

数据采集与融合技术作业2
Gitee作业链接:https://gitee.com/zheng-qijian33/crawl_project/tree/master/作业2
作业①
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库
代码
import requests
import sqlite3
from bs4 import BeautifulSoup
import logging
# 配置日志记录
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 获取指定城市的天气数据
def fetch_weather_data(city_code):
base_url = 'http://www.weather.com.cn/weather/'
full_url = f'{base_url}{city_code}.shtml'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.5211 SLBChan/112'
}
try:
response = requests.get(full_url, headers=headers)
response.raise_for_status()
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
weather_forecast = []
forecast_list = soup.find('ul', class_='t clearfix').find_all('li')
for day in forecast_list:
date = day.find('h1').text.strip()
weather = day.find('p', class_='wea').text.strip()
temp_high = day.find('span').text.strip() if day.find('span') else ''
temp_low = day.find('i').text.strip()
temp = f"{temp_high}/{temp_low}"
weather_forecast.append((date, weather, temp))
return weather_forecast
except requests.RequestException as e:
logging.error(f"Error fetching weather data for city code {city_code}: {e}")
return []
# 创建数据库和表
def setup_database():
conn = sqlite3.connect('weathers.db')
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS weather_forecast (
id INTEGER PRIMARY KEY AUTOINCREMENT,
city TEXT,
date TEXT,
weather TEXT,
temperature TEXT
)
''')
conn.commit()
return conn
# 保存天气数据到数据库
def save_weather_data(city, weather_data, conn):
cursor = conn.cursor()
for date, weather, temp in weather_data:
cursor.execute("INSERT INTO weather_forecast (city, date, weather, temperature) VALUES (?, ?, ?, ?)",
(city, date, weather, temp))
conn.commit()
# 显示数据库中的天气数据
def display_weather_data(conn):
cursor = conn.cursor()
cursor.execute("SELECT * FROM weather_forecast")
rows = cursor.fetchall()
print(f"{'序号':<5} {'地区':<10} {'日期':<15} {'天气信息':<20} {'温度':<15}")
for row in rows:
print(f"{row[0]:<5} {row[1]:<10} {row[2]:<15} {row[3]:<20} {row[4]:<15}")
def main():
# 定义城市和对应的代码
city_codes = {
'北京': '101010100',
'上海': '101020100',
'福州': '101230101',
'天津': '101030100'
}
# 创建数据库连接
conn = setup_database()
# 获取并保存每个城市的天气数据
for city, city_code in city_codes.items():
weather_data = fetch_weather_data(city_code)
if weather_data:
save_weather_data(city, weather_data, conn)
else:
logging.warning(f"No weather data for city {city}")
# 显示数据库中的天气数据
display_weather_data(conn)
conn.close()
if __name__ == '__main__':
main()
运行结果
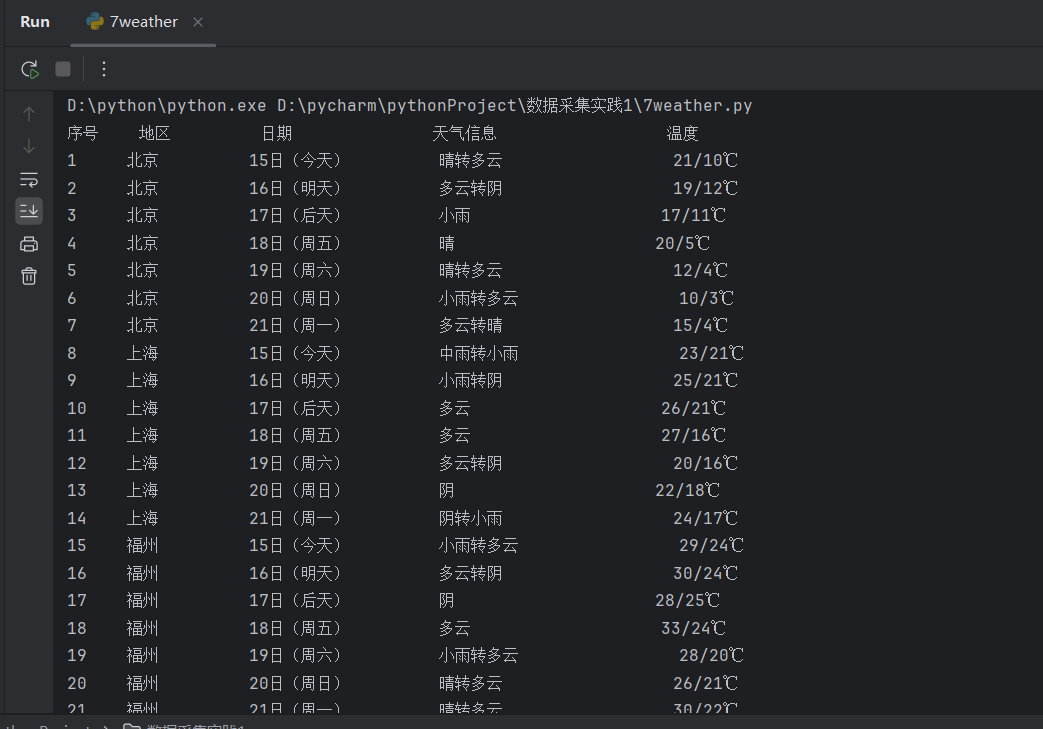
心得体会
编写这段天气数据抓取和存储的代码让我深刻体会到,良好的编程实践如模块化设计、错误处理、日志记录和数据验证对于构建健壮、可维护的应用程序至关重要。模块化设计使得代码更易于理解和扩展;错误处理确保了程序在面对异常情况时能够优雅地响应;日志记录为监控和调试提供了宝贵的信息;数据验证则保障了数据的准确性和完整性。
作业②
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
代码
import requests
import re
import sqlite3
# 用get方法访问服务器并提取页面数据
def getHtml(page,cmd):
url = ("http://66.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409097606620255823_1696662149317&pn=1&pz=20&po=1&np="+str(page)+
"&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&"+cmd+
"&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1696662149318")
r = requests.get(url)
pat = "\"diff\":\\[(.*?)\\]"
data = re.compile(pat, re.S).findall(r.text)
return data
def getOnePageStock(cmd, page):
# 提供的JSON数组
data = getHtml(page,cmd)
datas = data[0].split("},")
#分解每条股票
# 连接到SQLite数据库(如果不存在,则会创建一个新的数据库文件)
conn = sqlite3.connect('stock_data.db')
cursor = conn.cursor()
# 创建股票信息表
cursor.execute('''CREATE TABLE IF NOT EXISTS stock_info (
id INTEGER PRIMARY KEY,
stock_code TEXT,
stock_name TEXT,
stock_price REAL,
price_change REAL,
price_change_percent REAL,
volume INTEGER,
turnover REAL,
amplitude REAL,
highest REAL,
lowest REAL,
open_price REAL,
last_close REAL
)''')
# 解析JSON数组并将数据存储到数据库中
for item in datas:
# 使用字符串操作来提取键值对
stock_info = {}
pairs = item.split(',')
for pair in pairs:
key, value = pair.split(':')
key = key.strip('"')
value = value.strip('"')
stock_info[key] = value
# 提取需要的字段
stock_code = stock_info.get('f12', 'N/A')
stock_name = stock_info.get('f14', 'N/A')
stock_price = float(stock_info.get('f2', 0.0))
price_change_percent = float(stock_info.get('f3', 0.0))
price_change = float(stock_info.get('f4', 0.0))
volume = int(stock_info.get('f5', 0))
turnover = float(stock_info.get('f6', 0.0))
amplitude = float(stock_info.get('f7', 0.0))
highest = float(stock_info.get('f15', 0.0))
lowest = float(stock_info.get('f16', 0.0))
open_price = float(stock_info.get('f17', 0.0))
last_close = float(stock_info.get('f18', 0.0))
# 插入数据到数据库中
cursor.execute(
"INSERT INTO stock_info (stock_code, stock_name, stock_price, price_change_percent, price_change, volume, turnover, amplitude, highest, lowest, open_price, last_close) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)",
(stock_code, stock_name, stock_price, price_change_percent, price_change, volume, turnover, amplitude, highest,
lowest, open_price, last_close))
conn.commit()
# 查询股票信息
cursor.execute("SELECT * FROM stock_info")
# 获取查询结果
stocks = cursor.fetchall()
# 获取查询结果的列名
columns = [desc[0] for desc in cursor.description]
# 打印列标签
print("\t".join(columns))
# 打印股票信息
for stock in stocks:
# 打印每行数据
print("\t".join(map(str, stock)))
# 关闭数据库连接
conn.close()
page = 1
getOnePageStock("fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048", page)
运行结果
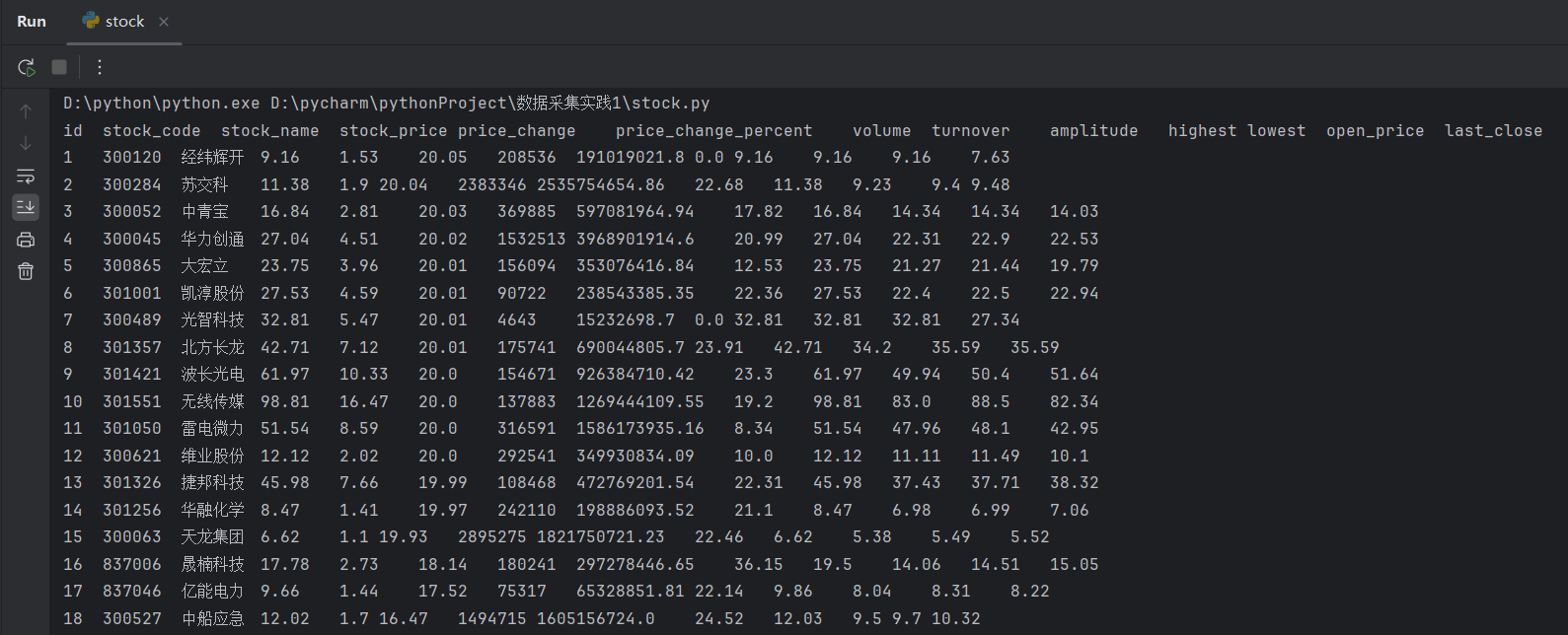
心得体会
在编写这段代码的过程中,我深刻体会到了网络数据抓取和解析的复杂性与挑战性。首先,通过使用谷歌浏览器的F12调试工具,我学会了如何监控网络请求,识别出股票数据加载时使用的具体API端点。这一步对于理解数据来源和结构至关重要。
分析API返回的JSON数据让我意识到,数据的结构化和非结构化部分需要仔细处理。通过使用正则表达式和字符串操作,我能够提取出所需的关键信息,并将其组织成适合存储和查询的格式。
在编写代码时,我意识到请求参数的选择对于获取正确的数据至关重要。通过调整URL中的参数,如f1和f2,我能够控制返回的数据范围和内容。这种灵活性使我能够根据需求定制数据抓取任务,提高了效率和准确性。
作业③
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
代码
import urllib.request
from bs4 import BeautifulSoup
import sqlite3
# 目标网页URL
your_url = 'https://www.shanghairanking.cn/rankings/bcur/2021'
# 使用 urllib 打开网页
response = urllib.request.urlopen(your_url)
html = response.read()
# 使用 BeautifulSoup 解析网页
soup = BeautifulSoup(html, 'html.parser')
# 定位到包含大学排名信息的部分
table = soup.find('table', {'class': 'rk-table'})
# 连接到SQLite数据库(如果数据库不存在则创建)
conn = sqlite3.connect('schools_rank.db')
cursor = conn.cursor()
# 创建表(如果尚未创建)
cursor.execute('''CREATE TABLE IF NOT EXISTS university_ranking
(rank TEXT, school_name TEXT, province_city TEXT, school_type TEXT, total_score TEXT)''')
# 遍历表格中的每一行
for row in table.find_all('tr')[1:]: # 跳过表头
cols = row.find_all('td')
rank = cols[0].text.strip()
school_name = cols[1].text.strip()
province_city = cols[2].text.strip()
school_type = cols[3].text.strip()
total_score = cols[4].text.strip()
# 插入数据到数据库
cursor.execute('''INSERT INTO university_ranking (rank, school_name, province_city, school_type, total_score)
VALUES (?, ?, ?, ?, ?)''', (rank, school_name, province_city, school_type, total_score))
# 提交事务
conn.commit()
# 查询数据库并打印所有记录
cursor.execute("SELECT * FROM university_ranking")
all_records = cursor.fetchall()
for record in all_records:
# 移除字符串中的换行符
cleaned_record = tuple(field.replace('\n', '') for field in record)
# 打印清理后的记录
print(cleaned_record)
# 关闭数据库连接
conn.close()
print("大学排名数据已保存到数据库")
运行结果
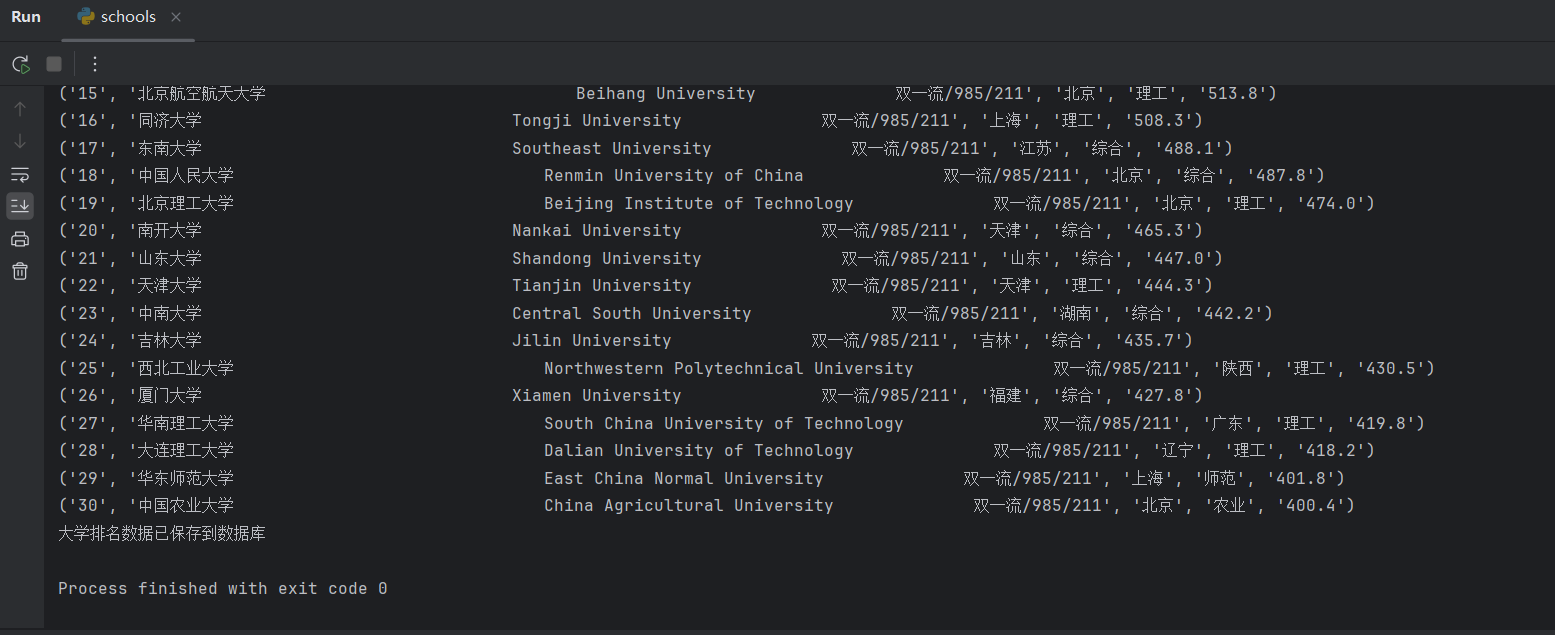
浏览器F12调试分析的过程录制Gif

心得体会
编写这段代码的过程中,我深刻体会到了网络数据抓取和解析的复杂性与挑战性。首先,通过分析目标网站的网络请求,我学会了如何识别和理解网站加载数据时使用的API端点。这一步对于理解数据的来源和结构至关重要。
在分析API返回的数据时,我意识到数据的结构化和非结构化部分需要仔细处理。通过使用BeautifulSoup库,我能够解析HTML内容并提取出所需的关键信息,如大学排名、学校名称、所在城市、学校类型和总分。
将数据存储到SQLite数据库中的过程让我认识到了数据持久化的重要性。通过创建表和插入数据,我确保了抓取到的信息可以被长期保存和查询,这对于后续的数据分析和应用是非常有用的。

