为:
Name: Chuck
Attr: yes
(译者注:不要将这个代码保存为xml.py,不然运行时将程序将报错:ImportError: No module named 'xml.etree'。因为在引入库文件时,Python将首先搜索当前目录,当前目录下命名为xml.py的文件或包将覆盖同名的标准库。)
调用fromstring将字符串显示的XML转换为XML节点树。当XML在树中时,我们有一系列的方法可以从XML抽取部分数据。
find函数搜遍XML树,并获取匹配指定标签的节点。每个节点可以有一些文本,一些属性(如hide),以及一些子节点。每个节点可以成为树的根节点。
当XML如本例一样非常的简单时,使用类似ElementTree这样的XML分析器有很多优势。事实证明,认定有效的XML有很多规则,使用ElementTree允许我们从XML提取数据而无需担忧语法规则。
13.3 遍循节点
XML经常有多个节点,我们必须编写一个循环来处理所有的节点。在下面的程序中,我们将遍循所有的user节点:
import xml.etree.ElementTree as ET input = ''' <stuff> <users> <user x="2"> <id>001</id> <name>Chuck</name> </user> <user x="7"> <id>009</id> <name>Brent</name> </user> </users> </stuff>''' stuff = ET.fromstring(input) lst = stuff.findall('users/user') print('User count:', len(lst)) for item in lst: print('Name ', item.find('name').text) print('Id ', item.find('id').text) print('Attribute ', item.get('x'))
findall方法获取一个以XML树方式表示user的子树列表。然后我们用一个for循序查看每个user节点,并打印出其name和id的文本信息,以及x属性。
程序的输出如下:
User count: 2
Name Chuck
Id 001
Attribute 2
Name Brent
Id 009
Attribute 7
13.4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号