
Django框架
安装Django
pip install django -U (-U表示安装最新版本)
前后端不分离的方式
后端直接返回html
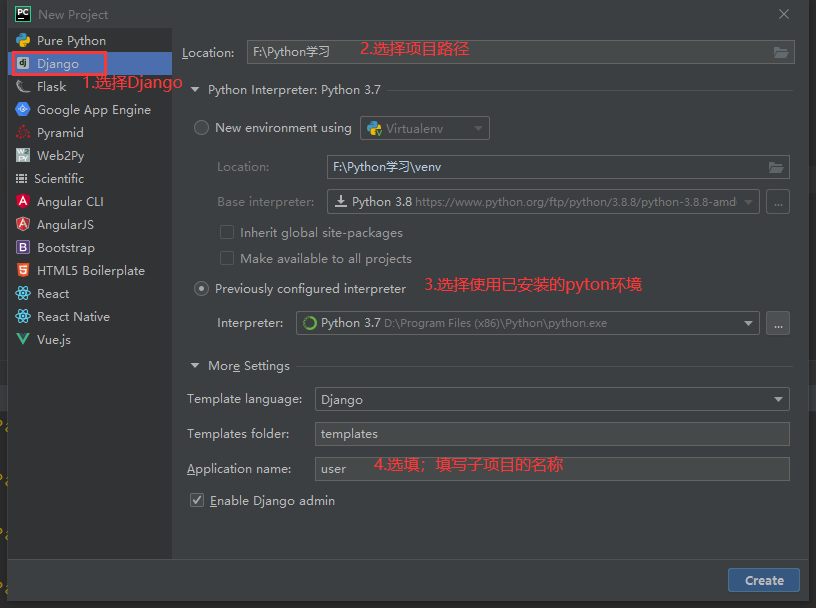
1.创建django项目
命令创建:django-admin startproject django_project (django_project为项目名)
用pycharm创建:
2.启动项目
cd dj_test
python manage.py runserver 默认端口号8000;
python manage.py runserver 8000 指定端口号启动
python manage.py runserver 0.0.0.0:8001 指定ip和端口启动,0.0.0.0可以让其它电脑可连接到开发服务器

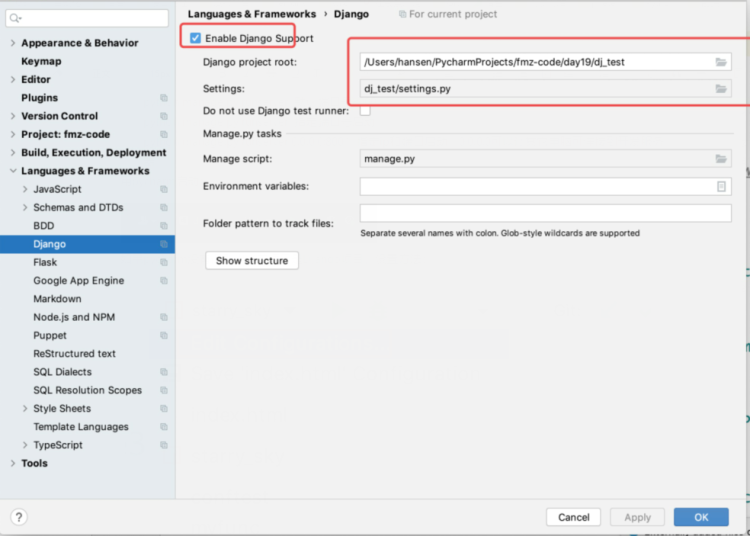
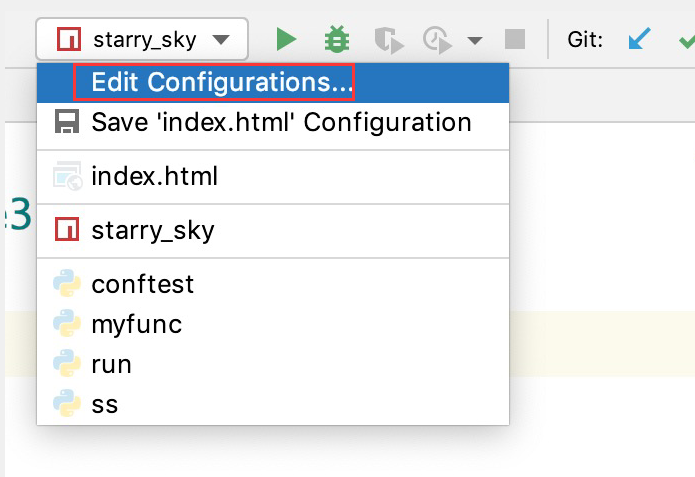
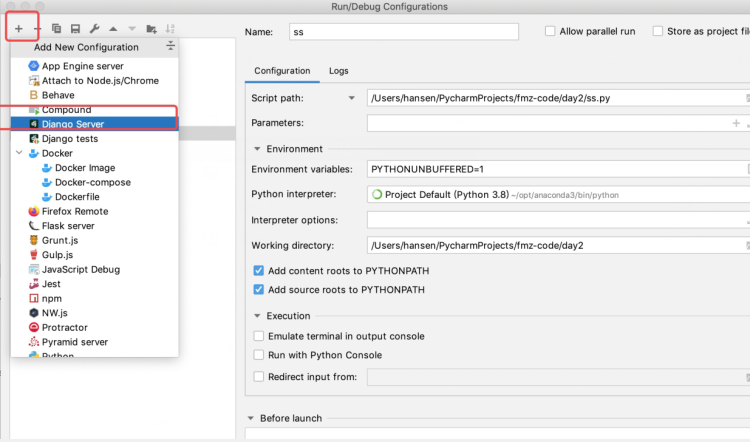
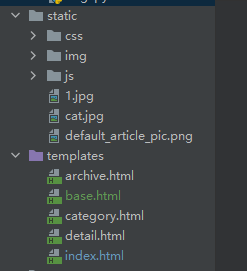
如果pycharm没有识别出当前项目是Django项目,依次按照下图进行设置:
3.项目目录结构
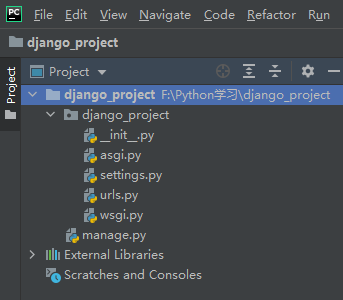
- django_project: 项目的容器。
- manage.py: 一个实用的命令行工具,可让你以各种方式与该 Django 项目进行交互。
- django_project/__init__.py: 一个空文件,告诉 Python 该目录是一个 Python 包。
- django_project/asgi.py: 一个 ASGI 兼容的 Web 服务器的入口,以便运行你的项目。
- django_project/settings.py: 该 Django 项目的设置/配置。
- django_project/urls.py: 该 Django 项目的 URL 声明; 一份由 Django 驱动的网站"目录"。
- django_project/wsgi.py: 一个 WSGI 兼容的 Web 服务器的入口,以便运行你的项目
- db.sqlit3 :启动后生成文件,为本地数据库
4.修改settings.py
LANGUAGE_CODE = 'zh-Hans'
TIME_ZONE = 'Asia/Shanghai'
USE_TZ = False5.创建子项目
python manage.py startapp user
目录结构如下:
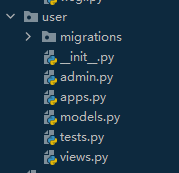
admin.py:Django自带的后台管理的配置内容
models.py:定义和数据库相关的内容,可以建表等
tests.py:可以写单元测试
views.py:写接口逻辑
将子项目user加入到settings中的INSTALLED_APPS中(如果是Django创建项目,已经自动添加,不需要再手动操作)
6.返回http响应
在views中写逻辑:
from django.shortcuts import render,HttpResponse def index(request): return HttpResponse('hello')
在urls.py中配置访问路径:
from user import views urlpatterns = [ path('admin/', admin.site.urls), path('hello', views.index()), ]
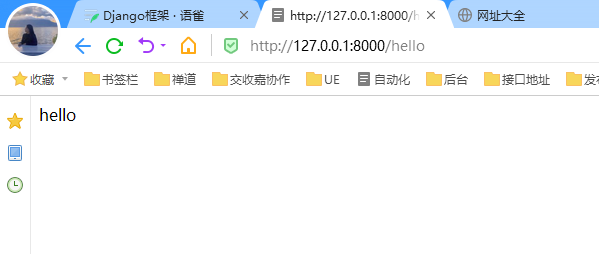
在浏览器中访问http://127.0.0.1:8000/hello即可访问到返回结果
7.返回html页面
STATICFILES_DIRS = [
BASE_DIR / "static",
]
from django.shortcuts import render,HttpResponse def index(request): return render(request,"index.html")
render函数作用是打开index.html文件返回给前端
然后和上面一样,在urls.py中配置访问路径
8.给前端返回变量
在views中定义变量并返回给前端
from django.shortcuts import render,HttpResponse def index(request): title="我的博客" return render(request,"index.html",{"title":title})
前端取值:
< title >{{ title }}
9.前端取值、循环、判断
在views中返回列表list给前端:
def index(request): article_list = ['python','java','linux','c++'] return render(request,"index.html",{"category_list ":category_list })
前端取值:
< ul class="list-group list-group-flush f-16">
{% for category in category_list %}
{% if not category.isdigit %}
< li class="list-group-item d-flex justify-content-between align-items-center pr-2 py-2">
< a class="category-item" href="/category/{{ category.id }}"
title="查看【{{ category }}】分类下所有文章">{{ category }}
< span class="badge text-center" title="当前分类下有{{ category }}篇文章">{{ category }}
{% endif %}
{% endfor %}
10.同步表结构到数据库
在models中写建表语句
1 from django.db import models 2 3 class Category(models.Model): 4 name = models.CharField(max_length=20, verbose_name="分类名称") 5 6 class Meta: 7 db_table = "category" #指定表名 8 9 # 下面2句加了在后台管理系统中显示赋值的表名 10 verbose_name = "分类表" 11 verbose_name_plural = verbose_name 12 #如果不加默认表名,表名为: app+_+category 13 14 # 这个函数加了之后可以在控制台看返回的结果更直观些 15 def __str__(self): 16 return self.name 17 18 class Article(models.Model): 19 title = models.CharField(max_length=50, verbose_name="文章标题") 20 content = models.TextField(verbose_name="文章内容") 21 img = models.ImageField(upload_to="static", default="static/img/cat.jpg", 22 null=True, blank=True) 23 24 view_count = models.IntegerField(default=0, null=True, blank=True, verbose_name="查看次数") 25 category = models.ForeignKey(Category, on_delete=models.CASCADE, verbose_name="归属分类") 26 create_time = models.DateTimeField(auto_now_add=True) 27 update_time = models.DateTimeField(auto_now=True) 28 29 # class Meta: 30 # db_table = "article" 31 # verbose_name = "文章内容" 32 # verbose_name_plural = verbose_name 33 # ordering = ['update_time'] 34 # #可以写多个字段,默认查询的时候按照什么来排序,默认是升序;如果字段前有负号,那么是降序排 -update_time 35 36 def __str__(self): 37 return self.title 38 39 on_delete有几种默认的值: 40 #models.CASCADE #把它对应的数据都删除 ,删除分类时把分类下的所有文章也删除 41 #models.DO_NOTHING #什么也不做 42 #models.SET_NULL #设置成空 43 #models.SET_DEFAULT(1) #设置一个默认值 44 #models.PROTECT #受保护的 45 #models.SET() 自定义
执行同步表结构命令
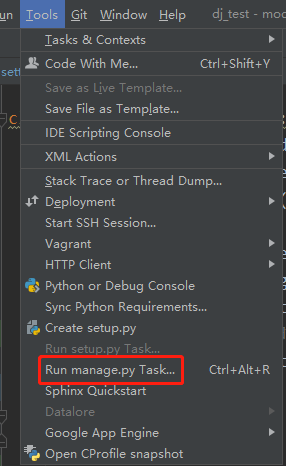
python manage.py makemigrations python manage.py migrate #或者加上app的名称执行命令 python manage.py makemigrations appname python manage.py migrate appname
上面2条命令也可以在pycharm识别当前项目时Django项目的前提下,在Tools--》Run manage.py Task达到同样效果
执行后会在user--》migrations文件夹下自动创建文件;修改表结构或者字段后也需要执行上面2条语句才生效
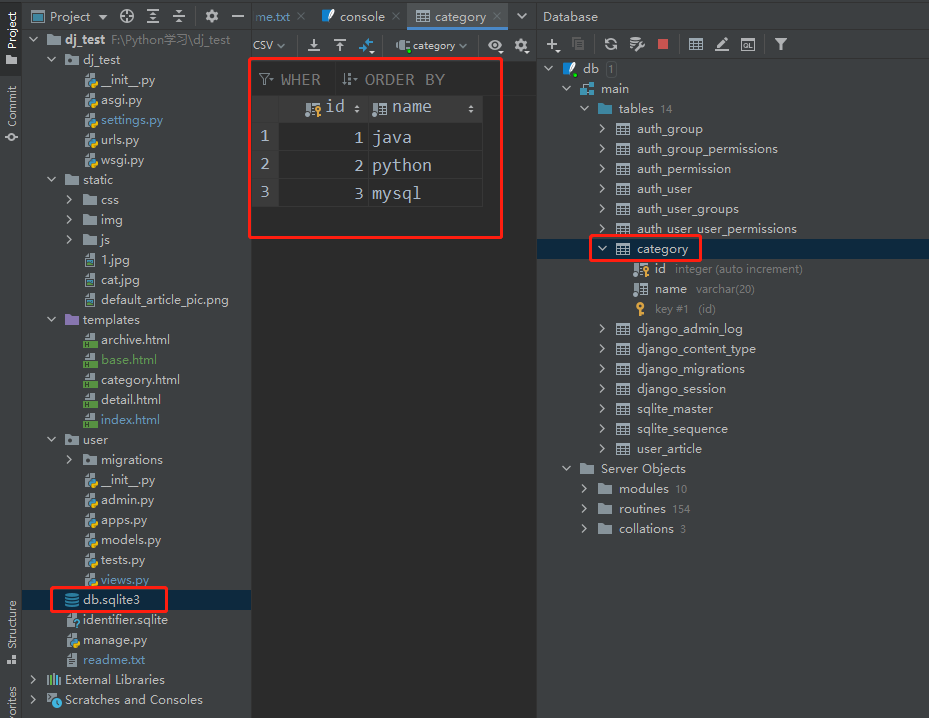
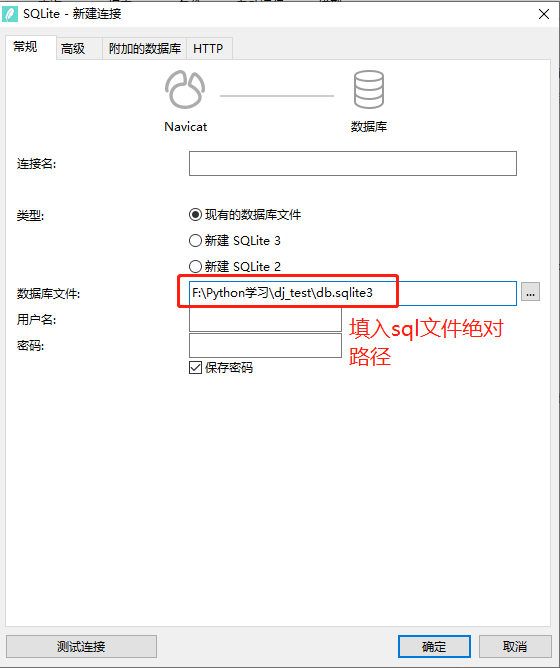
也可以用navicat连接数据库
连接方式:navicat--》连接--》SQLite,填入文件路径,连接即可
11.数据库增删改查
增加
a.在views.py中导入models,models中是表结构
from . import models
b.在views中定义方法
def model_test(request): # 增 # 第一种增加方式 # c=models.Category(name='Python') # c.save() # # 第二种增加方式 # models.Category.objects.create(name='Java') return HttpResponse('ok')
c.在urls.py中写入方法的路径
from user import views urlpatterns = [ path('model_test', views.model_test), ]
d.访问http://127.0.0.1:8000/model_test则会执行新增语句或者run当前py文件
查
def model_test(request): # 查 # 第一种查询,查询所有的 # ret = models.Category.objects.all() # print(ret) # print(ret[0]) #查询某个条件下的 # ret2=models.Category.objects.filter(name='Java') # print(ret2) #查询某个条件,get查询时如果有多条或返回为空,会报错,只能返回一条时才正确 # ret3= models.Category.objects.get(name='Java') # print(ret3) # print(ret3.id) # print(ret3.name)
orm其他查询
# orm其他查询 from django.db.models import Q # ret = models.Article.objects.filter(id__in=[1, 2,3]) #in,id在[1,2,3]中的 # ret = models.Article.objects.filter(id=2,title='文章2') #and,id=2并且titile='文章2'的 # ret = models.Article.objects.filter(id__in=[1, 2, 3]).order_by('update_time') #排序 # ret = models.Article.objects.filter(id__in=[1, 2, 3]).order_by('update_time','author_id') #按照多个字段排序 # ret = models.Article.objects.filter(id__in=[1, 2, 3]).order_by('-update_time') #倒序 # ret = models.Article.objects.filter(id__in=[1, 2, 3]).order_by('update_time','author_id').reverse() #倒序 # ret = models.Article.objects.first() #第一个 # ret = models.Article.objects.last() #最后一个 # ret = models.Article.objects.all().values("id","title","img","view_count") #查询部分字段的数据,将结果转成字典 # ret = models.Article.objects.all().values("id","title","img","view_count").distinct() #去重 # ret = models.Article.objects.all().values_list("id","title","img","view_count") #将结果转为list # print(ret) # print(models.Article.objects.filter(view_count__gt=0)) #浏览次数大于0的 # print(models.Article.objects.filter(view_count__lt=0)) #浏览次数小于0的 gte 大于等于 lte 小于等于 # print(models.Article.objects.exclude(view_count=0)) # 不包含 # print(models.Article.objects.filter(title__contains="谁")) #__contains 包含,相当于like # print(models.Article.objects.filter(Q(view_count=1) | Q(view_count=2))) # or
orm外键查询、多对多、1对1
一对多外键查询
orm为对象关系映射
1个分类下有多个文章,文章中有个外键category,通过category对象查询1个分类下所有的文章
在views.py中查询写法:
# c = models.Category.objects.get(id=1) # c.article_set.all() #分类id为1下的所有文章 # c.article_set.count() #分类id为1下的所有文章数量 # c.article_set.filter() #分类id为1下进行过滤查询
在前端html文件中写法:
<span class="badge text-center" title="当前分类下有{{ category.article_set.count }}篇文章">{{ category.article_set.count }}</span>
多对多操作ManyToManyField
文章和标签是多对多的关系
tag表结构如下:
class Tag(models.Model): name = models.CharField(max_length=20,verbose_name="标签名称") class Meta: db_table = "tag" verbose_name="文章标签" verbose_name_plural = verbose_name def __str__(self): return self.name
在文章表中增加外键
tag = models.ManyToManyField(Tag, blank=True, null=True, verbose_name="文章标签")
多对多表相互查询
import os,django # 要操作数据库,需要将当前自己创建的python文件加入到系统设置中 os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'dj_test.settings') django.setup() from user import models # 通过article表操作tag a = models.Article.objects.get(id=1) #获取id=1的文章 # print(a.tag.all()) #获取文章的所有tag # print(a.tag.filter(name="js")) #获取文章下的名称为js的tag # print(a.tag.count()) #获取文章下的tag数量 # a.tag.add(3) #给文章增加新的id为3的tag # a.tag.create(name="高端") #创建一个新的标签,并且建立关系 # a.tag.remove(6) #删除关系中tag的id=1的关系 # 也可以通过tag表操作article表 t = models.Tag.objects.get(id=3) # print(t.article_set.all()) #获取当前tag下的所有文章 # print(t.article_set.first()) #第一个文章 # print(t.article_set.last()) #最后一个文章 # print(t.article_set.count()) #所有数量 # print(t.article_set.filter(title='11')) #通过条件查询 # t.article_set.add(2) #添加文章id=2与当前tag对应关系 # t.article_set.remove(2) #删除id=2文章与当前tag对应关系 # t.article_set.create(title="多对多关系",content="多对多关系1111",category_id=2) #创建一个新文章,并且建立关系
一对多操作OneToOneField
建表方式: author = models.OneToOneField(Author, verbose_name="作者", on_delete=models.CASCADE, null=True, blank=True) 查询与上面查询无异
改
#多个修改,用update
# models.Category.objects.filter(name='Java').update(name='java')
#单个修改
# p=models.Category.objects.get(name='Python')
# p.name='mysql'
# p.save()删除
# 多个删除
# models.Category.objects.all().delete()
# models.Category.objects.filter(name='java').delete()
# 单个删除
# p = models.Category.objects.get(name='mysql')
# p.delete()12.从数据库中取值显示到前端
取值
def index(request): # category_list = models.Category.objects.all() article_list = models.Article.objects.all() return render(request,"index.html",{"article_list":article_list})
前端显示
<ul class="list-group list-group-flush f-16"> <!-- 循环--> {% for category in category_list %} <!--判断--> {% if not category.name.isdigit %} <li class="list-group-item d-flex justify-content-between align-items-center pr-2 py-2"> <a class="category-item" href="/category/{{ category.id }}" title="查看【{{ category.name }}】分类下所有文章">{{ category.name }}</a> <span class="badge text-center" title="当前分类下有{{ category.article_set.count }}篇文章">{{ category.article_set.count }}</span> </li> {% endif %} {% endfor %} </u
注意:如果是图片要用{{ article.img.url }}才能显示
< p class="d-none d-sm-block mb-2 f-15">{{ article.content | slice:10}}
slice:10 表示列表缩略显示前10个字
前端需要传值的情况
前端:
<a class="category-item" href="/category/{{ category.id }}"
def article(request,id):
# 前端访问路径:http://127.0.0.1:8000/artcile/1
article = models.Article.objects.get(id=id)
return render(request,'detail.html',{"article":article})
urlpatterns = [
path('article/<int:id>', views.article),
path('category/<int:id>', views.category),
]
14.Django_admin用法
Django_admin是Django自带的后台管理系统
在urls中已经配好了Django_admin的访问路径
from django.contrib import admin urlpatterns = [ path('admin/', admin.site.urls), ]
访问http://127.0.0.1:8000/admin,输入创建的用户名和密码即可
在admin.py文件中导入models中的表,即可在后台管理系统中自行添加表和数据
from django.contrib import admin from . import models admin.site.register(models.Category) admin.site.register(models.Article)
a.页面加搜索和过滤功能
没加之前的效果没加之前的效果
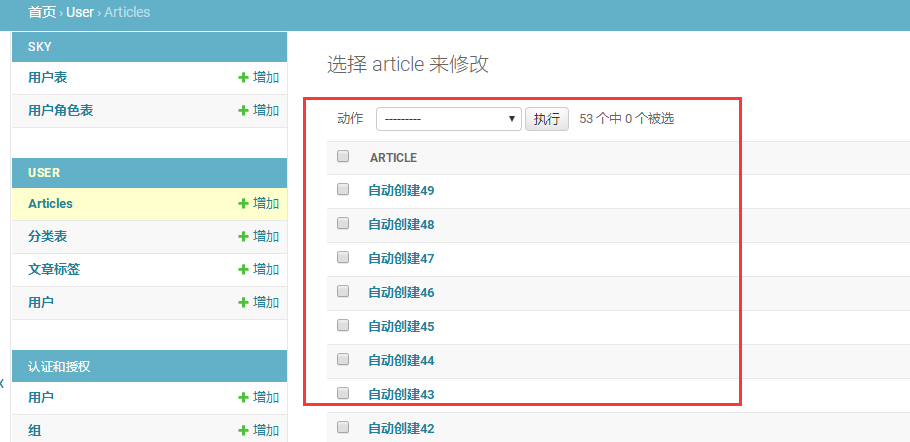
在admin.py中加搜索、过滤、分页等功能
class ArticleAdmin(admin.ModelAdmin): list_display = ['title', 'content','img', 'category', 'author','create_time'] #展示的字段 list_filter = ['tag','category'] #筛选 search_fields = ['title', 'content'] #搜索 list_per_page = 5 #每页显示条目数 admin.site.register(models.Article,ArticleAdmin) #在对应的models上加上定义的内容
加上以后效果
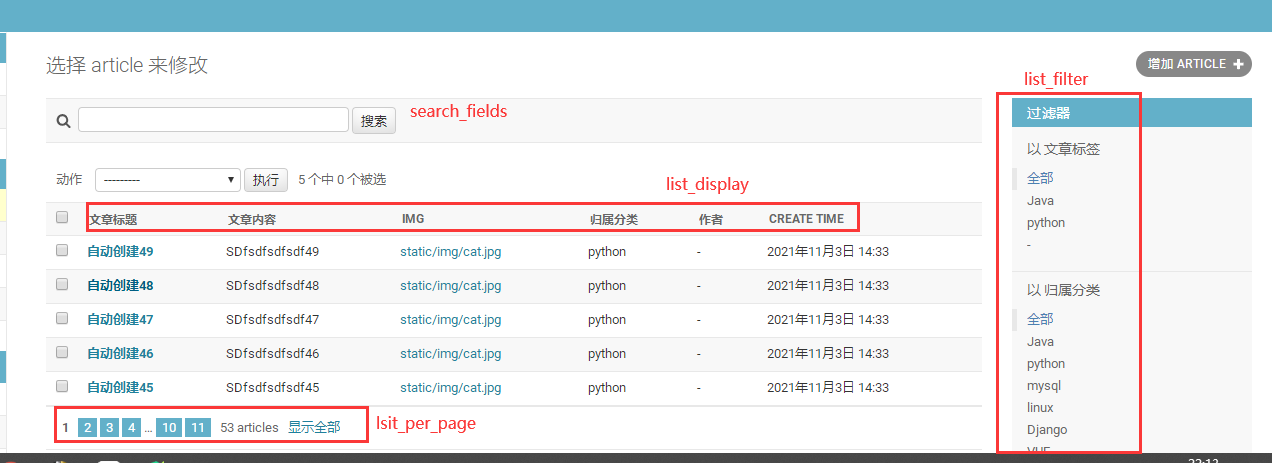
b.自定义admin动作
在admin.py中增加动作的代码
def reset_password(modeladmin,request,queryset): queryset.update(password="nihao123") # for q in queryset: #queryset是一个list,q是对对象 # print(q.nick) # print(q.email) # q.nick = "周杰伦" # q.save() reset_password.short_description = "重置密码" #菜单的名字
在自定义的类中增加action的list: actions = [reset_password]
class UserAdmin(admin.ModelAdmin): list_display = ['id', 'phone','email', 'nick', 'create_time'] #展示的字段 list_filter = ['roles','phone'] #筛选 search_fields = ['nick','phone','phone'] #搜索 list_per_page = 5 #每页显示条目数 actions = [reset_password] admin.site.register(models.UserRole) admin.site.register(models.User,UserAdmin)
加上以后效果
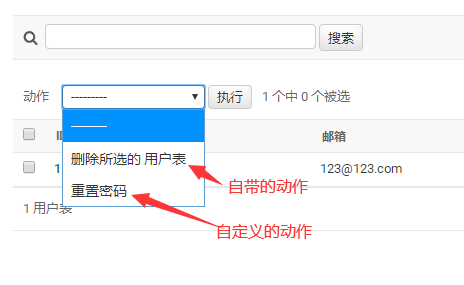
15.上下文管理器
作用:配置了上下文管理器时,views.py访问后会从上下文管理器中访问,结果都返回给前端,公共的返回参数可以写在上下文管理器中,供多个页面访问
a.在子项目user中创建上下文管理器文件,名字可以随便写
from . import models def blog_process(request): print("上下文管理器!") title = "我的博客" category_list = models.Category.objects.all() # locals()表示返回当前函数所有的变量 return locals()
b.在setting中配置上下文管理器路径
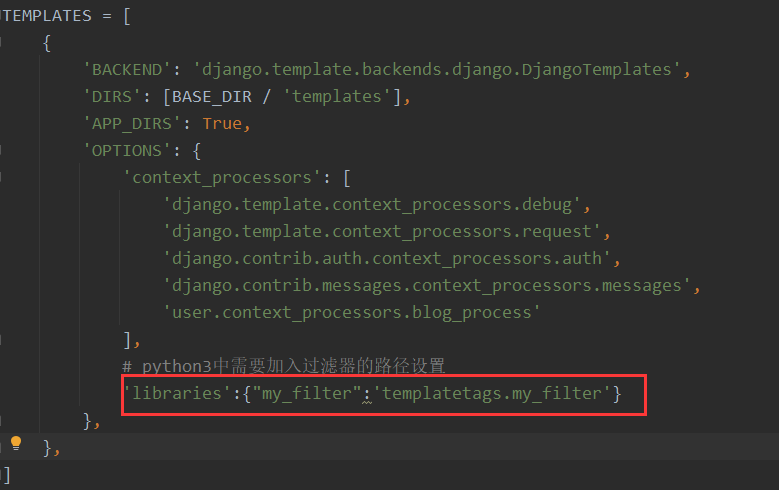
TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [BASE_DIR / 'templates'], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', 'user.context_processors.blog_process' ], }, }, ]
16.模板继承
extends
作用:
模板可以用继承的方式来实现复用,减少冗余内容。
网页的头部和尾部内容一般都是一致的,我们就可以通过模板继承来实现复用。
父模板用于放置可重复利用的内容,子模板继承父模板的内容,并放置自己的内容。
在父模板中的配置
******父模板中的内容******
{% block content%}
{% endblock %}
******父模板中的内容******
在子模版中的配置
{% extends "base.html" %} #继承模板,base.html为父模板文件名称
{% block content%}
*****子模版的内容*****
{% endblock %}
include
作用:也是继承的一种,可以看作时一个组件
a.新建nav.html文件存放导航栏前端代码
b.其他文件调用方式:直接用{% include 'nav.html' %}代替导航代码
17.Django过滤器
内置过滤器
https://blog.csdn.net/weixin_30723433/article/details/97765080
自定义过滤器filter
a.在项目下创建templatetags文件夹,需要带init.py文件
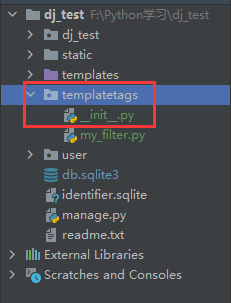
b.创建过滤器自定义文件my_filter.py
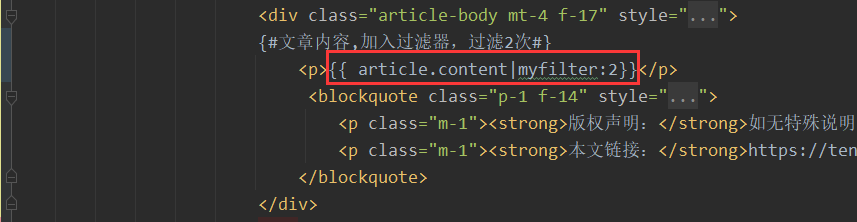
from django import template register = template.Library() @register.filter(name="myfilter") def keyword_replace(content,count): keywords = ["sb", "傻逼"] for keyword in keywords: content = content.replace(keyword, "**",count) return content
c.在前端文件中引用过滤器
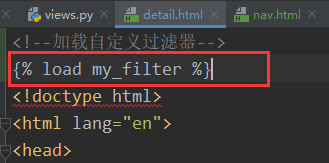
d.python3需要在setting中配置过滤器路径
自定义过滤器simple_tag
与filter功能一样,但是filter最多只能传2个参数,simple_tag不限制传参数量,
a.在my_filter文件中定义simple_tag
@register.simple_tag def keyword_replace2(content,keyword,count): return content.replace(keyword,"**",count)
b.前端文件调用
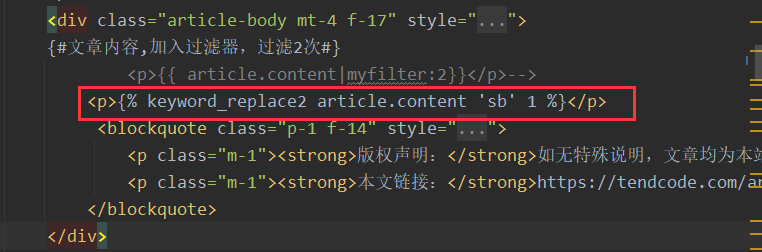
18.分页
from django.core.paginator import Paginator
l = list(range(50))
paginator = Paginator(l,10) #每10条一页
page = paginator.page(1) #取第一页
# print(page.object_list) #第一页的内容
# print(page.has_next()) #是否有下一页
# print(page.next_page_number()) #下一页页码,没有下一页时会报错
# print(page.has_previous()) #上否有上一页
# print(page.previous_page_number()) #上一页页码,没有上一页时会报错
# print(page.has_other_pages()) #有没有其他的分页
# print(page.number) #当前分页的号码
# print(page.paginator.num_pages)#总页数view.py中设置分页
def index(request):
# category_list = models.Category.objects.all()
page_number = int(request.GET.get("page_number", 1)) #通过获取请求参数的方式来获取前端传参,没传默认给1
article_list = models.Article.objects.all()
paginator = Paginator(article_list, 5) # 文章按照每页5条分页
page = paginator.get_page(page_number) #获取当前页
return render(request,"index.html",{"article_list":page.object_list,"page":page}) #返回当前页的内容和page对象前端页面index.html分页展示
<!--分页-->
<!--如果有其他分页,则展示div的内容-->
{% if page.has_other_pages %}
<div class="text-center mt-2 mt-sm-1 mt-md-0 mb-3 f-16">
<!-- 如果有上一页,才展示上一页链接-->
{% if page.has_previous %}
<a class="text-success" href="/?page_number={{ page.previous_page_number }}">上一页</a>
{% endif %}
<span class="mx-2">第 {{ page.number }} / {{ page.paginator.num_pages }} 页</span>
<!--如果有下一页,才展示下一页链接-->
{% if page.has_next %}
<a class="text-success" href="/?page_number={{ page.next_page_number }}">下一页</a>
{% endif %}
</div>
{% endif %}19.文章模糊搜索
在首页实现站内搜索,搜索所有文章

<form class="nav-item navbar-form mr-2 py-md-2" role="search" method="get" id="searchform"
action="/">
<div class="input-group">
<input type="search" name="q" class="form-control rounded-0" placeholder="站内搜索" autocomplete="off"
required=True>
<div class="input-group-btn">
<button class="btn btn-info rounded-0" type="submit"><i class="fa fa-search"></i></button>
</div>
</div><!-- /input-group -->
</form>前端是get请求,input框name是q,获取q的内容进行搜索
def index(request):
# category_list = models.Category.objects.all()
page_number = int(request.GET.get("page_number", 1)) #通过获取请求参数的方式来获取前端传参,没传默认给1
# 获取前端输入的搜索内容
q = request.GET.get("q")
# 一个参数时
# query_dict = {}
# if q:
# query_dict = {"title__contains":q}
# article_list = models.Article.objects.filter(**query_dict)
# 两个参数时
# if q:
# article_list = models.Article.objects.filter(Q(title__contains=q)|Q(content__contains=q))
# else:
# article_list = models.Article.objects.all()
# 两个参数时(第二种方法)
query = Q()
if q:
for field in search_filed:
d = {"%s__contains" % field: q}
query = query | Q(**d) # title___contains=家 |content__contains=家
article_list = models.Article.objects.filter(query)
paginator = Paginator(article_list, 5) # 文章按照每页5条分页
page = paginator.get_page(page_number) # 获取当前页
return render(request,"index.html",{"article_list":page.object_list,"page":page}) #返回当前页的内容和page对象
20.forms、ModelForm校验
访问接口,在调用views.py中方法处理数据前,先通过form.py中的定义校验数据是否合规
写form校验步骤:建表--form.py中写校验内容--view.py通过校验后往库里增加数据--url.py中写接口调用路径
定义字段默认的校验内容和自定义其他校验内容
from django import forms
from . import models
class StudentForm(forms.Form):
# 定义字段的校验内容,如果不符合会自动校验
name = forms.CharField(max_length=50,min_length=2)
phone = forms.CharField(max_length=11,min_length=11)
money = forms.IntegerField(required=False)
# 自定义字段其他校验内容,校验单个字段,用clean_xxx
def clean_phone(self): # 钩子函数,clean_phone是自带的方法
phone = self.cleaned_data["phone"] # 获取手机号
if not phone.isdigit():
raise forms.ValidationError("手机号不合法")
if models.Student.objects.filter(phone=phone).exists():
raise forms.ValidationError("手机已经存在")
return phone
def clean_money(self):
# cleaned_data?????
money = self.cleaned_data["money"]
if money==None:
return 1000
return money多个字段一起校验
# 多个字段一起校验,用clean方法
def clean(self):
if not self.errors: # 没有错误的情况下才继续校验
# 因为clean这个方法,不管上面的校验有没有它最后都会走clean这个方法
# 最后一定要把cleand_data返回
money = self.cleaned_data["money"]
phone = self.cleaned_data["phone"]
if int(phone) > 13811111111:
if money < 10000:
raise forms.ValidationError("money错误")
return self.cleaned_data用ModelForm校验
1.ModelForm可以直接用建表字段进行字段校验
2.也可以自定义校验,作为class Meta的补充
3.用ModelForm时,普通form的clean方法也可以用
# 直接用建表字段进行字段校验,用ModelForm模块
class StudentForm2(forms.ModelForm):
# 自定义校验,作为class Meta的补充
phone = forms.CharField(max_length=11, min_length=11)
# 用ModelForm时,普通form的clean方法也可以用
def clean_money(self):
money = self.cleaned_data["money"]
if money==None:
return 1000
return money
#自动根据表定义的内容进行校验(不能校验字段最小长度)
class Meta:
model = models.Student #对应的哪个表,也就是model
fields = '__all__' #所有字段都要校验
# fields = ["name"] #可以指定校验哪些字段
# exclude = ["name"] #排除哪些字段不校验
#fields和exclude必须得写一个21.reqeust 对象的属性和方法
def request_data(request):
# print(dir(request)) #打印出reqeust对象的所有方法和属性、变量
# print("cookies",request.COOKIES) #
# print("get",request.GET) #url里面的参数
# print("post",request.POST) #form-data传的值
# print("method",request.method) #请求的方法,get/post/put/delete
# print("body",request.body) #传json的时候用它,取传参
# print("meta",request.META) #header里面传东西的时候从它这里获取
# print("token",request.META.get("HTTP_TOKEN")) #获取henader里面的token
# print("content-type",request.content_type) # 【application/json】、【multipart/form-data】等
# print("get_full_path",request.get_full_path())#完整的请求路径,包含参数 /req?id=1
# print("path_info",request.path_info) #只有路径 /req
# print("files",request.FILES) #文件
return HttpResponse("ok")22.中间件
创建文件夹middle_wares存放中间件文件
在中间件文件中写需要处理的事务
from django.middleware.common import MiddlewareMixin
class UrlCountsMiddleware(MiddlewareMixin):
def process_request(self,request):
#所有的请求走到views之前都会走这里
print("process_request")
def process_response(self,request,response):
#所有的请求走完views之后都会走这里
print("process_response")
return response
def process_exception(self,request,exception):
#全局异常拦截器,如果views里面出现异常,那么就会走到这里
print("process_exception")
return HttpResponse("系统出现未知异常")中间件要配置到项目setting文件中才会生效
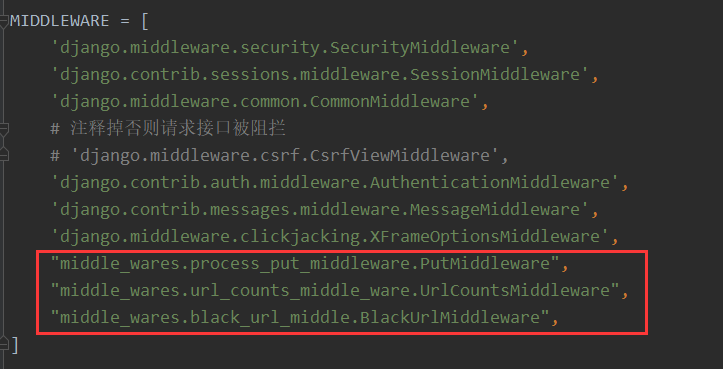
练习:需要统计每天每个url的访问次数
import time
from django.middleware.common import MiddlewareMixin
url_counts = {}
"""
统计每天每个url的访问次数
"""
class UrlCountsMiddleware(MiddlewareMixin):
def process_request(self, request):
# 所有的请求走到views之前都会走这里
today = time.strftime("%Y-%m-%d")
if not url_counts.get(today):
url_counts[today] = {}
today_url_map = url_counts[today]
if not today_url_map.get(request.path_info):
today_url_map[request.path_info] = 1
else:
today_url_map[request.path_info] += 1
print("url_counts", url_counts)练习2:黑名单页面,访问某些页面,提示:暂时无法访问
from django.http import HttpResponse
from django.middleware.common import MiddlewareMixin
"""黑名单中间件"""
# 当访问http://127.0.0.1:8000/req 或者/student 时,提示暂未开放
url_list = ['req','student']
class BlackUrlMiddleware(MiddlewareMixin):
def process_request(self,request):
for url in url_list:
if url in request.path_info:
return HttpResponse("你访问的功能暂时未开放")23.CBV和FBV
FBV(function base views) 基于函数的视图,就是在视图(views)里使用函数处理请求。
CBV(class base views) 基于类的视图,就是在视图(views)里使用类处理请求。
用FBV的方式同时处理get请求和post请求
a.在user/views文件中添加方法
def add_category(request):
if request.method=='GET':
return render(request,'add_category.html')
elif request.method=='POST':
c=models.Category(name=request.POST.get('name'))
c.save()
return HttpResponseRedirect("/")b.urls中配置路径
urlpatterns = [
path('add_category', views.add_category),
]c.前端html文件调用
<!-- submit后请求add_category路径,views中通过request.POST.get('name')来获取输入框中的内容-->
<form action="add_category" method="post" >
分类名称:<input type="text" name="name"><br>
<button type="submit">提交</button>
</form>用CBV的方式同时处理get请求和post请求
a.在user/views文件中添加类
class CategoryVew(View):
def get(self,request):
return render(request,'add_category.html')
def post(self,request):
c = models.Category(name=request.POST.get('name'))
c.save()
return HttpResponseRedirect("/")b.urls中配置路径
# 注意要加as_view()
urlpatterns = [
path('add_category2', views.CategoryVew.as_view()),
]c.前端html文件调用
<!-- submit后请求add_category2路径,views中通过request.POST.get('name')来获取输入框中的内容-->
<form action="add_category2" method="post" >
分类名称:<input type="text" name="name"><br>
<button type="submit">提交</button>
</form>24.用CBV的方式实现get,post,put,delete请求
get
from django.core.paginator import Paginator
from django.db.models import Q
from django.shortcuts import render
from django.http.response import JsonResponse
from django.views import View
from common.tools import model_to_dict,SkyResponse
from . import models
from . import forms
class UserRoleView(View):
limit=10
page=1
filter_field = ["name", "alias"] # 支持精确查询的字段
search_field = ["name","alias"] # 支持模糊查询的字段
def get(self,request):
limit = request.GET.get("limit",self.limit)
page = request.GET.get("page",self.page)
if not str(limit).isdigit() or not str(page).isdigit():
return JsonResponse({"code":-1,"msg":"分页参数不正确!"})
# 精确查询
filter_query_dict = {}
for filed in self.filter_field:
value = request.GET.get(filed)
if value:
filter_query_dict[filed] = value
# 模糊查询
search = request.GET.get("search")
query = Q()
if search:
for field in self.search_field:
d = {"%s__contains" % field: search}
query = query | Q(**d) # name___contains=家 |alias__contains=家
all_data = models.UserRole.objects.filter(query).filter(**filter_query_dict) #同时支持模糊和精确查询,先模糊查询再精确查询
# all_data = models.UserRole.objects.filter(**filter_query_dict) # 精确查询,name=xxx,alias=xxx
paginator = Paginator(all_data, limit) #分页
get_page = paginator.get_page(page)
data_list = [ model_to_dict(data) for data in get_page] #这里model_to_dict导入的是tools里自己重写的方法
# ret = {"code":0,"msg":"success","data":data_list,"count":paginator.count}
return SkyResponse(count=paginator.count, data=data_list)在 common.tools.py文件中重写model_to_dict,支持返回时间、文件类型、多对多、外键、枚举字段
# 重写model_to_dict方法,
# 处理时间问题和字段是文件类型不能序列化的问题和多对多、外键、枚举类型(python源码的model_to_dict没有返回时间)
def model_to_dict(instance, fields=None, exclude=None):
opts = instance._meta
data = {}
for f in chain(opts.concrete_fields, opts.private_fields, opts.many_to_many):
if fields is not None and f.name not in fields:
continue
if exclude and f.name in exclude:
continue
value = f.value_from_object(instance)
if type(value) == datetime.datetime:
value = value.strftime("%Y-%m-%d %H:%M:%S")
if type(value) == datetime.date:
value = value.strftime("%Y-%m-%d")
if isinstance(value,FieldFile): #如果是文件类型,那么就取文件的url
value = value.url
if isinstance(f,ManyToManyField): #处理多对多的时候,把多对多里面的对象每个都转成一个字典
value = [model_to_dict(item) for item in value]
if isinstance(f,ForeignKey) or isinstance(f,OneToOneField): #处理外键的
value = model_to_dict(value)
if f.choices: # 处理枚举类型
# 不处理返回是:"is_delete": 0,
# 处理后:"is_delete": {"name": "未删除", "value": 0}
choices_dict = dict(f.choices) # choices_dict={0:未删除}
value = {"name": choices_dict.get(value), "value": value}
data[f.name] = value
return data处理中文乱码,重写JsonResponse类
# 继承JsonResponse类,重写JsonResponse类的初始化方法,处理中文乱码问题
class SkyResponse(JsonResponse):
def __init__(self, code=0, msg="success", **kwargs): # k-v
data = {"code": code, "msg": msg}
data.update(kwargs) #合并两个字典
super().__init__(data, json_dumps_params={"ensure_ascii": False}) #继承了JsonResponse类,用super()调用父类25.子项目内自己写url
在子项目sky/urls.py中写地址
from django.urls import path
from . import views
# 子项目内可以自己写url,在总的项目url下引入
urlpatterns = [
path('user_role', views.UserRoleView.as_view()), #as_view是类View的一个方法,自动查找指定方法的作用
path('user', views.UserView.as_view()),
]在总项目的urls中引入
from django.urls import path,include
urlpatterns = [
path('sky/',include("sky.urls")), #引入子项目的url,访问子项目下的接口路径就是http://127.0.0.1:8000/sky/xxx
]26.写入cookie到浏览器中
class SkyResponse(JsonResponse):
def __init__(self, code=0, msg="success",cookie=None, **kwargs): # k-v
data = {"code": code, "msg": msg}
data.update(kwargs) #合并两个字典
super().__init__(data, json_dumps_params={"ensure_ascii": False}) #继承了JsonResponse类,用super()调用父类
if cookie:
for k,v in cookie.items():
self.set_cookie(k,v)
#调用
return SkyResponse(count=paginator.count, data=data_list,cookie={'cookie_test':'zhengpei'}) 
27.配置MySQL数据库
DATABASES = {
# 'default': {
# 'ENGINE': 'django.db.backends.sqlite3',
# 'NAME': BASE_DIR / 'db.sqlite3',
# }
# mysql数据库配置
'default': {
'ENGINE': 'django.db.backends.mysql',
'USER': "jxz", # 用户
"HOST": '110.40.129.50',
"PASSWORD": "123456",
"PORT": 3306,
"NAME": "jxz" # 数据库
},
# 多个数据库时配置
'db2': {
'ENGINE': 'django.db.backends.mysql',
'USER': "jxz", # 用户
"HOST": '110.40.129.50',
"PASSWORD": "123456",
"PORT": 3306,
"NAME": "jxz" # 数据库
},
}如果要用mysql,需要在项目同名目录下的__init__.py文件中加上
import pymysql
pymysql.install_as_MySQLdb()如果有多个数据时使用db2
28.配置redis
a.先安装django_redis
pip install -U django_redisb.在setting文件中加上redis的配置
# redis配置
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6380/0",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100, },
# "DECODE_RESPONSES":True, #指定默认返回的结果是字符串,不指定的话默认返回的是byte类型
"PASSWORD": "REDIS_123456!", # 密码
}
}
} c.使用redis
import django_redis
# 默认链接default,有多个redis,链接方式:r = django_redis.get_redis_connection("redis2")
r = django_redis.get_redis_connection() 29.pickle模块进行序列化类和对象
pickle模块类似json模块,但json模块不支持序列号对象和类,pickle可以,pickle是Django自带的
import pickle
class User:
def __init__(self,id,username,create_time,email,phone):
self.id = id
self.username = username
self.create_time = create_time
self.email = email
self.phone = phone
#将对象中的内容序列化后写入文件,写入的byte类型
# d2 = User(1,"test@163.com","sdgsgsdg","qq@qq.com",2352353523)
# with open("user.txt","wb") as fw:
# ret = pickle.dumps(d2)
# fw.write(ret)
#从文件中获取序列化后的文件内容
with open("user.txt","rb") as f:
d = pickle.loads(f.read())
print(d.email)
print(d.id)
print(d.phone)
30.项目中加log日志
在common中加log.py文件
from loguru import logger
import os
base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
log_path = os.path.join(base_dir, 'logs', 'sky.log') # 日志文件
log_level = "DEBUG"
class Log:
logger.add(log_path, level=log_level, encoding='utf-8',
enqueue=True, rotation='1 day', # rotation多久产生一个日志文件
retention='5 days') # 写在日志文件里面
debug = logger.debug
info = logger.info
warning = logger.warning
error = logger.error写入日志的写法:在方法中可能会报错的位置加上如下代码:Log.error、Log.warning
try:
query_object.delete()
except:
Log.error("删除失败,query_object:{},error:{}", query_object, traceback.format_exc())
return SkyResponse(-1, "删除失败", error=traceback.format_exc())报错后会在log/sky.log文件中写入错误日志
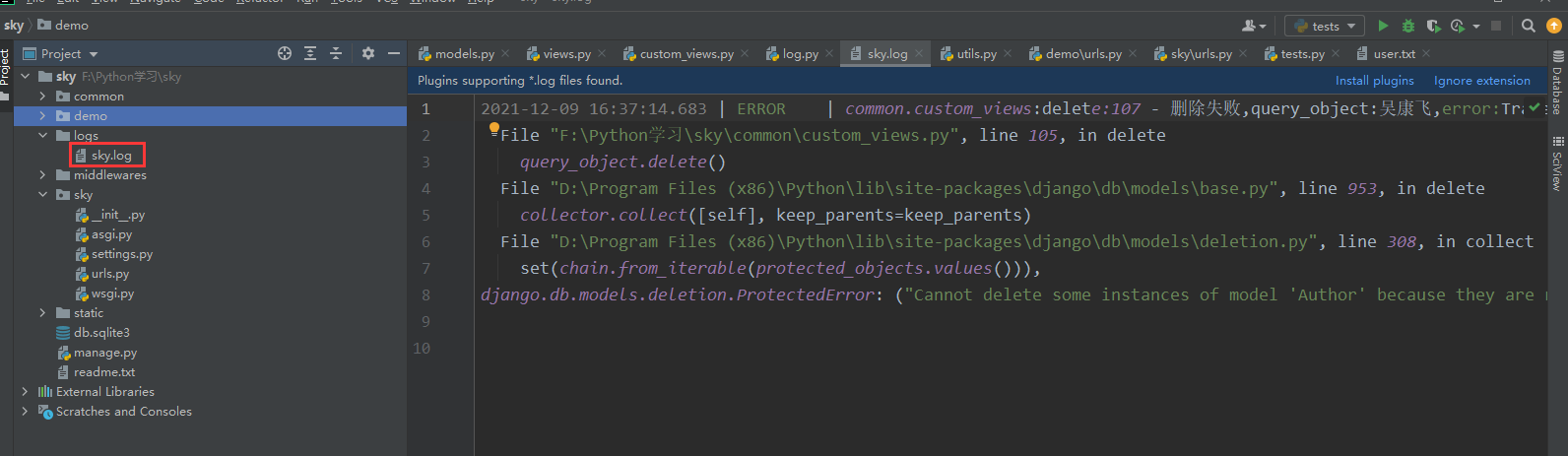
31.部署上传代码


 浙公网安备 33010602011771号
浙公网安备 33010602011771号