
数据采集与技术融合作业1
一、作业内容
作业①:
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
作业代码:
import urllib.request
from bs4 import BeautifulSoup
your_url = 'https://www.shanghairanking.cn/rankings/bcur/2020'
# 使用 urllib 打开网页
response = urllib.request.urlopen(your_url)
html = response.read()
# 使用 BeautifulSoup 解析网页
soup = BeautifulSoup(html, 'html.parser')
# 定位到包含大学排名信息的部分,这里假设信息在一个表格中
table = soup.find('table', {'class': 'rk-table'})
# 遍历表格中的每一行
for row in table.find_all('tr')[1:]:
cols = row.find_all('td')
rank = cols[0].text.strip()
school_name = cols[1].text.strip()
province_city = cols[2].text.strip()
school_type = cols[3].text.strip()
total_score = cols[4].text.strip()
#输出打印爬取结果
print(f" {rank.ljust(5)}{school_name.ljust(20)} {province_city.ljust(10)} {school_type.ljust(10)}{total_score}")
response.close()
运行结果:
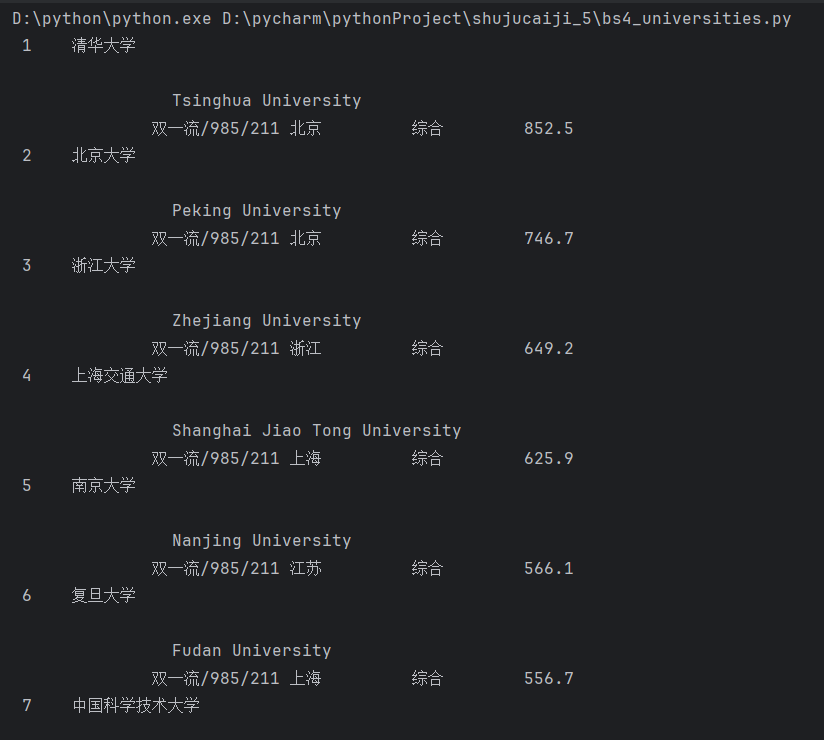
心得体会
通过实践,我学会了如何使用 urllib 和 BeautifulSoup 这两个强大的库来获取和解析网页数据。这个过程不仅加深了我对网络爬虫工作原理的理解,还锻炼了我的编程技能,特别是在数据提取和处理方面。我意识到,编写网络爬虫不仅需要对目标网页的结构有清晰的认识,还需要考虑到代码的可读性和可维护性
作业②:
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
作业代码:
import requests
from bs4 import BeautifulSoup
#定义一个函数用于获取网页内容
def get_html(url, headers):
try:
response = requests.get(url, timeout=30, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
return response.text
except Exception as e:
print(f"请求错误: {e}")
return None
#定义一个函数用于解析商品信息
def parse_product_info(html):
soup = BeautifulSoup(html, 'lxml')
products = []
for li in soup.find_all('li'):
title_tag = li.find('a', {'dd_name': '单品图片'})
price_tag = li.find('span', {'class': 'price_n'})
title = title_tag['title'].strip() if title_tag else ''
price = price_tag.text.strip() if price_tag else ''
if title:
products.append((title, price))
return products
def url_text_get(url, headers):
content = get_html(url, headers)
if content:
return parse_product_info(content)
return []
# 初始化URL变量
url = 'https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input'
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0'
}
# 获取网页内容并解析商品信息
products = url_text_get(url, headers)
# 打印商品名称和价格
print('序号\t商品名称\t\t价格')
for index, product in enumerate(products, start=1):
print(f'{index}\t{product[0]}\t\t{product[1]}')
运行结果
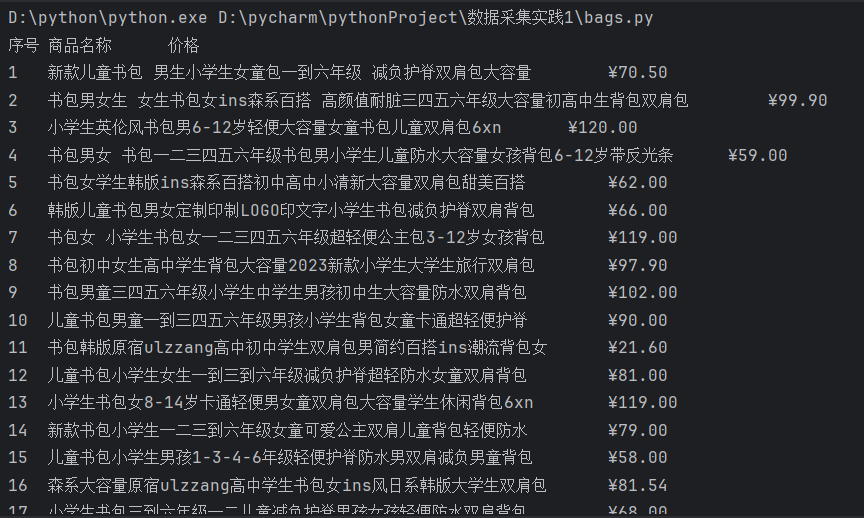
心得体会
在编写过程中,我特别注意到代码的结构和逻辑清晰度,确保每个函数都有明确的功能和目的。这不仅有助于代码的维护,也使得整个爬虫程序更加高效和易于理解。通过实践,我更加学会如何将理论知识应用到实际问题中。
作业③:
要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm )或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
作业代码
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
# 目标网址
url = 'https://news.fzu.edu.cn/yxfd.htm'
# 图片保存路径
save_dir = 'D:\\数据采集实践1\\福大网站图片'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 SLBrowser/9.0.3.5211 SLBChan/112'
}
# 发起请求获取网页内容
response = requests.get(url, headers=headers)
response.raise_for_status() # 确保请求成功
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有图片标签
img_tags = soup.find_all('img')
# 遍历所有图片标签
for img in img_tags:
# 获取图片的URL
img_url = img.get('src')
# 将相对URL转换为绝对URL
img_url = urljoin(url, img_url)
# 获取图片的文件名
img_name = os.path.basename(img_url)
# 检查文件扩展名是否为.jpg或.jpeg
if img_name.lower().endswith(('.jpg', '.jpeg')):
# 图片保存路径
img_path = os.path.join(save_dir, img_name)
# 发起请求下载图片
try:
img_data = requests.get(img_url, headers=headers).content
# 保存图片
with open(img_path, 'wb') as file:
file.write(img_data)
print(f"图片已下载:{img_path}")
except Exception as e:
print(f"下载图片失败:{img_url},错误信息:{e}")
print("所有.jpg和.jpeg图片下载完成。")
运行结果
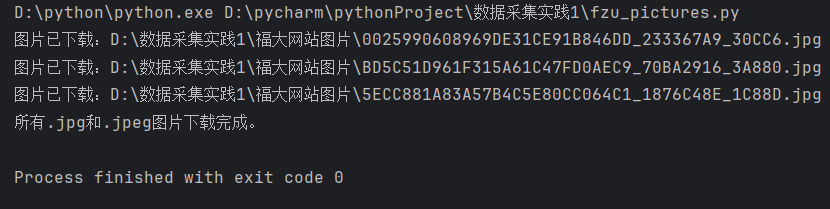
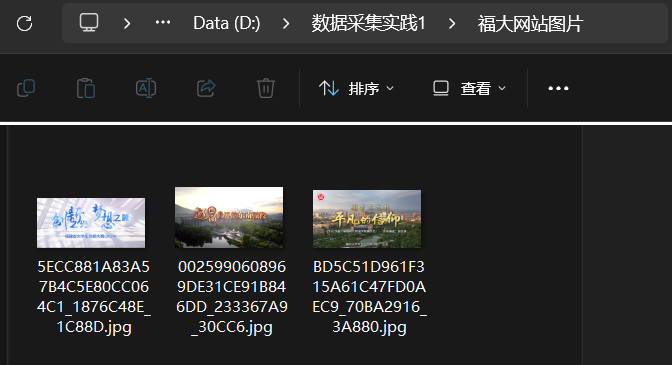
心得体会
编写这段代码让我体会到了网络爬虫在自动化下载网页图片方面的实用性和便捷性。通过实践,我学会了如何使用 requests 和 BeautifulSoup 库来获取和解析网页内容,并提取出图片链接。这个过程不仅加深了我对网络爬虫工作原理的理解,还锻炼了我的编程技能,特别是在数据提取和处理方面。我还学会了如何处理网络请求和解析过程中可能出现的异常情况,这对于编写稳定可靠的爬虫程序至关重要。

