

10:信息收集-资产监控拓展
1、本课重点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # Github监控 便于收集整理最新exp或poc 便于发现相关测试目标的资产# 各种子域名查询# DNS,备案,证书# 全球节点请求cdn 枚举爆破或解析子域名对应 便于发现管理员相关的注册信息# 黑暗引擎相关搜索 fofa, shodan, zoomeye # 微信公众号接口获取# 内部群内部资源 |
2、演示案例
1.监控最新的EXP发布及其他
server酱:http://sc.ftqq.com/3.version
GitHub项目监控地址:https://github.com/weixiao9188/wechat_push
以下脚本使用之前,需要修改监控内容、注册github账号、注册Server酱账号(用于微信推送)

# Title: wechat push CVE-2020 # Date: 2020-5-9 # Exploit Author: weixiao9188 # Version: 4.0 # Tested on: Linux,windows # coding:UTF-8 import requests import json import time import os import pandas as pd time_sleep = 20 #每隔20秒爬取一次 while(True): headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"} #判断文件是否存在 datas = [] response1=None response2=None if os.path.exists("olddata.csv"): #如果文件存在则每次爬取10个 df = pd.read_csv("olddata.csv", header=None) datas = df.where(df.notnull(),None).values.tolist()#将提取出来的数据中的nan转化为None response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2020&sort=updated&per_page=10", headers=headers) response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&per_page=10", headers=headers) else: #不存在爬取全部 datas = [] response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2020&sort=updated&order=desc",headers=headers) response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&order=desc",headers=headers) data1 = json.loads(response1.text) data2 = json.loads(response2.text) for j in [data1["items"],data2["items"]]: for i in j: s = {"name":i['name'],"html":i['html_url'],"description":i['description']} s1 =[i['name'],i['html_url'],i['description']] if s1 not in datas: #print(s1) #print(datas) params = { "text":s["name"], "desp":" 链接:"+str(s["html"])+"\n简介"+str(s["description"]) } print("当前推送为"+str(s)+"\n") print(params) requests.get("https://sc.ftqq.com/XXXX.send",params=params,timeout=10) #time.sleep(1)#以防推送太猛 print("推送完成!") datas.append(s1) else: pass #print("数据已处在!") pd.DataFrame(datas).to_csv("olddata.csv",header=None,index=None) time.sleep(time_sleep)
2.黑暗引擎实现域名端口收集
fofa, shodan, zoomeye
3.子域名收集
(1)常见的子域名收集方法

(2)域名收集及枚举工具-提莫(teemo)
项目地址:https://github.com/bit4woo/teemo
(3)Layer子域名挖掘机
4.SRC目标中的信息收集全覆盖
补天上专属SRC简易测试
黑暗引擎搜索
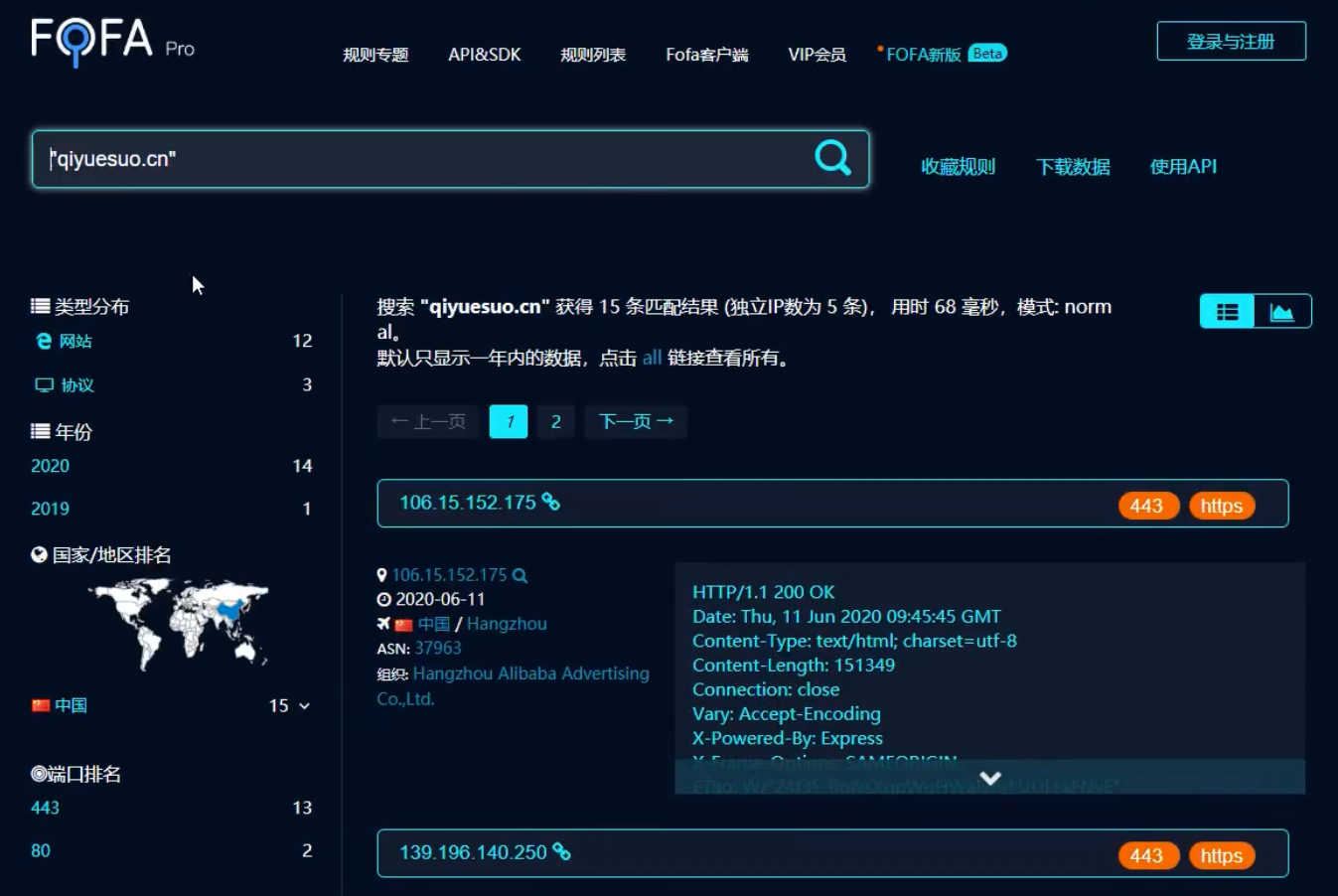
5.利用其他第三方接口获取更多信息
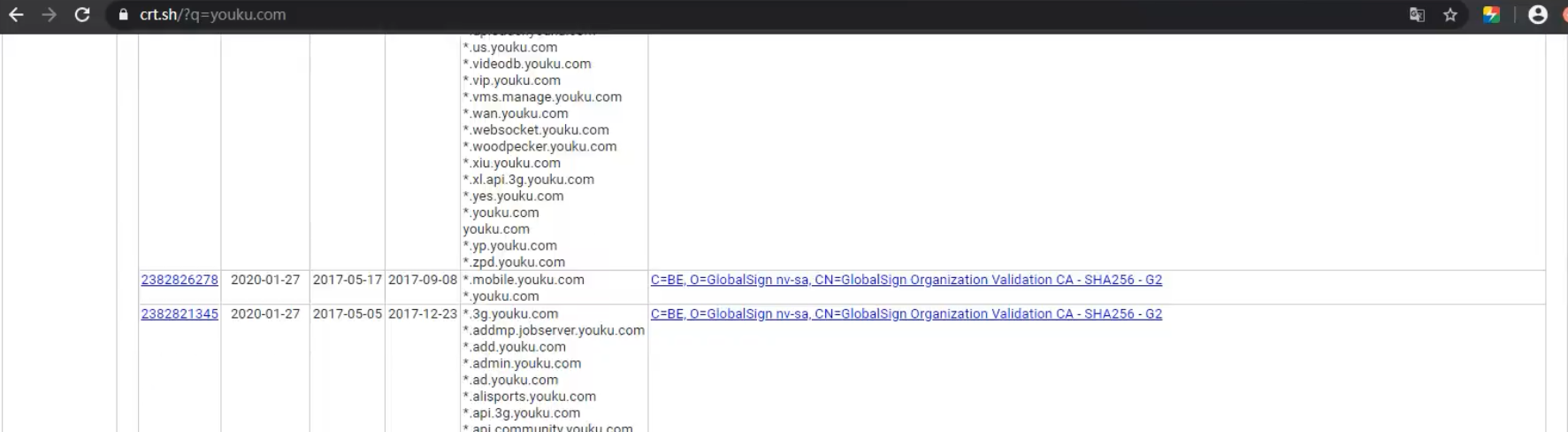
查询子域名和证书 https://crt.sh
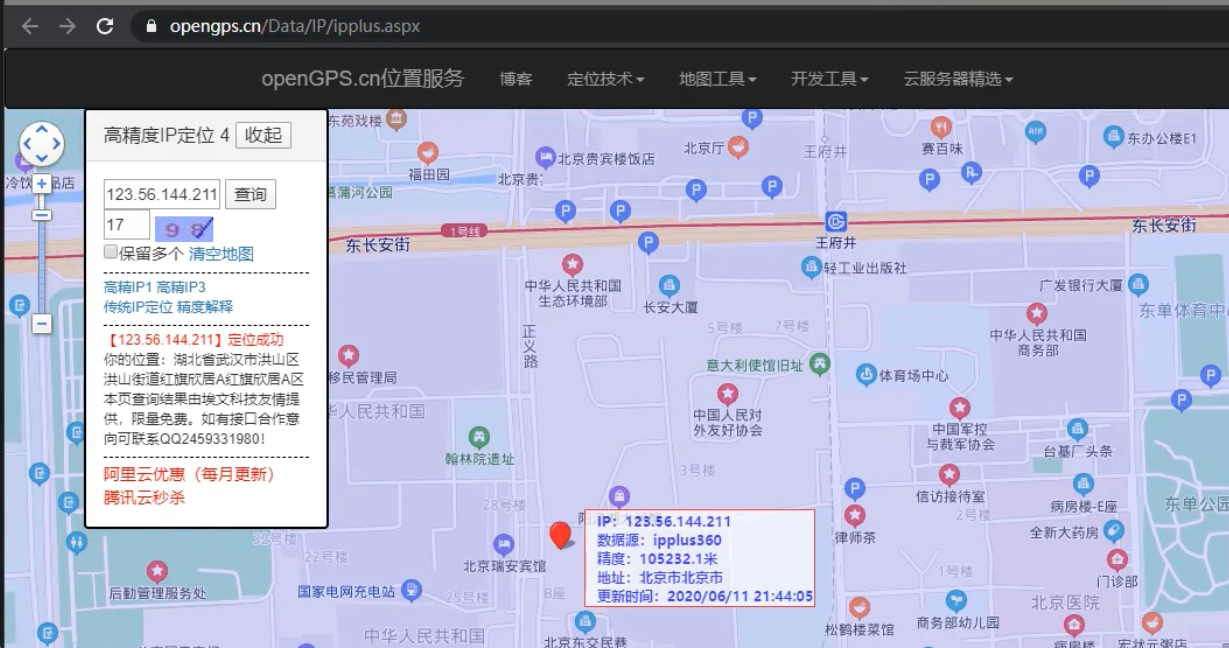
IP定位



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通