


排序
“排序”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数 sort_buffer_size。sort_buffer_size,就是 MySQL 为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
通过查看 OPTIMIZER_TRACE 的结果来确认的,你可以从 number_of_tmp_files 中看到是否使用了临时文件。
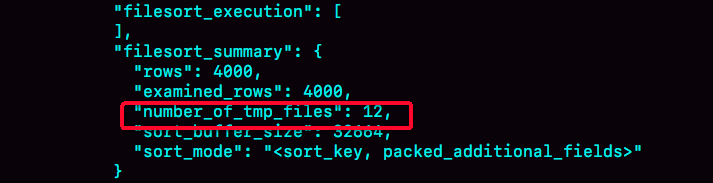
number_of_tmp_files 表示的是,排序过程中使用的临时文件数。你一定奇怪,为什么需要 12 个文件?内存放不下时,就需要使用外部排序,外部排序一般使用归并排序算法。可以这么简单理解,MySQL 将需要排序的数据分成 12 份,每一份单独排序后存在这些临时文件中。然后把这 12 个有序文件再合并成一个有序的大文件。如果 sort_buffer_size 超过了需要排序的数据量的大小,number_of_tmp_files 就是 0,表示排序可以直接在内存中完成。否则就需要放在临时文件中排序。sort_buffer_size 越小,需要分成的份数越多,number_of_tmp_files 的值就越大。
当ORDER BY的条件与联合索引排序规则保持一致时,直接查询即可,无需排序,因为数据在插入时就已经按索引顺序拍好了。
什么情况下ORDER BY 索引排序会失效呢?
以联合索引index(name,age)为例,无法利用索引排序的情况:
order by age,name(字段顺序不一致),因为索引是按照name,age排序的,没有按age,name排序的规则,所以需要重新排序。
order by name desc,age asc(字段排序方式不同步,desc和asc混着来) ,维护索引的排序规则未name ASC,age ASC来排序的,如果你使用一个不一致的排序方式,与索引排序方式不匹配时,需要重新排序。
即使索引的排序方式是顺序排序的,但当查询时都为倒序时也能使用索引的排序,为什么?
因为倒序为顺序的取反,所以只需得到顺序的结果,取反即可。
存在where条件时
但如index(a,b,c) where a = 1 order by b,c也是可以利用索引排序的 为什么? where是返回结果前的过滤,当where过滤完后得到的结果其实是按照了3个字段排序后的结果,此时order by 在进行排序时,就是已经拍好序的结果了。
但当where中使用了范围查询,order by将不能使用索引排序。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构