
外排序算法介绍
1.背景
2.外部排序算法基本思想
外部排序常采用的排序方法是归并排序,这种归并方法由两个不同的阶段组成:
(1)采用适当的内部排序方法对输入文件的每个片段进行排序,将排好序的片段(成为归并段)写到外部存储器中(通常由一个可用的磁盘作为临时缓冲区),这样临时缓冲区中的每个归并段的内容是有序的。
(2)利用归并算法,归并第一阶段生成的归并段,直到只剩下一个归并段为止。
2.1 两路归并
2.2 k路归并
2.2.1 败者树原理
败者树,顾名思义,即记录胜败者的树形结构。实际上,这种数据结构的最初灵感来源就是来自于比赛中记录胜败得分的。只不过在败者树中,父节点记录的是败者节点,而胜者节点继续上浮比较。
典型的4-路败者树结构如下图所示:
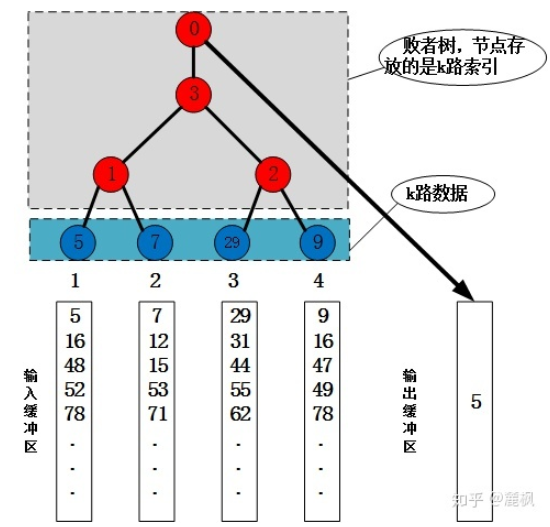
(1)多路平衡归并算法具体实现
a.初始化操作
b[0..k],其中0~k-1为k个叶节点,存放k路归并片段的首地址,k为虚拟记录,该关键字取可能的最小值minkey
ls[0..k-1],其中1~k-1存放不含叶节点的败者树的败者编号,0存放最后胜出的编号
b.处理步骤
a)建败者树ls[0..k-1]
b)重复下列操作直至k路归并完毕:
将b[ls[0]]写至输出归并段;
补充记录(某归并段变空时,补充数据),调整败者树。
2.2.2 堆排序、胜者树及败者树的联系
2.2.3 三种算法的相同点
这三种算法的空间和时间复杂度都是一样的,调整一次的时间复杂度都是O(logN)的,都利用了二叉树的性质。
2.2.4 三种算法的不同点
最早只有用堆来完成k路归并,但是堆每次取出最小值之后,把最后一个数放到堆顶,调整堆的时候,每次都要选出父节点的两个孩子节点的最小值,然后再用孩子节点的最小值和父节点进行比较,所以每调整一层需要比较两次。
为了简化比较过程,就有了胜者树,如图:
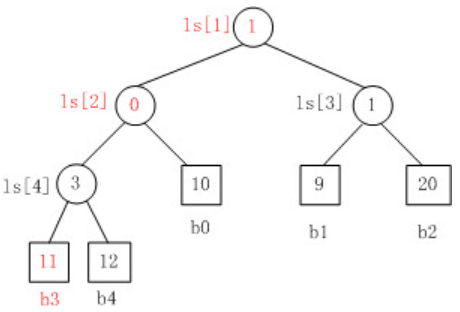
但不足的是,胜者树在节点上升的时候首先需要获得父节点,然后再获得兄弟节点后,再比较。
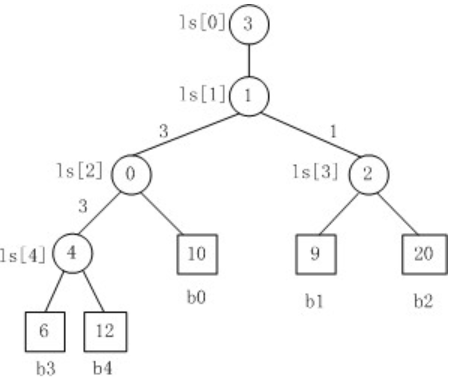
在使用败者树的时候,每个新元素上升时,只需要获得父节点并比较即可。
所以总的来说,败者树减少了访存的时间。现在程序的主要瓶颈在于访存,计算倒可以忽略不计了。
3. 败者树算法实现
例:合并k路有序链表
测试样例:
1 输入:[ 2 1->4->5, 3 1->3->4, 4 2->6 5 ] 6 输出:1->1->2->3->4->4->5->6
代码实现:
1 import sys 2 3 # Definition for singly-linked list. 4 class ListNode: 5 def __init__(self, x): 6 self.val = x 7 self.next = None 8 9 class Solution: 10 def mergeTwoLists(self, l1, l2): 11 """ 12 :type l1: ListNode 13 :type l2: ListNode 14 :rtype: ListNode 15 """ 16 17 if l1 == None: 18 return l2 19 if l2 == None: 20 return l1 21 22 dummy = ListNode(0) 23 head = dummy 24 while l1 != None and l2 != None: 25 if l1.val <= l2.val: 26 head.next = l1 27 l1 = l1.next 28 head = head.next 29 else: 30 head.next = l2 31 l2 = l2.next 32 head = head.next 33 34 while l1 != None: 35 head.next = l1 36 l1 = l1.next 37 head = head.next 38 while l2 != None: 39 head.next = l2 40 l2 = l2.next 41 head = head.next 42 43 return dummy.next 44 45 def adjust(self, s, listsLen, lists, loserTree): 46 #构成完全二叉树,按完全二叉树索引 47 t = (s + listsLen) // 2 48 # 比较当前节点和父节点的大小,若大于,则更新,并将胜者保存在索引0位置 49 while t > 0: 50 if lists[s].val > lists[loserTree[t]].val: 51 s, loserTree[t] = loserTree[t], s 52 t = t // 2 53 loserTree[0] = s 54 55 def mergeKLists(self, lists): 56 """ 57 :type lists: List[ListNode] 58 :rtype: ListNode 59 """ 60 # 去掉list中的None 61 while None in lists: 62 lists.remove(None) 63 # 若当前序列小于等于1,则返回结果 64 listsLen = len(lists) 65 if listsLen < 1: 66 return None 67 68 if listsLen == 1: 69 return lists[0] 70 # 使用内排序算法,归并路数不超过16,然后使用外排序进一步归并 71 while len(lists) > 16: 72 i, j = 0, len(lists) - 1 73 while i < j: 74 lists[i] = self.mergeTwoLists(lists[i], lists[j]) 75 lists.pop() 76 i += 1 77 j -= 1 78 79 # 初始化新节点,保存归并结果 80 dummy = ListNode(-sys.maxsize) 81 head = dummy 82 listsLen = len(lists) 83 84 # 使用外排序进行归并,若其中某路已归并完,则构造新的败者树 85 while listsLen > 0 and listsLen : 86 # 初始化败者树 87 loserTree = [listsLen] * listsLen 88 lists.append(ListNode(-sys.maxsize)) 89 for i in range(listsLen): 90 self.adjust(i, listsLen, lists, loserTree) 91 92 # k-归并,将每次胜者添加到链表的尾部,并读取下一个数,并更新败者树 93 while lists[loserTree[0]] != None: 94 pos = loserTree[0] 95 dummy.next = lists[pos] 96 dummy = dummy.next 97 lists[pos] = lists[pos].next 98 99 # 如果某一路归并完毕,则需要移除这一路 100 if lists[pos] == None: 101 break 102 # 更新败者树 103 self.adjust(pos, listsLen, lists, loserTree) 104 105 # 去掉归并完的路 106 while None in lists: 107 lists.remove(None) 108 listsLen -= 1 109 110 return head.next
4.算法分析
每次从k个组中的首元素中选一个最小的数,加入到新组,这样每次都要比较k-1次,故算法复杂度为O((n-1)(k-1))。
而如果使用败者树,可以在O(logk)的复杂度下得到最小的数,算法复杂度将为O((n-1)logk), 对于大数据场景的外部排序来说,这是一个不小的提高。
参考:
https://leetcode.com/problems/merge-k-sorted-lists/
https://blog.csdn.net/haolexiao/article/details/53488314
https://zhuanlan.zhihu.com/p/36618960
https://www.zhihu.com/question/35144290/answer/148681658
