
YUV与RGB相互转换的指令优化
我在前面的两篇随笔中,写到了YUV与RGB的互转公式,也写了一些SSE指令学习的常用指令。因为接下来我决定暂停对SSE指令的简单翻译,而要把他用到实践中去。因此会贴上大篇幅的看起来让人头晕目眩的代码,不过我会尽力写好注释,以免大家看起来比较费劲。
既然说SSE能够对重复大量相同运算的数据在运算效率上有很大的提升,那就需要与高级语言(因为我常用的是C++,所以就采用C++语言)做一个对比。
在此之前,我要提前做一下说明,YUV我采用的4:2:2的压缩方式,也就是两个Y分量公用一组UV分量,并且每个YUV分量分别占10bit,但是考虑的内存对齐,YUV分量其实分别占用2个字节,并且我在这里使用的公式BT709的数字RGB与数字YUV的转换公式。
如果不清楚转换公式,可以转到我的一篇关于YUV与RGB互转的公式总结的随笔。
http://www.cnblogs.com/zhengjianhong/p/7872459.html
C++代码如下:
void RGB2YUV(OUT ushort &Y, OUT ushort &U, OUT ushort &V, IN const BYTE r, IN const BYTE g, IN const BYTE b)
{ Y = ushort(16 + 0.183 * r + 0.614 * g + 0.062 * b + 0.5); U = ushort(128 - 0.101 * r - 0.339 * g + 0.439 * b + 0.5); V = ushort(128 + 0.439 * r - 0.399 * g - 0.040* b + 0.5); }
bool RGB2YUV422_10BIT_CPLUSPLUS(OUT void* pYUV, IN void *pRGB, int nPixelCount, bool bAlpha) { if(pYUV == NULL || pRGB == NULL || nPixelCount <= 0) return false; // RGB 到 YUV422 10bit的转换 BYTE *pRGBByte = (BYTE *)pRGB; ushort *pYUVShort = (ushort *)pYUV; int nBitCount = 3; if(bAlpha) nBitCount = 4; for(int i = 0; i < nPixelCount; i += 2) { // 第一个像素 ushort y, u, v;
pRGBByte += nBitCount;
RGB2YUV(y, u, v, *(pRGBByte), *(pRGBByte + 1), *(pRGBByte + 2)); *(pYUVShort + 2 * i) = y; *(pYUVShort + 2 * i + 1) = u; *(pYUVShort + 2 * i + 3) = v; // 第二个像素
pRGBByte += nBitCount;
RGB2YUV(y, u, v, *(pRGBByte), *(pRGBByte + nBitCount * (i + 1) + 1), *(pRGBByte + nBitCount * (i + 1) + 2));
*(pYUVShort + 2 * i + 2) = y;
}
return true;
}
SSE代码如下:
// 在这里我考虑在精度允许的情况下,综合考虑在不产生进位的情况下对RGB转YUV的因子做了放大处理(放大256倍),以消除浮点运算,提高指令的执行效率。
实现思路:一条跳转指令完成8个像素的处理,先将8个像素的RGB分量分别用一个128位寄存器来存储,RGB的每个分量占2个字节, 并且用128位来存储每个转换因子,每个因子一样占2个字节。简单点说就是
(R0R1 R2R3 R4R5 R6R7) * (YrYr YrYr YrYr YrYr) 这样就计算出了构成Y的R部分简称YR,以此类推,分别计算出YG, YB,然后在将YR,YG,YB做加法运算,最终计算出Y的结果。
// 因子的顺序为YrYg YbUr UgUb VgVb // Vr = Ub
__declspec(align(16)) short dwRGB2YCbCrCoefFR256[8] = {77, 150, 29, -43, -85, 128, -107, -21}; // Full Range __declspec(align(16)) short dwRGB2YCbCrCoefHD256[8] = {47, 157, 16, -26, -87, 112, -102, -10}; __declspec(align(16)) short dwRGB2YCbCrCoefSD256[8] = {66, 129, 25, -38, -74, 112, -94, -18};
bool RGBA2YUV422_10BIT_SSE_Nofloat(OUT void* pYUV, IN void *pRGB, int nPixelCount, short* dwRGBA2YCbCrCoef) { if(pYUV == NULL || pRGB == NULL || nPixelCount <= 0) return false; int n32 = nPixelCount / 8; int m32 = nPixelCount % 8; BYTE *pByte = (BYTE *)pRGB; ushort *pYuvShort = (ushort *)pYUV; __m128i _m128i; __asm { mov esi, pByte; mov edi, pYuvShort; mov ecx, n32; mov edx, m32; mov eax, dwRGBA2YCbCrCoef; movaps xmm7, [eax]; movaps _m128i, xmm7; prefetchnta [esi]; test ecx, ecx; jz loop_m32; loop_32: prefetchnta [esi + 32]; // prefetchnta指令,将内存数据加载到缓存中,提高指令的数据命中率 movups xmm0, [esi]; // A3B3G3R3 A2B2G2R2 A1B1G1R1 A0B0G0R0 movups xmm1, [esi + 16]; // A7B7G7R7 A6B6G6R6 A5B5G5R5 A4B4G4R4 pand xmm0, dwMaskA; // 0B3G3R3 0B2G2R2 0B1G1R1 0B0G0R0 pand xmm1, dwMaskA; // 0B7G7R7 0B6G6R6 0B5G5R5 0B4G4R4 movaps xmm2, xmm0; movaps xmm3, xmm1; pand xmm2, dwMaskR; // 000R3 000R2 000R1 000R0 pand xmm3, dwMaskR; // 000R7 000R6 000R5 000R4 packssdw xmm2, xmm3; // 0R70R6 0R50R4 0R30R2 0R10R0 movaps xmm3, xmm0; movaps xmm4, xmm1; psrld xmm3, 8; psrld xmm4, 8; pand xmm3, dwMaskR; // 000G3 000G2 000G1 000G0 pand xmm4, dwMaskR; // 000G7 000G6 000G5 000G4 packssdw xmm3, xmm4; // 0G70G6 0G50G4 0G30G2 0G10G0 movaps xmm4, xmm0; movaps xmm5, xmm1; psrld xmm4, 16; psrld xmm5, 16; pand xmm4, dwMaskR; // 000B3 000B2 000B1 000B0 pand xmm5, dwMaskR; // 000B7 000B6 000B5 000B4 packssdw xmm4, xmm5; // 0B70B6 0B50B4 0B30B2 0B10B0 movaps xmm0, xmm7; // VbVg UbUg UrYb YgYr // 系数 pshuflw xmm0, xmm0, 0x00; // VbVg UbUg YrYr YrYr shufps xmm0, xmm0, 0x00; // YrYr YrYr YrYr YrYr movups _m128i, xmm0; movaps xmm1, xmm2; pmullw xmm1, xmm0; // YR7YR6 YR5YR4 YR3Yr2 YR1YR0 movups _m128i, xmm1; movaps xmm0, xmm7; pshuflw xmm0, xmm0, 0x05; // VbVg UbUg YrYr YgYg shufps xmm0, xmm0, 0x00; // YgYg YgYg YgYg YgYg movups _m128i, xmm0; movaps xmm5, xmm3; pmullw xmm5, xmm0; // YG7YG6 YG5YG4 YG3YG2 YG1YG0 paddw xmm1, xmm5; // YR+YG movups _m128i, xmm1; movaps xmm0, xmm7; pshuflw xmm0, xmm0, 0x0a; // VbVg UbUg YrYr YbYb shufps xmm0, xmm0, 0x00; // YbYb YbYb YbYb YbYb movups _m128i, xmm0; movaps xmm5, xmm4; pmullw xmm5, xmm0; // YB7YB6 YB5YB4 YB3YB2 YB1YB0 paddw xmm1, xmm5; // YR+YG+YB movups _m128i, xmm1; paddw xmm1, dwAdjust128; psrlw xmm1, 8; // Y7Y6 Y5Y4 Y3Y2 Y1Y0 movups _m128i, xmm1; movaps xmm0, xmm7; pshuflw xmm0, xmm0, 0x0f; // VbVg UbUg YrYr UrUr; shufps xmm0, xmm0, 0x00; // UrUr UrUr UrUr UrUr movups _m128i, xmm0; movaps xmm5, xmm2; pmullw xmm5, xmm0; // UR7UR6 UR5UR4 UR3UR2 UR1UR0 movups _m128i, xmm5; movaps xmm0, xmm7; pshufhw xmm0, xmm0, 0x00; // UgUg UgUg UrYb YgYr shufps xmm0, xmm0, 0xaa; // UgUg UgUg UgUg UgUg movups _m128i, xmm0; movaps xmm6, xmm3; pmullw xmm6, xmm0; // UG7UG6 UG5UG4 UG3UG2 UG1UG0 movups _m128i, xmm6; paddw xmm5, xmm6; // UR+UG movups _m128i, xmm5; movaps xmm0, xmm7; pshufhw xmm0, xmm0, 0x05; // UgUg UbUb UrYb YgYr shufps xmm0, xmm0, 0xaa; // UbUb UbUb UbUb UbUb movups _m128i, xmm0; movaps xmm6, xmm4; pmullw xmm6, xmm0; // UB7UB6 UB5UB4 UB3UB2 UB1UB0 movups _m128i, xmm6; paddw xmm5, xmm6; // UR + UG + UB movups _m128i, xmm5; paddw xmm5, dwAdjust; paddw xmm5, dwAdjust128; movups _m128i, xmm5; psrlw xmm5, 8; // U7U6 U5U4 U3U2 U1U0 movups _m128i, xmm5; pmullw xmm2, xmm0; // VR7VR6 VR5VR4 VR3VR2 VR1VR0 movaps xmm0, xmm7; pshufhw xmm0, xmm0, 0xaa; // VgVg VgVg UrYb YgYr shufps xmm0, xmm0, 0xaa; // VgVg VgVg VgVg VgVg pmullw xmm3, xmm0; // VG7VG6 VG5VG4 VG3VG2 VG1VG0 paddw xmm2, xmm3; // VR + VG movaps xmm0, xmm7; pshufhw xmm0, xmm0, 0xff; // VbVb VbVb UrYb YgYr shufps xmm0, xmm0, 0xaa; // VbVb VbVb VbVb VbVb pmullw xmm4, xmm0; // VB7VB6 VB5VB4 VB3VB2 VB1VB0 paddw xmm2, xmm4; // VR + VG + VB paddw xmm2, dwAdjust; paddw xmm2, dwAdjust128; psrlw xmm2, 8; // V7V6 V5V4 V3V2 V1V0 movaps xmm4, xmm5; punpcklwd xmm4, xmm2; // V3U3 V2U2 V1U1 V0U0 punpckhwd xmm5, xmm2; // V7U7 V6U6 V5U5 V4U4 shufps xmm4, xmm5, 0x88; // V6U6 V4U4 V2U2 V0U0 movaps xmm3, xmm1; punpcklwd xmm3, xmm4; // V2Y3 U2Y2 V0Y1 U0Y0 punpckhwd xmm1, xmm4; // V6Y7 U6Y6 V4Y5 U4Y4 movups [edi], xmm3; movups [edi + 16], xmm1; add edi, 32; add esi, 32; dec ecx; jnz loop_32; loop_m32: test edx, edx; jz loop_exit; cmp edx, 4; jl loop_2pixel; movups xmm0, [esi]; //A3B3G3R3 A2B2G2R2 A1B1G1R1 A0B0G0R0 pand xmm0, dwMaskA; // 0B3G3R3 0B2G2R2 0B1G1R1 0B0G0R0 movaps xmm1, xmm0; pand xmm1, dwMaskR; // 000R3 000R2 000R1 000R0 pshuflw xmm1, xmm1, 0xd8; // 000R3 000R2 0000 0R10R0 pshufhw xmm1, xmm1, 0xd8; // 0000 0R30R2 0000 0R10R0 shufps xmm1, xmm1, 0xd8; // 0000 0000 0R30R2 0R10R0 movaps xmm2, xmm0; psrld xmm2, 8; pand xmm2, dwMaskR; pshuflw xmm2, xmm2, 0xd8; pshufhw xmm2, xmm2, 0xd8; shufps xmm2, xmm2, 0xd8; // 0000 0000 0G30G2 0G10G0 movaps xmm3, xmm0; psrld xmm3, 16; pand xmm3, dwMaskR; pshuflw xmm3, xmm3, 0xd8; pshufhw xmm3, xmm3, 0xd8; shufps xmm3, xmm3, 0xd8; // 0000 0000 0B30B2 0B10B0 movaps xmm0, xmm7; // VbVg UbUg UrYb YgYr pshuflw xmm0, xmm0, 0x00; // VbVg UbUg YrYr YrYr movups xmm4, xmm1; pmullw xmm4, xmm0; // 0000 0000 YR3YR2 YR1YR0 movaps xmm0, xmm7; pshuflw xmm0, xmm0, 0x55; // VbVg UbUg YgYg YgYg movaps xmm5, xmm2; pmullw xmm5, xmm0; // 0000 0000 YG3YG2 YG1YG0 paddw xmm4, xmm5; // 00 00 (YR+YG)(YR+YG) (YR+YG)(YR+YG) movaps xmm0, xmm7; pshuflw xmm0, xmm0, 0xaa; // VbVg UbUg YbYb YbYb movups xmm5, xmm3; pmullw xmm5, xmm0; // 00 00 YB3YB2 YB1YB0 paddw xmm4, xmm5; // 00 00 Y3Y2 Y1Y0 psrlw xmm4, 8; movaps xmm0, xmm7; pshuflw xmm0 ,xmm0, 0xff; // VbVb UbUg UrUr UrUr; movups xmm5, xmm1; pmullw xmm5, xmm0; // 00 00 UR3UR2 UR1UR0 movaps xmm0, xmm7; pshufhw xmm0, xmm0, 0x00; // UgUg UgUg UrYb YgYr shufps xmm0, xmm0, 0xee; // UgUg UgUg UgUg UgUg movups xmm6, xmm2; pmullw xmm6, xmm0; // 00 00 UG3UG2 UG1UG0 paddw xmm5, xmm6; // 00 00 U3'U2' U1'U0' movaps xmm0, xmm7; pshufhw xmm0, xmm0, 0x55; shufps xmm0, xmm0, 0xee; // UbUb UbUb UbUb UbUb movups xmm6, xmm3; pmullw xmm6, xmm0; // 00 00 UB3UB2 UB1UB0 paddw xmm5, xmm6; // 00 00 U3U2 U1U0 psrlw xmm5, 8; paddw xmm5, dwAdjust; pmullw xmm1, xmm0; // 00 00 VR3VR2 VR1VR0 movaps xmm0, xmm7; pshufhw xmm0, xmm0, 0xaa; // VgVg VgVg UrYb YgYr shufps xmm0, xmm0, 0xee; // VgVg VgVg VgVg VgVg; pmullw xmm2, xmm0; // 00 00 VG3VG2 VG1VG0 paddw xmm1, xmm2; // 00 00 U3'U2' U1'U0' movaps xmm0, xmm7; pshufhw xmm0, xmm0, 0xff; // VbVb VbVb UrYb YgYr shufps xmm0, xmm0, 0xee; // VbVb VbVb VbVb VbVb pmullw xmm3, xmm0; // 00 00 VB3VB2 VB1VB0 paddw xmm1, xmm3; // 00 00 V3V2 V1V0 psrlw xmm1, 8; paddw xmm1, dwAdjust; punpcklwd xmm5, xmm1; // V3U3 V2U2 V1U1 V0U0 shufps xmm5, xmm5, 0xd8; // V3U3 V1U1 V2U2 V0U0 punpcklwd xmm4, xmm5; // V2Y3 U2Y2 V0Y1 U0Y0 movups [edi], xmm4; add esi, 16; add edi, 16; sub edx, 4; jnz loop_m32; loop_2pixel: test edx, edx; jz loop_exit; cmp edx, 2; jl loop_spixel; movups xmm0, [esi]; pand xmm0, dwMaskA; // 0000 0000 0B1G1R1 0B0G0R0 movups xmm1, xmm0; pand xmm1, dwMaskR; // 0000 0000 000R1 000R0 pshuflw xmm1, xmm1, 0xd8; // 0000 0000 0000 0R10R0 movups xmm2, xmm0; psrld xmm2, 8; pand xmm2, dwMaskR; pshuflw xmm2, xmm2, 0xd8; // 0000 0000 0000 0G10G0 movups xmm3, xmm0; psrld xmm3, 16; pand xmm3, dwMaskR; pshuflw xmm3, xmm3, 0xd8; // 0000 0000 0000 0B10B0 movups xmm0, xmm7; // VbVg UbUg UrYb YgYr pshuflw xmm0, xmm0, 0x00; // VbVg UbUg YrYr YrYr; movups xmm4, xmm1; pmullw xmm4, xmm0; // 00 00 00 YR1YR0 movups xmm0, xmm7; pshuflw xmm0, xmm0, 0x55; movups xmm5, xmm2; pmullw xmm5, xmm0; // 00 00 00 YG1YG0 paddw xmm4, xmm5; // 00 00 00 Y1'Y0' movups xmm0, xmm7; pshuflw xmm0, xmm0, 0xaa; movups xmm5, xmm3; pmullw xmm5, xmm0; // 00 00 00 YB1YB0 paddw xmm4, xmm5; // 00 00 00 Y1Y0 psrlw xmm4, 8; movups xmm0, xmm7; pshuflw xmm0, xmm0, 0xff; movups xmm5, xmm1; pmullw xmm5, xmm0; // 00 00 00 UR1UR0 movups xmm0, xmm7; pshufhw xmm0, xmm0, 0x00; // UgUg UgUg .. .. shufps xmm0, xmm0, 0xee; // .. .. UgUg UgUg movups xmm6, xmm2; pmullw xmm6, xmm0; // 00 00 00 UG1 UG0; paddw xmm5, xmm6; movups xmm0, xmm7; pshufhw xmm0, xmm0, 0x55; shufps xmm0, xmm0, 0xee; movups xmm6, xmm3; pmullw xmm6, xmm0; // 00 00 00 UB1UB0 paddw xmm5, xmm6; // 00 00 00 U1U0 psrlw xmm5, 8; psrlw xmm5, dwAdjust; pmullw xmm1, xmm0; // 00 00 00 VR1VR0 movups xmm0, xmm7; pshufhw xmm0, xmm0, 0xaa; shufps xmm0, xmm0, 0xee; pmullw xmm2, xmm0; // 00 00 00 VG1VG0 paddw xmm1, xmm2; movups xmm0, xmm7; pshufhw xmm0, xmm0, 0xff; shufps xmm0, xmm0, 0xee; pmullw xmm3, xmm0; // 00 00 00 VB1VB0 paddw xmm1, xmm3; // 00 00 00 V1V0; punpcklwd xmm5, xmm1; // 00 00 V1U1 V0U0 punpcklwd xmm4, xmm5; // V10 U10 V0Y1 U0Y0 movlps [edi], xmm4; add edi, 8; add esi, 8; sub edx, 2; jnz loop_2pixel; loop_spixel: loop_exit: } return true; }
下面附上两种转换对比的贴图:

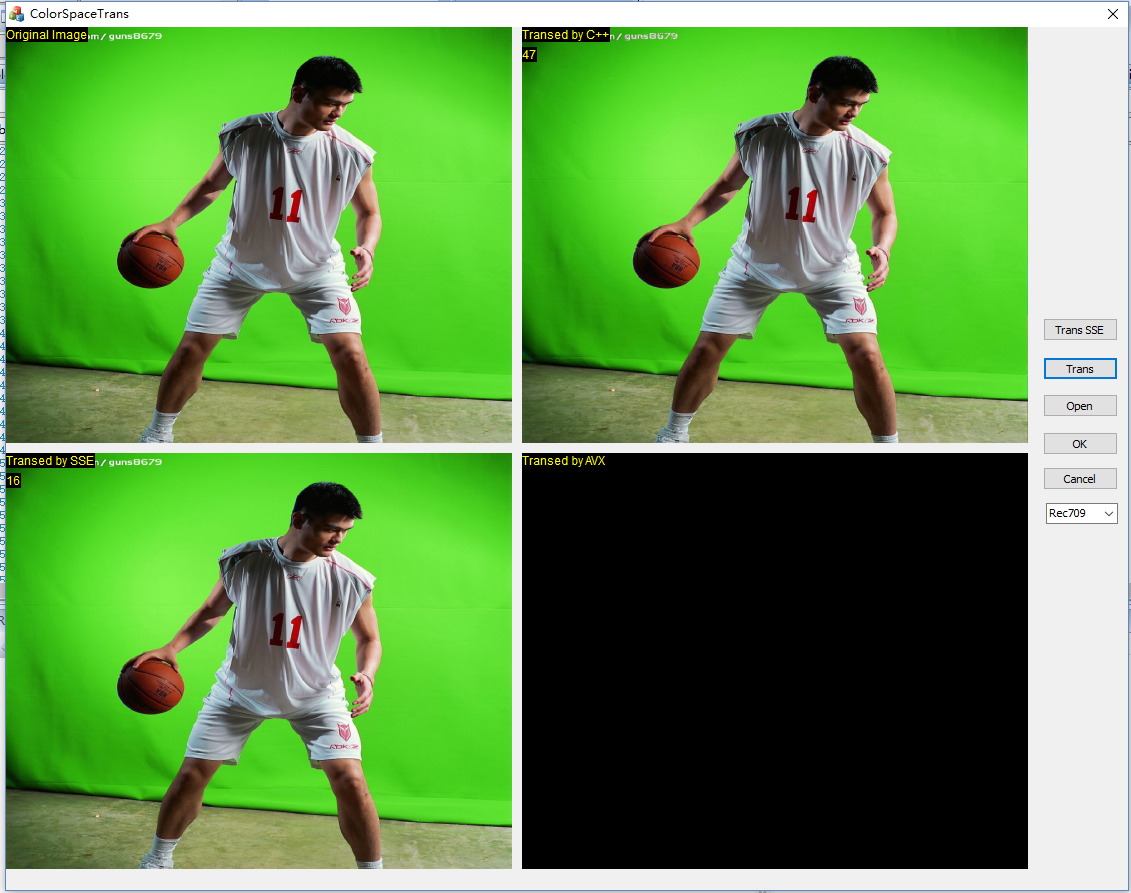
前面代表debug下的执行截图,后面表示Releas下的执行截图。总体而言SSE指令优化之后的代码执行效率比较稳定,而Release开启优化之后的C++代码提升比较明显,但是仍然没有SSE指令的效率高。
至于YUV转RGB的指令优化,有兴趣的同学,可以自己尝试写一下。
在这里,我也是刚刚入门SSE指令优化,如果有同学发现问题,还希望可以指出来。

