HDFS介绍及简单操作
目录
1.HDFS是什么?
2.HDFS设计基础与目标
3.HDFS体系结构
3.1 NameNode(NN)
3.2 DataNode(DN)
3.3 SecondaryNameNode(SNN)
3.4 块(Block)的概念
3.5 文件安全
3.读取数据流程
4.HDFS的可靠性
4.1 冗余副本策略
4.2 机架策略
4.3 心跳策略
4.4 安全模式
4.5 校验和
4.6 回收站
4.7 元数据保护
4.8 快照机制
5.HDFS基础架构以及工作原理
6.HDFS读操作
7.HDFS写操作
8.HDFS现实举例
9.HDFS简单操作
10.HDFS管理与更新
11.HDFS 优点 VS 缺点
12.Block的副本放置策略
13.HDFS文件权限
Hadoop其实并不是一个产品,而是一些独立模块的组合。主要由分布式文件系统HDFS和大型分布式数据处理算法MapReduce组成。那么我们今天就来看看HDFS究竟是什么鬼?
1.HDFS是什么?
HDFS即Hadoop Distributed File System。首先它是一个开源系统,同时它是一个能够面向大规模数据使用的,可进行扩展的文件存储与传递系统。是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。即使系统中有某些节点脱机,整体来说系统仍然可以持续运作而不会有数据损失。
它分为2个部分:NameNode和DataNode。NameNode相当于一个领导,它管理集群内的DataNode,当客户发送请求过来后,NameNode会根据情况制定存储到哪些DataNode上,而其本身自己并不存储真实的数据。那NameNode怎么知道集群内DataNode的信息呢?DataNode发送心跳信息给NameNode(一会详见原理图)。
Hadoop分布式文件系统是根据Google发表的GFS(Google File System)论文产生过来的。
2.HDFS设计基础与目标
HDFS是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商业服务器上。
(1) 硬件错误是常态。因此需要冗余。
在Google很少会使用超级计算机,也很少会使用一些厂商很昂贵的设备,他们一般会使用的就是普通的PC集群。PC集群即使是PC server,它的底子基本上也是家用机的模式,所以这种机器的耐用性肯定没有小型机或者专用的服务器高。如果一个集群里机器很多,比如几百台,那么每个星期坏几台是很常见的。这个“坏掉”不一定是彻底坏掉,可能是宕机等,比如内存不稳定或者CPU过热,导致某些节点死掉;或者过了一段时间之后,硬盘的寿命到期,硬盘的介质发生了损坏,因为普通PC很多都是采用很便宜的SATA硬盘,它设计的也不一定就是7*24工作的,或者在7*24模式底下工作它的寿命就会大大缩短。无论什么原因,总之在hadoop集群里面,我们面对的就是经常性地发生错误这种情况。每天可能就是要面对各种各样的错误,有些时候可能是节点机器本身失效,比如死机、断网等,有些时候可能是硬盘介质问题,比如某个文件损坏、某个硬盘完全坏掉等。由于错误是经常性发生,所以备份都不足够防止这种错误。因此需要冗余,就是在运行的过程中直接对数据进行备份,比如说数据本来只需要写一份,现在可能需要一次写好几份,万一某个节点失效,我们还可以从其他节点把这个数据拿出来。因此冗余是HDFS本身直接嵌入的一个功能,它并不是一个额外的功能,它是在设计的时候就必须考虑的一点。冗余思想是深入到HDFS的骨髓里面的。
(2) 流式数据访问。即数据批量读取而非随机读写,hadoop擅长做的是数据分析而不是事物处理。
HDFS是为大数据而生。一般来说很少会让Hadoop集群去做OLTP(联机事务处理)。所谓OLTP就是偶尔地、随机性地去读写一些数据,主要就是随机读,随机写,可能还会有一些修改的工作。Hadoop很少会处理这种事情,它处理的是大数据的流式读写,比如说我整堆整堆的去读,然后去加以处理。
(3) 大规模数据集。
(4) 简单一致性模型,为了降低系统复杂度,对文件采用一次性写多次读的逻辑设计,即是文件一经写人,关闭,就不能修改。
由于面临的是批量性地操作,所以hadoop在设计时就会采取一些简单的一致性模型,针对这种大批量读却很少去写的模型。为了降低系统的复杂度,Hadoop文件通常是一次性写进去,比如说拷贝文件一次性拷好,这个文件拷好之后一般你不会去改,除非你把它删除掉。就是说这个文件写进去之后你会多次去读它,但是不能改变它的内容。如果你一定要改变它,那就把原来的文件删除,然后再把改后的文件重新写进去。
(5) 程序采用“数据就近”原则分配节点执行。
HDFS在设计时也要考虑到MapReduce体系跟它的融合,就是我们的数据到底怎么放,才能使作业以最快的速度来运行。
在读取数据时,为了减少整体带宽消耗和降低整体的带宽延时,HDFS会尽量让读取程序读取离客户端最近的副本。
3.HDFS体系结构
HDFS体系结构中主要有2类节点,一类是NameNode,一类是DataNode。这两类节点分别承担Master和Worker的任务。NameNode就是Master管理集群中的执行调度,DataNode就是Worker具体任务的执行节点。NameNode管理文件系统的命名空间,维护整个文件系统的文件目录树以及这些文件的索引目录。这些信息以两种形式存储在本地文件系统中,一种是命名空间镜像(Namespace image),一种是编辑日志(Edit log)。从NameNode中你可以获得每个文件的每个块所在的DataNode。需要注意的是,这些信息不是永久保存的,NameNode会在每次系统启动时动态地重建这些信息。当运行任务时,客户端通过NameNode获取元数据信息,和DataNode进行交互以访问整个文件系统。
当然,HDFS体系结构中还有一类节点,那就是Secondary NameNode。这个节点的主要作用就是周期性地合并日志中的命名空间镜像,以避免编辑日志过大。
HDFS采用Master/Slave架构对文件系统进行管理。一个HDFS集群是由一个NameNode和一定数目的DataNode组成的。NameNode是一个中心服务器,负责管理文件系统的命名空间(Namespace)以及客户端对文件的访问,集群的DataNode一般是由一个节点运行一个DataNode进程,负责管理它所在节点上的存储。
从内部看,一个文件其实被分成了一个或多个数据块,这些块存储在一组DataNode上。NameNode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它负责确定数据块到具体DataNode节点的映射。DataNode负责处理文件系统客户端的读/写请求。在NameNode的统一调度下进行数据块的创建、删除和复制(注意这里没有修改)。
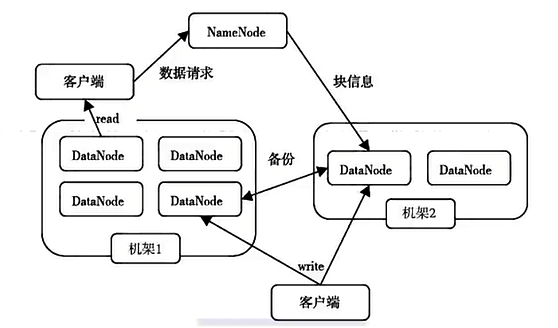
中心目录服务器(NameNode)管理大量数据服务器(DataNode):
NameNode管理元数据(文件目录树,文件——>块映射,块——>数据服务器映射表,etc)
DataNode负责存储数据、以及响应数据读写请求
客户端与NameNode交互进行文件创建/删除/寻址等操作,之后直接与DataNode交互进行文件I/O
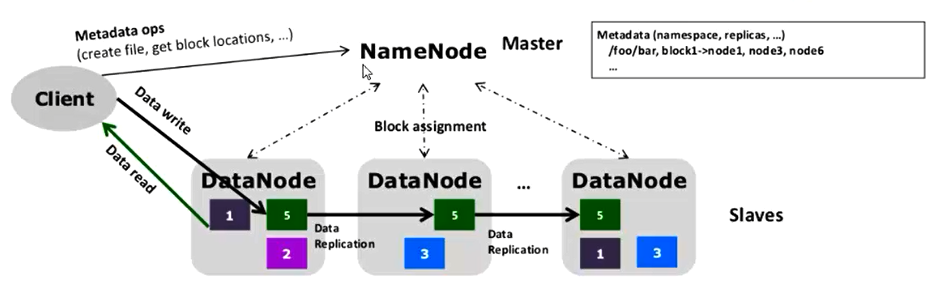
下面我们来逐一观察一下架构里面的一些元素。
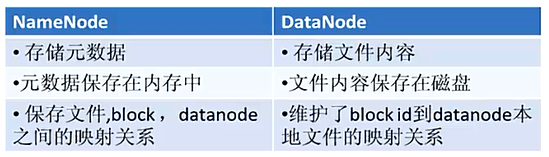
3.1 NameNode(NN)
(1) 管理文件系统的命名空间。
就是说它是文件系统总控的节点。
(2) 记录每个文件的数据块在各个DataNode上的位置和副本信息。
就比如说现在我有一个表格,这个表格的每一个项目均记录了一个文件的情况,比如说文件名、权限、元数据信息(建立修改时间、长度等)。除此之外,它还记录这些文件究竟在集群的哪些节点上,比如说存在节点1的某个数据块上面。
(3) 协调客户端对文件的访问。
当有节点需要访问某个文件时,首先访问NameNode来获取文件位置信息,然后跟相应的DataNode通讯,读取数据块。所以NameNode在这里起到了一个类似书里面目录的作用。
(4) 记录命名空间内的改动或空间本身属性的改动。
比如说它的权限发生了一些什么样的变化之类的。
(5) 使用事物日志记录HDFS元数据的变化,使用映像文件存储文件系统的命名空间,包括文件映射,文件属性等。
NameNode使用两个东西来记录元数据。分别是事物日志和映像文件。具体来说大家可以打开NameNode节点上面你所定义的保存元数据的目录,在HDFS配置文件里面有一项参数是指出元数据在什么地方,那是一个目录,打开目录之后可以看到有一些文件,其中fsimage就是映像文件。


[root@hadoop ~]# cat /usr/local/hadoop/etc/hadoop/core-site.xml ... <property> <name>hadoop.tmp.dir</name> <value>/var/hadoop/tmp</value> </property> ... [root@hadoop ~]# cd /var/hadoop/tmp/dfs/name/current/ [root@hadoop current]# ll total 1052 -rw-r--r-- 1 root root 42 Jul 18 04:03 edits_0000000000000000001-0000000000000000002 -rw-r--r-- 1 root root 1048576 Jul 18 04:03 edits_inprogress_0000000000000000003 -rw-r--r-- 1 root root 389 Jul 18 04:02 fsimage_0000000000000000000 -rw-r--r-- 1 root root 62 Jul 18 04:02 fsimage_0000000000000000000.md5 -rw-r--r-- 1 root root 389 Jul 18 04:03 fsimage_0000000000000000002 -rw-r--r-- 1 root root 62 Jul 18 04:03 fsimage_0000000000000000002.md5 -rw-r--r-- 1 root root 2 Jul 18 04:03 seen_txid -rw-r--r-- 1 root root 219 Jul 18 04:02 VERSION
补充:
NameNode(NN)主要功能:接受客户端的读写服务(不理解?)
NameNode保存metadata信息包括:a.文件ownership和permissions;b.文件包含哪些块;c.Block保存在哪个DataNode(由DataNode启动时上报)。
NameNode的Metadata信息在启动后都会加载到内存中,同时metadata信息(包括上述a和b)也会存储到磁盘文件名为“fsimage”,但是上述 c.Block的位置信息 不会保存到fsimage,只会存在于内存中;edits记录对metadata操作日志。
3.2 DataNode(DN)
(1) 负责所在物理节点的存储管理
(2) 一次写入,多次读取(不修改)
由于这个特性,那么我们就不需要考虑一致性问题。所谓一致性就是说假如有很多人同时修改一个文件,那么最终应该采纳哪个修改的版本呢?这是在数据库环境里经常要考虑的问题。在Oracle中采用回滚,在块结构里也加了一些机制来保证读取一致性,但是Oracle里面做的巨复杂。而在hadoop中非常简单,因为文件一经写入就不能改,所以根本就不可能发生很多人一起修改的情况。因此它完全不需要考虑一致性。
(3) 文件由数据块组成,典型的块大小是128MB(v1版本是64MB,v2版本是128MB)
hadoop中每个数据块是一个blk文件,一般来说缺省的数据块可以达到128MB,大家可以尝试往Hadoop里面不断写文件,可观察到数据块在不断增长,一般来说增长到128MB就不再增长,然后数据块文件就不断增多。
(4) 数据块尽量散布到各个节点
实现冗余的效果
补充:
DataNode存储数据(Block);
启动DN线程的时候会向NN汇报block信息;
通过向NN发送心跳保持与其联系(3秒一次),如果NN 10分钟没有收到DN的心跳,则认为其已经lost,并copy其上的block到其他DN。
3.3 SecondaryNameNode(SNN)
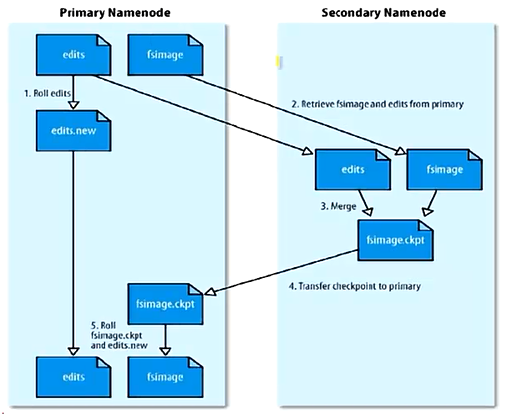
1)它不是NN的备份(但可以做备份),它的主要工作是帮助NN合并edits log,减少NN启动时间。
2)SNN执行合并时机:
根据配置文件设置的时间间隔fs.checkpoint.period,默认3600秒。
根据配置文件设置edits log大小fs.checkpoint.size规定edits文件的最大值默认为64MB。
SNN合并流程
3.4 块(Block)的概念
操作系统中的文件块。文件是以块的形式存储在磁盘中,此处块的大小代表系统读、写、可操作的最小文件大小。也就是说,文件系统每次只能操作磁盘块大小的整数倍数据。通常来说,一个文件系统块大小为几千字节,而磁盘块大小为512字节。
HDFS中的块是一个抽象的概念,比操作系统中的块要大得多。在配置hadoop系统时会看到,它的默认大小是64MB(最新版本默认大小已经变成了128MB)。HDFS使用抽象的块的好处:1)可以存储任意大的文件而又不会受到网络中任一单个节点磁盘大小的限制。2)使用抽象块作为操作的单元可以简化存储子系统。
HDFS数据存储单元(block)
1)文件被切分成固定大小的数据块:默认数据块大小为64MB,可配置;若文件大小不到64MB,则单独存成一个block。
2)一个文件存储方式:按大小被切分成若干个block,存储到不同节点上,默认情况下每个block都有3个副本(可配置);Block大小和副本数通过client端上传文件时设置,文件上传成功后副本数可以变更,Block大小不可变更。
3.5 文件安全
hadoop采用了两种方法来确保文件安全。
第一种方法:将NameNode中的元数据转储到远程的NFS文件系统上。
第二种方法:系统中同步运行一个Secondary NameNode,这个节点的主要作用就是周期性地合并日志中的命名空间镜像,以避免编辑日志过大。
4.HDFS的可靠性
4.1 冗余副本策略
(1) 可以在hdfs-site.xml中设置复制因子指定副本数量。
[root@hadoop ~]# cat /usr/local/hadoop/etc/hadoop/hdfs-site.xml ... <property> <name>dfs.replication</name> <value>1</value> </property> ...
复制因子:比如说replication=1代表没有冗余,2及以上代表有冗余。一般来说,数越大代表越安全,即数据块重复的越多越安全。但是把数定大了也有坏处,那
就是空间利用率下降,比如说冗余数量增大一倍,此时空间利用率就会下降50%。还有一个坏处就是影响速度,因为数据要写入副本,肯定会在性能上产生一些影响。所以说复制因子应该取什么数值呢?说实话这个一般没有什么原则,大家可以根据实际集群的情况、性能、空间利用率等综合的一个平衡,来选取一个折中的数值。
(2) 所有数据块都有副本。
(3) DataNode启动时,遍历本地文件系统,产生一份hdfs数据块和本地文件的对应关系列表(blockreport)汇报给NameNode。
一般来说数据节点启动时,都会把本地的系统文件遍历一次,产生一个数据块和本地文件对应的清单(叫做blockreport)汇报给NameNode,NameNode根据blockreport来和它的元数据进行对照,看一看数据节点的实际情况跟元数据里面所记录的情况是否相符,再决定是否采取某些安全上的措施。
4.2 机架策略
集群一般放在不同机架上,机架间带宽要比机架内宽带要小。
集群一般是放在若干个机柜里面,集群可能利用机柜里面的交换机共同连到一个大的交换机里面,一般来说有这么一个规律,就是同一个机柜里面的机器由于连的是同一个机柜里的交换机,通常交换数据比较快。不同机柜之间的服务器由于连到一个更加高级的一个交换机里面,所以他们的速度一般会慢一点。而且还有一个比较特别的情况,有时候可能会因为网线的故障或者交换机端口的故障,我们往往会跟整个机柜里面的服务器失去联系。考虑到这种情况。hadoop对机架要有特殊的处理策略。比如机架感知和冗余策略。
HDFS的“机架感知”。
通过节点之间互相传递一个信息包来获知节点之间的关系(究竟是分布在同一个机架还是不同的机架里面)。
副本的存放是HDFS可靠性和性能的关键。优化的副本存放策略也正是HDFS区分于其他大部分分布式文件系统的重要特征。HDFS采用一个称为“机架感知(rack-aware)”的策略来改进数据的可靠性、可用性和网络带宽的利用率。
冗余:一般在本机架存放一个副本,在其他机架存放别的副本,这样可以防止机架失效时丢失数据,也可以提高带宽利用率。
4.3 心跳策略
Namnode周期性从DataNode接收心跳信号和快报告;
所谓快报告就是说DataNode会不断地向NameNode发送一个blockreport,告诉他在本地的系统里面数据块和文件的对应关系。
NameNode会根据块报告验证元数据;
就是说数据节点实际情况和元数据里面记录的是否一致,如果不一致,可能需要进行相应的修正以及冗余策略等。
没有按时发送心跳的DataNode会被标记为宕机,不会再给它任何I/O请求;
如果DataNode失效造成副本数量下降,并且低于预先设置的阈值,NameNode会检测出这些数据块,并在合适的时机进行重新复制;
引发重新复制的原因还包括数据副本本身损坏、磁盘错误,复制因子被增大等。
4.4 安全模式
NameNode启动后会进入一个称为安全模式的状态。处于安全模式的NameNode不会进行数据块的复制,NameNode从所有的DataNode接收心跳信号和块状态报告。
过程:
NameNode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。
一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件(这个操作不需要SecondaryNameNode)和一个空的编辑日志。
此刻NameNode运行在安全模式,即NameNode的文件系统对于客户端来说是只读的(显示目录、文件内容等。写、删除、重命名都会失败)。
在此阶段NameNode收集各个DataNode的报告,当数据块达到最小副本数以上时,会被认为是安全的;在一定比例(可设置)的数据块被确定为“安全”后,再过若干时间,安全模式结束。
当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数,系统中数据块的位置并不是由NameNode维护的,而是以块列表形式存储在DataNode中。
报错:
在运行hadoop程序时,有时候会报以下错误:
org.apache.hadoop.dfs.SafeModeException: Cannot delete /user/hadoop/input. Name node is in safe mode
在分布式文件系统启动时,开始的时候会进入安全模式,当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。
安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期通过命令也可以进入安全模式。
在通过命令行启动hadoop的守护进程时,有时会因为操作不当,例如“Ctrl+z”或者命令行的切换关闭等会使得NameNode进入安全模式,解决此问题只要在hadoop的根目录下输入:
hdfs dfsadmin -safemode enter 即进入安全模式
hdfs dfsadmin -safemode leave 即离开安全模式
start-balancer.sh 负载均衡模式、
4.5 校验和
在文件创立时,每个数据块都产生校验和;
校验和会作为单独一个隐藏文件保存在命名空间下;
客户端获取数据时可以检查校验和是否相同,从而发现数据块是否损坏;
如果正在读取的数据块损坏,则可以继续读取其它副本。
4.6 回收站
删除文件时,其实是放入回收站/trash;
回收站里的文件可以快速恢复;
可以设置一个时间阈值,当回收站里文件的存放时间超过这个阈值,就会被彻底删除,并且释放占用的数据块。
4.7 元数据保护
映像文件和事物日志是NameNode的核心数据,可以配置为拥有多个副本;
副本会降低NameNode的处理速度,但增加安全性;
NameNode依然是单点,如果发生故障要手工切换。
元数据在NameNode上,保存了整个文件系统的关键信息,如果元数据被破坏掉,那么毫无疑问文件系统就崩溃了,无可挽回的崩溃,为了防止这种情况的发生,我们需要对元数据进行保护。
4.8 快照机制
支持存储某个时间点的映像,需要时可以使数据重返这个时间点的状态;
Hadoop目前(2012年)还不支持快照,已经列入开发计划。
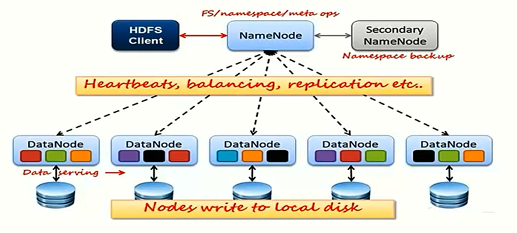
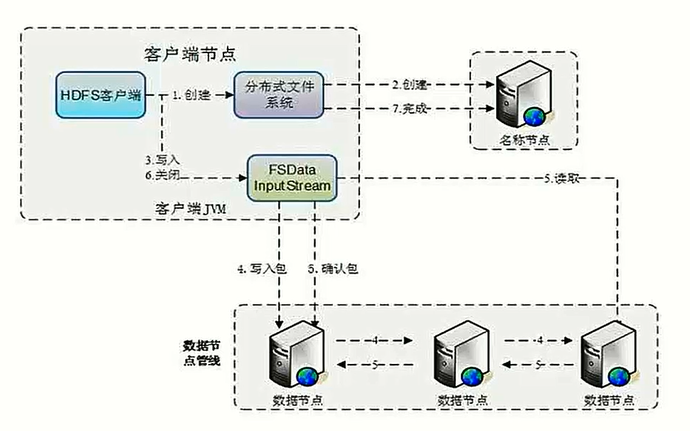
5.HDFS基础架构以及工作原理
HDFS基础架构
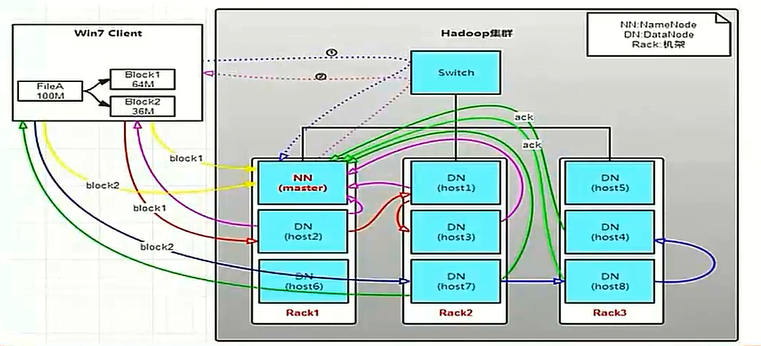
下图是hdfs写操作图,具体过程描述详见这里
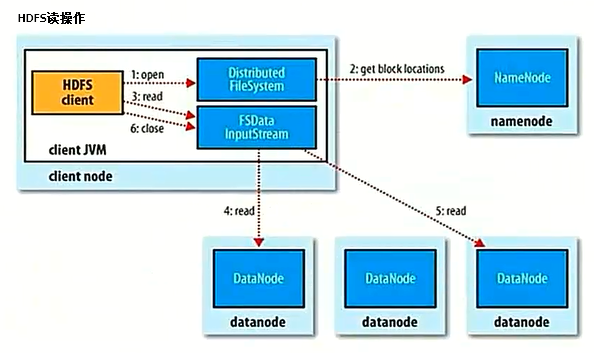
6.HDFS读操作
客户端(client)用FileSystem的open()函数打开文件。
DistributedFileSystem用RPC(Remote Procedure Call—远程过程调用)调用元数据节点,得到文件的数据块信息。
对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据。
客户端调用stream的read()函数开始读取数据。
DFSInputStream连接保存此文件第一个数据块的最近的数据节点。
Data从数据节点读到客户端(client)。
当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
当客户端读取完毕数据的时候,调用FSDataInputStream的close()函数。
在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。失败的数据节点将被记录,以后不再连接。
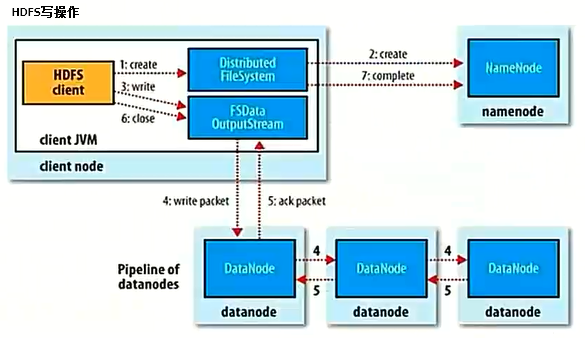
7.HDFS写操作
客户端调用create()来创建文件。
DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。
元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
DistributedFileSystem返回DFSOutputStream,客户端用于写数据。
客户端开始写入数据,DFSOUTputStream将数据分成块,写入data queue。
DataQuery由DataStreamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)分配的数据节点放在一个pipeline里。
DataStreamer将数据块写入pipeline中的第一个数据节点。
第一个数据节点将数据块发送给第二个数据节点,第二个数据节点将数据发送给第三个数据节点。
DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
8.HDFS现实举例
9.HDFS简单操作
linux操作系统中的很多命令在HDFS系统中也可以使用,只不过需要在前面添加一个前缀hdfs dfs -。具体操作举例如下:
[root@hadoop ~]# start-all.sh #启动hadoop ... [root@hadoop ~]# vi 123.txt #新建一个测试文件 I love hadoop [root@hadoop ~]# hdfs dfs -put 123.txt / #将测试文件放到hdfs根目录下 [root@hadoop ~]# hdfs dfs -ls / #查看hdfs根目录 Found 1 items -rw-r--r-- 1 root supergroup 14 2018-07-18 21:47 /123.txt [root@hadoop ~]# hdfs dfs -cat /123.txt #查看hdfs中的测试文件内容 I love hadoop [root@hadoop ~]# hdfs dfs -mkdir /test #创建目录 [root@hadoop ~]# hdfs dfs -ls / #查看,创建目录成功 Found 2 items drwxr-xr-x - root supergroup 0 2018-07-18 21:51 /test -rw-r--r-- 1 root supergroup 14 2018-07-18 21:47 /123.txt [root@hadoop ~]# hdfs dfs -cp /123.txt /test/ #复制文件 [root@hadoop ~]# hdfs dfs -ls /test/ #查看,复制文件成功 Found 1 items -rw-r--r-- 1 root supergroup 14 2018-07-18 21:54 /test/123.txt [root@hadoop ~]# hdfs dfs -cd /test/ #注意:没有cd命令 -cd: Unknown command [root@hadoop ~]# hdfs dfs -rm -r /test #删除目录 Deleted /test [root@hadoop ~]# hdfs dfs -ls / #查看,删除目录成功 Found 1 items -rw-r--r-- 1 root supergroup 14 2018-07-18 21:47 /123.txt [root@hadoop ~]# hdfs dfs -get /123.txt /var/hdfs_123.txt #将测试文件取出来放到本地 [root@hadoop ~]# cd /var/ #查看 [root@hadoop var]# ls adm crash empty gopher hdfs_123.txt lib lock mail opt run tmp cache db games hadoop kerberos local log nis preserve spool yp [root@hadoop var]# cat hdfs_123.txt I love hadoop [root@hadoop var]# hdfs dfs -df -h #查看hdfs使用情况 Filesystem Size Used Available Use% hdfs://hadoop:9000 18.0 G 24.0 K 11.0 G 0% #其实,上面的命令基本上都可以用hadoop fs -前缀命令代替,比如 [root@hadoop ~]# hadoop fs -ls / #查看hdfs根目录 Found 1 items -rw-r--r-- 1 root supergroup 14 2018-07-18 21:47 /123.txt
[root@hadoop ~]# hdfs dfs #显示所有的命令 Usage: hadoop fs [generic options] [-appendToFile <localsrc> ... <dst>] [-cat [-ignoreCrc] <src> ...] [-checksum <src> ...] [-chgrp [-R] GROUP PATH...] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>] [-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...] [-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>] [-createSnapshot <snapshotDir> [<snapshotName>]] [-deleteSnapshot <snapshotDir> <snapshotName>] [-df [-h] [<path> ...]] [-du [-s] [-h] [-v] [-x] <path> ...] [-expunge] [-find <path> ... <expression> ...] [-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-getfacl [-R] <path>] [-getfattr [-R] {-n name | -d} [-e en] <path>] [-getmerge [-nl] [-skip-empty-file] <src> <localdst>] [-head <file>] [-help [cmd ...]] [-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]] [-mkdir [-p] <path> ...] [-moveFromLocal <localsrc> ... <dst>] [-moveToLocal <src> <localdst>] [-mv <src> ... <dst>] [-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>] [-renameSnapshot <snapshotDir> <oldName> <newName>] [-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...] [-rmdir [--ignore-fail-on-non-empty] <dir> ...] [-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]] [-setfattr {-n name [-v value] | -x name} <path>] [-setrep [-R] [-w] <rep> <path> ...] [-stat [format] <path> ...] [-tail [-f] <file>] [-test -[defsz] <path>] [-text [-ignoreCrc] <src> ...] [-touchz <path> ...] [-truncate [-w] <length> <path> ...] [-usage [cmd ...]] Generic options supported are: -conf <configuration file> specify an application configuration file -D <property=value> define a value for a given property -fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations. -jt <local|resourcemanager:port> specify a ResourceManager -files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster -libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath -archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines The general command line syntax is: command [genericOptions] [commandOptions]
[root@hadoop var]# hadoop fs Usage: hadoop fs [generic options] [-appendToFile <localsrc> ... <dst>] [-cat [-ignoreCrc] <src> ...] [-checksum <src> ...] [-chgrp [-R] GROUP PATH...] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>] [-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...] [-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>] [-createSnapshot <snapshotDir> [<snapshotName>]] [-deleteSnapshot <snapshotDir> <snapshotName>] [-df [-h] [<path> ...]] [-du [-s] [-h] [-v] [-x] <path> ...] [-expunge] [-find <path> ... <expression> ...] [-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-getfacl [-R] <path>] [-getfattr [-R] {-n name | -d} [-e en] <path>] [-getmerge [-nl] [-skip-empty-file] <src> <localdst>] [-head <file>] [-help [cmd ...]] [-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]] [-mkdir [-p] <path> ...] [-moveFromLocal <localsrc> ... <dst>] [-moveToLocal <src> <localdst>] [-mv <src> ... <dst>] [-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>] [-renameSnapshot <snapshotDir> <oldName> <newName>] [-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...] [-rmdir [--ignore-fail-on-non-empty] <dir> ...] [-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]] [-setfattr {-n name [-v value] | -x name} <path>] [-setrep [-R] [-w] <rep> <path> ...] [-stat [format] <path> ...] [-tail [-f] <file>] [-test -[defsz] <path>] [-text [-ignoreCrc] <src> ...] [-touchz <path> ...] [-truncate [-w] <length> <path> ...] [-usage [cmd ...]] Generic options supported are: -conf <configuration file> specify an application configuration file -D <property=value> define a value for a given property -fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations. -jt <local|resourcemanager:port> specify a ResourceManager -files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster -libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath -archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines The general command line syntax is: command [genericOptions] [commandOptions]
附两个查看hdfs shell命令的网址:
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/FileSystemShell.html
http://hadoop.apache.org/docs/r2.6.2/hadoop-project-dist/hadoop-common/FileSystemShell.html
10.HDFS管理与更新
(1) 查看HDFS基本统计信息 hdfs dfsadmin -report
[root@hadoop ~]# hdfs dfsadmin -report #以下是我自己翻译的,如有问题欢迎指正。 Configured Capacity: 19315818496 (17.99 GB) #配置容量:19315818496(17.99 GB) Present Capacity: 11839451136 (11.03 GB) #现有容量:11839451136(11.03 GB) DFS Remaining: 11838365696 (11.03 GB) #分布式文件系统剩余:11838365696(11.03 GB) DFS Used: 1085440 (1.04 MB) #分布式文件系统已使用:1085440(1.04 MB) DFS Used%: 0.01% #分布式文件系统已使用百分比:0.01% Replicated Blocks: #复制块: Under replicated blocks: 4 # 已复制块数:4 Blocks with corrupt replicas: 0 # 具有损坏副本的块数:0 Missing blocks: 0 # 丢失块数:0 Missing blocks (with replication factor 1): 0 # 丢失块数(复制因子为1):0 Pending deletion blocks: 0 # 待删除块:0 Erasure Coded Block Groups: #擦除编码块组: Low redundancy block groups: 0 # 低冗余块组:0 Block groups with corrupt internal blocks: 0 # 内部块损坏的块组: Missing block groups: 0 # 丢失块组:0 Pending deletion blocks: 0 # 待删除块:0 # ------------------------------------------------- # Live datanodes (1): #实时数据节点(1) # Name: 192.168.42.134:9866 (hadoop) #名称:192.168.42.134:9866(hadoop) Hostname: hadoop #主机名:hadoop Decommission Status : Normal #退役状态:正常(未被移除) Configured Capacity: 19315818496 (17.99 GB) #配置容量:19315818496(17.99 GB) DFS Used: 1085440 (1.04 MB) #DFS已使用:1085440(1.04 MB) Non DFS Used: 7476367360 (6.96 GB) #非DFS使用:7476367360(6.96 GB) DFS Remaining: 11838365696 (11.03 GB) #DFS剩余:11838365696(11.03 GB) DFS Used%: 0.01% #DFS使用%:0.01% DFS Remaining%: 61.29% #DFS剩余%:61.29% Configured Cache Capacity: 0 (0 B) #配置的缓存容量:0(0 B) Cache Used: 0 (0 B) #缓存已使用:0(0 B) Cache Remaining: 0 (0 B) #缓存剩余:0(0 B) Cache Used%: 100.00% #缓存已使用%:100.00% Cache Remaining%: 0.00% #缓存剩余%:0.00% Xceivers: 1 #Xceivers: 1 Last contact: Fri Jul 20 04:58:17 EDT 2018 #上次连接时间: Last Block Report: Fri Jul 20 03:04:12 EDT 2018 #上次发送块报告时间: Num of Blocks: 10 #块数:10
(2) 进入安全模式
[root@hadoop mapreduce]# hdfs dfsadmin -safemode enter Safe mode is ON
(3) 退出安全模式
[root@hadoop mapreduce]# hdfs dfsadmin -safemode leave Safe mode is OFF
(4) 负载均衡
HDFS的数据在各个DataNode中的分布可能很不均匀,尤其是在DataNode节点出现故障或新增DataNode节点时。新增数据块时NameNode对DataNode节点的选择策略也有可能导致数据块分布的不均匀。用户可以使用命令重新平衡DataNode上的数据块的分布。
[root@hadoop mapreduce]# start-balancer.sh
11.HDFS 优点 VS 缺点
HDFS优点:
高容错性:数据自动保存多个副本;副本丢失后,自动恢复。
适合批处理:移动计算而非数据;数据位置暴露给计算框架。
适合大数据处理:GB、TB、甚至PB级数据;百万规模以上的文件数量;10K+节点。
可构建在廉价机器上:通过多副本提高可靠性;提供了容错和恢复机制。
HDFS缺点:
不适合低延迟数据访问:比如毫秒级;低延迟与高吞吐率。
不适合小文件存取:占用NameNode大量内存;寻道时间超过读取时间。
不适合并发写入、文件随机修改:一个文件只能有一个写者;仅支持append。
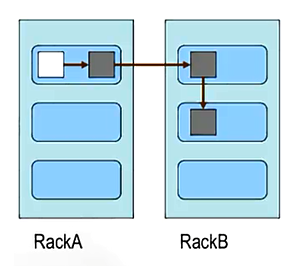
12.Block的副本放置策略
第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在与第一个副本不同的机架的节点上。
第三个副本:与第二个副本相同机架的节点上。
更多副本:随机节点。
13.HDFS文件权限
与linux文件权限类似:r:read;w:write;x:execte,权限x对于文件忽略,对于文件夹表示是否允许访问其内容。
如果Linux系统用户zhangsan使用Hadoop命令创建一个文件,那么这个文件在HDFS中owner就是zhangsan。
HDFS的权限目的:阻止好人做错事,而不是阻止坏人做错事。HDFS详细,你告诉我你是谁,我就认为你是谁。说白了,就是HDFS不做密码认证(不知道新版本有没有做这个功能?)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号