


0.小问题
头文件和源文件名字可以不同
0.1 C和C++的头文件的变量声明和函数声明,是默认属于extern类型的吗?
---- 头文件中变量声明不使用extern,如果多次包含该头文件,会出现重复定义错误。全局变量一般限制在本c文件中使用,如果跨c文件使用,则extern声明
---- 声明可以拷贝n次,但是定义只能定义一次。
---- 全局函数的声明,关键字extern可以省略,因为全局函数默认是extern类型的。
总结:是的。(头文件变量的声明也是的)
----------------------------------------------------------------
公司一般不允许。
0.2 const char* g_str = "123456" 与 const char g_str[] ="123465"是不同的, 所以如果想让char* g_str遵守const的全局常量的规则,最好这么定义const char* const g_str="123456"。————没看明白为什么要这样定义?
---- const char* g_str是一个指针常量,const修饰的是char *,而不是g_str,也就是指针指向的内存地址是不可修改的,但该内存地址的内容可修改;
---- const char g_str[]是一个常量数组,const修饰的是char,即g_str的值不可修改
---- const char* const g_str是一个指向常量的常量指针,前一个const修改char *,表示指向的地址不可修改,后一个const修饰char,表示g_str的值不可修改,和const char g_str[]作用一样。
总结:const要分别修饰指针和字符变量。
----------------------------------------------------------------
--C语言中,const放到不同位置,修饰的作用是不同的,是变量指向的内容不能改变?还是变量本身不能改变(可以改变指向的内容)?还是都不能改变?
建议网上搜一下,然后写一段代码实际测试一下,是编译阶段报错?还是运行过程报错?
再进一步,不同的定义,objdump出来,看看各种定义放的位置相同吗?栈空间还是BSS?或者其它地方,动动手就有结果了(如果还有问题,明天讨论)
0.3 测试中的打桩(stub)和模拟(mock)
https://zhuanlan.zhihu.com/p/67199540
桩,或称桩代码,是指用来代替关联代码或者未实现代码的代码。如果函数func用func_stub来代替,那么,func称为原函数,func_stub称为桩函数。打桩就是编写或生成桩代码的过程。
目的:隔离、补齐、控制
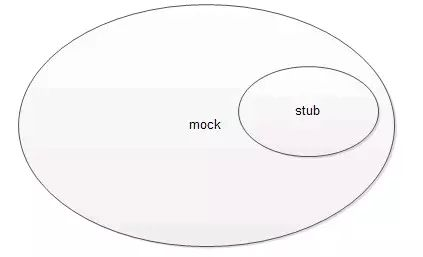
- stub存在的意图是为了让测试对象可以正常的执行,其实现一般会硬编码一些输入和输出。
- mock除了保证stub的功能之外,还可深入的模拟对象之间的交互方式,如:调用了几次、在某种情况下是否会抛出异常。
动态打桩:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | // stub_test.c : 定义控制台应用程序的入口点。#include "stub.h"#include <stdio.h>void add(int i){ printf("add(%d)\n",i);} void add_stub(int i){ printf("add_stub(%d)\n",i);} int main(){ INSTALL_STUB(add,add_stub); add(12); REMOVE_STUB(add_stub); add(11); return 0;} |
1 2 | add_stub(12)add(11) |
1.宏定义函数与普通函数的区别
#define MAX(a,b) ((a)>(b)?(a):(b))
int MAX1(int a,int b)
{
return a>b?a:b;
}
1)宏定义函数没有参数类型也不做类型检查,预编译阶段直接进行宏替换。所以对上面的宏定义函数他可以比较不同类型的数据大小,而普通函数则只能比较形参类型的大小。
2)宏定义函数时一定要注意括号的存在和匹配,有时会因为括号的不存在就会导致函数在计算的时候出现优先级错误的现象继而导致整个程序出错。
如果上面的函数式宏定义写成 #define MAX(a, b) (a>b?a:b),省去内层括号,则宏展开就成了k = (i&0x0f>j&0x0f?i&0x0f:j&0x0f),运算的优先级就错了。同样道理,这个宏定义的外层括号也是不能省的。若函数中是宏替换为 ++MAX(a,b),则宏展开就成了 ++(a)>(b)?(a):(b),运算优先级也是错了。
3)调用宏定义函数和普通函数生成的指令不同。
4)普通函数,表达式参数计算后传入;宏定义函数,表达式直接传入替换。
普通函数调用时先求实参表达式的值再传给形参,如果实参表达式有Side Effect,那么这些SideEffect只发生一次。例如MAX(++a, ++b),如果MAX是普通函数,a和b只增加一次。但如果MAX函数式宏定义,则要展开成k = ((++a)>(++b)?(++a):(++b)),a和b就不一定是增加一次还是两次了。所以若参数是表达式,替换函数式宏定义时一定要仔细看好。
5)宏定义函数可能会导致效率低下
如,#define max(n) (a[n]>max(n-1)?a[n]:max(n-1)),执行了两次。
尽管函数式宏定义和普通函数相比有很多缺点,但只要小心使用还是会显著提高代码的执行效率,毕竟省去了分配和释放栈帧、传参、传返回值等一系列工作,因此那些简短并且被频繁调用的函数经常用函数式宏定义来代替实现。
https://blog.csdn.net/u013167809/article/details/48348213
2.linux经典代码——头文件实现链表
https://elixir.bootlin.com/linux/v5.8-rc3/source/include/linux/list.h
3.linux开机启动脚本顺序
/etc/profile
/etc/profile.d/*.sh
~/bash_profile
~/.bashrc
/etc/bashrc
http://3ms.huawei.com/km/blogs/details/5777647
/etc/profile -> ~/.bash_profile -> ~/.bashrc -> /etc/bashrc -> ~/.bash_logout
/etc/profile :这个文件预设了几个重要的变量,例如PATH, USER, LOGNAME, MAIL, INPUTRC, HOSTNAME, HISTSIZE, umask等等。
/etc/bashrc :这个文件主要预设umask以及PS1。这个PS1就是我们在敲命令时,前面那串字符了,例如 [root@localhost ~]#,当bash shell被打开时,该文件被读取
.bash_profile :定义了用户的个人化路径与环境变量的文件名称。每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该文件仅仅执行一次。(在这个文件中有执行.bashrc的脚本)
.bashrc :该文件包含专用于你的shell的bash信息,当登录时以及每次打开新的shell时,该该文件被读取。例如你可以将用户自定义的alias或者自定义变量写到这个文件中。
.bash_history :记录命令历史用的。
.bash_logout :当退出shell时,会执行该文件。可以把一些清理的工作放到这个文件中。
4.linux常用命令总结
wall
file test.txt 查看文件类型等等
ln 硬连接
ln -s 符号连接
chmod
alias 设置指令的别名(一般仅限本次登陆有效,每次都有效可在.profile或.cshrc中设定指令的别名)
fdisk -l 分区工具,查看挂载的设备
fdisk /dev/xvde1 进入设备
文件类型:
-:普通文件 (f)
d:目录文件
b:块设备文件 (block)
c:字符设备文件 (character)
l:符号链接文件(symbolic link file)
p:命令管道文件(pipe)
s:套接字文件(socket)
网络相关:
cat /etc/resolv.conf 查看DNS
mount 挂载设备(将Linux本身的文件目录与硬件设备的文件目录合二为一,硬件设备才能为我们所用。合二为一的过程称为“挂载”。如果不挂载,通过Linux系统中的图形界面系统可以查看找到硬件设备,但命令行方式无法找到。)
5.linux系统启动详细过程
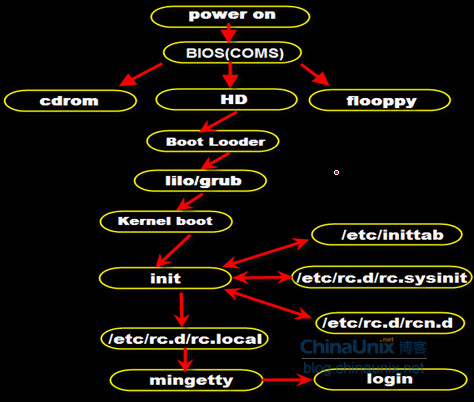
启动第一步--加载BIOS 当你打开计算机电源,计算机会首先加载BIOS信息,BIOS信息是如此的重要,以至于计算机必须在最开始就找到它。
这是因为BIOS中包含了CPU的相关信息、设备启动顺序信息、硬盘信息、内存信息、时钟信息、PnP特性等等。
在此之后,计算机心里就有谱了,知道应该去读取哪个硬件设备了。 启动第二步--读取MBR 众所周知,硬盘上第0磁道第一个扇区被称为MBR,也就是Master Boot Record,即主引导记录,
它的大小是512字节,别看地方不大,可里面却存放了预启动信息、分区表信息。 系统找到BIOS所指定的硬盘的MBR后,就会将其复制到0×7c00地址所在的物理内存中。
其实被复制到物理内存的内容就是Boot Loader,而具体到你的电脑,那就是lilo或者grub了。 启动第三步--Boot Loader Boot Loader 就是在操作系统内核运行之前运行的一段小程序。
通过这段小程序,我们可以初始化硬件设备、建立内存空间的映射图,
从而将系统的软硬件环境带到一个合适的状态,以便为最终调用操作系统内核做好一切准备。 Boot Loader有若干种,其中Grub、Lilo和spfdisk是常见的Loader。 我们以Grub为例来讲解吧,毕竟用lilo和spfdisk的人并不多。 系统读取内存中的grub配置信息(一般为menu.lst或grub.lst),并依照此配置信息来启动不同的操作系统。 启动第四步--加载内核 根据grub设定的内核映像所在路径,系统读取内存映像,并进行解压缩操作。
此时,屏幕一般会输出“Uncompressing Linux”的提示。当解压缩内核完成后,屏幕输出“OK, booting the kernel”。 系统将解压后的内核放置在内存之中,并调用start_kernel()函数来启动一系列的初始化函数并初始化各种设备,完成Linux核心环境的建立。
至此,Linux内核已经建立起来了,基于Linux的程序应该可以正常运行了。 启动第五步--用户层init依据inittab文件来设定运行等级 内核被加载后,第一个运行的程序便是/sbin/init,该文件会读取/etc/inittab文件,并依据此文件来进行初始化工作。 其实/etc/inittab文件最主要的作用就是设定Linux的运行等级,其设定形式是“:id:5:initdefault:”,这就表明Linux需要运行在等级5上。
Linux的运行等级设定如下: 0:关机 1:单用户模式 2:无网络支持的多用户模式 3:有网络支持的多用户模式 4:保留,未使用 5:有网络支持有X-Window支持的多用户模式 6:重新引导系统,即重启 关于/etc/inittab文件的学问,其实还有很多 启动第六步--init进程执行rc.sysinit 在设定了运行等级后,Linux系统执行的第一个用户层文件就是/etc/rc.d/rc.sysinit脚本程序,
它做的工作非常多,包括设定PATH、设定网络配置(/etc/sysconfig/network)、启动swap分区、设定/proc等等。
如果你有兴趣,可以到/etc/rc.d中查看一下rc.sysinit文件,里面的脚本够你看几天的 启动第七步--启动内核模块 具体是依据/etc/modules.conf文件或/etc/modules.d目录下的文件来装载内核模块。 启动第八步--执行不同运行级别的脚本程序 根据运行级别的不同,系统会运行rc0.d到rc6.d中的相应的脚本程序,来完成相应的初始化工作和启动相应的服务。 启动第九步--执行/etc/rc.d/rc.local 你如果打开了此文件,里面有一句话,读过之后,你就会对此命令的作用一目了然: # This script will be executed *after* all the other init scripts. # You can put your own initialization stuff in here if you don’t # want to do the full Sys V style init stuff. rc.local就是在一切初始化工作后,Linux留给用户进行个性化的地方。你可以把你想设置和启动的东西放到这里。 启动第十步--执行/bin/login程序,进入登录状态 此时,系统已经进入到了等待用户输入username和password的时候了,你已经可以用自己的帐号登入系统了。:)
登录之后开始以shell控制主机
在root下,可以直接运行/bin/login进行用户登陆。
https://www.cnblogs.com/linux985/p/13297523.html?utm_source=tuicool
6.extern关键字
表示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义。
两个作用:
1.当它与"C"一起连用时,如: extern "C" void fun(int a, int b);告诉编译器在编译fun这个函数名时按着C的规则去翻译相应的函数名而不是C++的,C++的规则在翻译这个函数名时会把fun这个名字变得面目全非,可能是fun@aBc_int_int#%$也可能是别的(不同编译器不同),因为C++支持函数的重载。(详细转到我另一篇博客:https://www.cnblogs.com/WindSun/p/11334182.html)
2.在头文件中: extern int g_Int; 它的作用就是声明全局变量或函数的作用范围的关键字,其声明的函数和变量可以在本模块或其他模块中使用,记住它是一个声明不是定义。也就是说B模块如果引用A模块中定义的全局变量或函数时,它只要包含A模块的头文件即可,在编译阶段,模块B虽然找不到该函数或变量,但它不会报错,它会在连接时从模块A生成的目标代码中找到此函数。
常用的用法:
extern用在变量声明中常常有这样一个作用,在*.c文件中声明了一个全局的变量,这个全局的变量如果要被引用,就放在*.h中并用extern来声明。
非常规的用法:
在要引用的.c文件中要引用外部的变脸或者函数,先extern声明,然后直接使用;在其他的.c文件中要对该函数有声明(?会带extern?不需要声明也行?)和定义。
注意地方:
1)一定要同类型的变量
2)全局变量在文件头只能声明,不能定义。不然多个文件包含时,会重复定义,导致错误。除非头文件只被定义的C文件包含,然后其他要引用的C文件进行extern声明之后再引用。
extern和static
static定义的变量和函数只能放到.c里面,因为有static的是直接定义了的。如果放.h里面,其他.c调用,就会重复定义,但是物理地址是不同的,所以不会报错。当然编译器优化,有可能会优化到同一个物理地址上去,但是如果在某个.c里面修改了该变量,编译器便不会优化。
extern 和const
const修饰的全局变量与static有相同的特性,它们只能作用于本编译模块中。
当const单独使用时它就与static相同,而当与extern一起合作的时候,它的特性就跟extern的一样了!
(???)const char* g_str = "123456" 与 const char g_str[] ="123465"是不同的, 前面那个const 修饰的是char *而不是g_str,它的g_str并不是常量,它被看做是一个定义了的全局变量(可以被其他编译单元使用), 所以如果你像让char*g_str遵守const的全局常量的规则,最好这么定义const char* const g_str="123456"。
头文件的变量和函数声明,一般默认是加了extern吗?
https://www.cnblogs.com/WindSun/p/11434436.html
在C++里面的应用:
C++里面使用extern的函数与c的一样;变量声明也已一样,但是在.h文件定义变量后,通过其他cpp进行include的方式,不能访问该变量,只能去掉include,然后在cpp里面使用extern声明,才能成功。
https://www.cnblogs.com/WindSun/p/11334182.html
(???)编译过程,是对每个.c文件进行单独编译吗?然后再连接?连接的时候,include了相同.h文件的.c,怎么解决包含冲突,是直接根据相同的.h进行连接?
只要.c没被包含,都是单独编译成.o文件,然后进行连接。包含的.h一般只是声明,只要有任意一个.c文件对声明的变量进行了定义,就可以在连接的时候,进行重定位操作等。https://zhidao.baidu.com/question/277923200.html
7.公司编程规范
1)变量用小驼峰,函数名用大驼峰,文件名用小写与下划线
2)公司一般不允许使用extern

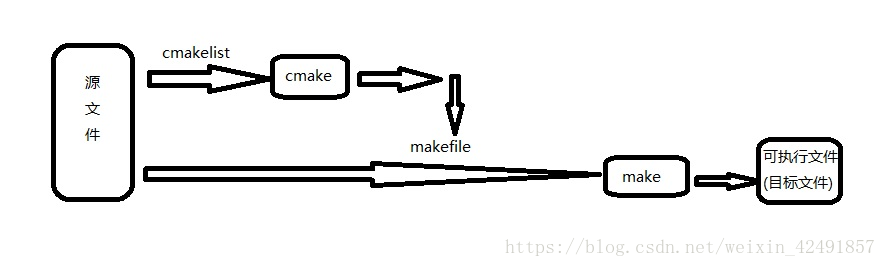
8.make与cmake关系,xmake
写程序大体步骤为:
1.用编辑器编写源代码,如.c文件。
2.用编译器编译代码生成目标文件,如.o。
3.用链接器连接目标代码生成可执行文件,如.exe。
但如果源文件太多,一个一个编译时就会特别麻烦,于是人们想到,为什么不设计一种类似批处理的程序,来批处理编译源文件呢,于是就有了make工具,它是一个自动化编译工具,你可以使用一条命令实现完全编译。但是你需要编写一个规则文件,make依据它来批处理编译,这个文件就是makefile,所以编写makefile文件也是一个程序员所必备的技能。
对于一个大工程,编写makefile实在是件复杂的事,于是人们又想,为什么不设计一个工具,读入所有源文件之后,自动生成makefile呢,于是就出现了cmake工具,它能够输出各种各样的makefile或者project文件,从而帮助程序员减轻负担。但是随之而来也就是编写cmakelist文件,它是cmake所依据的规则。所以在编程的世界里没有捷径可走,还是要脚踏实地的。
https://www.cnblogs.com/yinlili/p/10869525.html
makefile的写法
自动变量有很多,常用的有三个:
$<:第一个依赖文件;
$@:目标;
$^:所有不重复的依赖文件,以空格分开
1 2 3 4 5 6 7 8 9 | obj = main.o fun1.o fun2.o target = app CC = gcc $(target): $(obj) $(CC) $(obj) -o $(target) %.o: %.c $(CC) -c $< -o $@ |
wildcard:
扩展通配符,搜索指定文件。在此我们使用src = $(wildcard ./*.c),代表在当前目录下搜索所有的.c文件,并赋值给src。函数执行结束后,src的值为:main.c fun1.c fun2.c。
patsubst:
替换通配符,按指定规则做替换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | src = $(wildcard ./*.c) obj = $(patsubst %.c, %.o, $(src)) #obj = $(src:%.c=%.o) target = app CC = gcc $(target): $(obj) $(CC) $(obj) -o $(target) %.o: %.c $(CC) -c $< -o $@ .PHONY: clean clean: rm -rf $(obj) $(target) |
https://www.zhihu.com/question/23792247/answer/600773044
9.cmake与CMakeList.txt
分开放呗,现在需要3个CMakeList.txt 文件了,每个源文件目录都需要一个,还好,每一个都不是太复杂
顶层的CMakeList.txt 文件
1 2 3 | #顶层的CMakeList.txt 文件<br><br>project(HELLO)add_subdirectory(src)add_subdirectory(libhello) |
src 中的 CMakeList.txt 文件
include_directories(${PROJECT_SOURCE_DIR}/libhello)
set(APP_SRC main.c)
add_executable(hello ${APP_SRC})
target_link_libraries(hello libhello)
libhello 中的 CMakeList.txt 文件
set(LIB_SRC hello.c) add_library(libhello ${LIB_SRC}) set_target_properties(libhello PROPERTIES OUTPUT_NAME "hello")
恩,和前面一样,建立一个build目录,在其内运行cmake,然后可以得到
build/src/hello.exe
build/libhello/hello.lib
回头看看,这次多了点什么,顶层的 CMakeList.txt 文件中使用 add_subdirectory 告诉cmake去子目录寻找新的CMakeList.txt 子文件
在 src 的 CMakeList.txt 文件中,新增加了include_directories,用来指明头文件所在的路径。
2)如果想让可执行文件在 bin 目录,库文件在 lib 目录怎么办?
一种办法:修改顶级的 CMakeList.txt 文件
project(HELLO)
add_subdirectory(src bin)
add_subdirectory(libhello lib)
不是build中的目录默认和源代码中结构一样么,我们可以指定其对应的目录在build中的名字。
这样一来:build/src 就成了 build/bin 了,可是除了 hello.exe,中间产物也进来了。还不是我们最想要的。
另一种方法:不修改顶级的文件,修改其他两个文件

src/CMakeList.txt 文件 include_directories(${PROJECT_SOURCE_DIR}/libhello) #link_directories(${PROJECT_BINARY_DIR}/lib) set(APP_SRC main.c) set(EXECUTABLE_OUTPUT_PATH ${PROJECT_BINARY_DIR}/bin) add_executable(hello ${APP_SRC})target_link_libraries(hello libhello) libhello/CMakeList.txt 文件 set(LIB_SRC hello.c) add_library(libhello ${LIB_SRC}) set(LIBRARY_OUTPUT_PATH ${PROJECT_BINARY_DIR}/lib) set_target_properties(libhello PROPERTIES OUTPUT_NAME "hello")
如果不考虑windows下,这个例子应该是很简单的,只需要在上个例子的 libhello/CMakeList.txt 文件中的
add_library命令中加入一个SHARED参数:
add_library(libhello SHARED ${LIB_SRC})
一下午才搞了这点东西,至于多个平台的兼顾,以后有时间再讨论。
这几个例子进行演练熟悉,相信可以解决多大数的项目需要。
在后面我也进行了kcp开源项目进行编译成静态库,并链接生成可执行文件:
目录结构如下:

kcp文件放着源码,生成静态库libkcp
kcp里面的CMakeLists.txt

外面主目录下的CMakeLists.txt
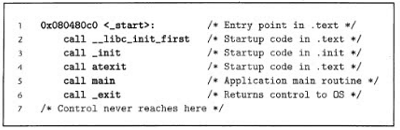
12.ELF文件加载运行原理
linux的ELF的代码段总是从0x08048000
跳转到_start, _init和atexit初始化
然后调用main,执行C代码
程序返回后,调用_exit将控制返回操作系统
运行时,从地地址到高地址,分别是只读区(.text, .init, .rodata),读写段(.data,.bss),堆,共享库的存储映射,用户栈
函数调用栈:
地址从高到低:
寄存器保存区(ebp,ebx)
传入参数
局部变量
传出参数
LR
SP
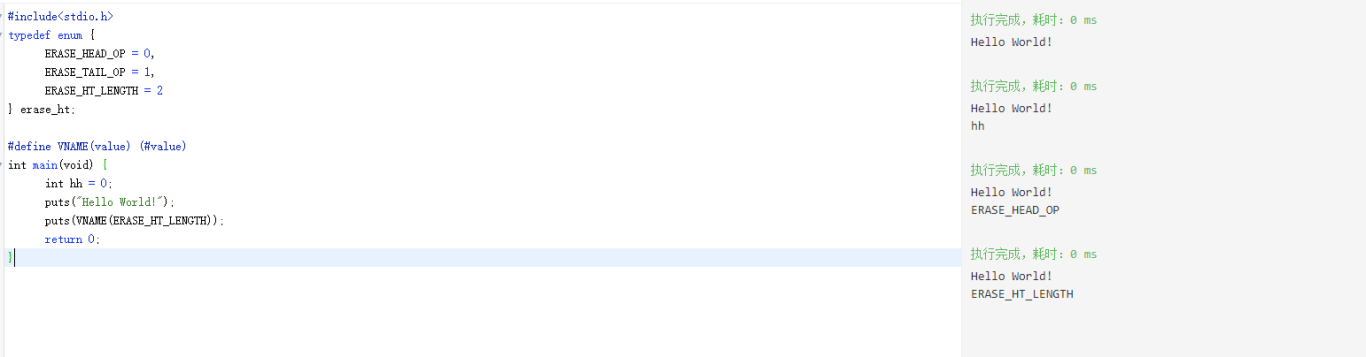
13.打印变量和枚举变量名字
#define VNAME(value) (#value)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现