


索引的访问类型
创建表:

CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
const
- 主键等值查询
SELECT * FROM single_table WHERE id = 1438;
- 唯一二级索引等值查询(is null条件查询为ref)
SELECT * FROM single_table WHERE key2 = 3841;
注:查询条件都与常数比较,为多字段索引时需每个列满足条件。
ref
- 普通二级索引等值查询
SELECT * FROM single_table WHERE key1 = 'abc';
- 为多字段索引时需满足条件字段都与常数比较
SELECT * FROM single_table WHERE key_part1 = 'god like';
SELECT * FROM single_table WHERE key_part1 = 'god like' AND key_part2 = 'legendary';
SELECT * FROM single_table WHERE key_part1 = 'god like' AND key_part2 = 'legendary' AND key_part3 = 'penta kill';
- 无效情况
SELECT * FROM single_table WHERE key_part1 = 'god like' AND key_part2 > 'legendary';
- 二级索引is null条件查询
SELECT * FROM single_table WHERE key2 is null;
注:查询条件都与常数比较。
ref_or_null
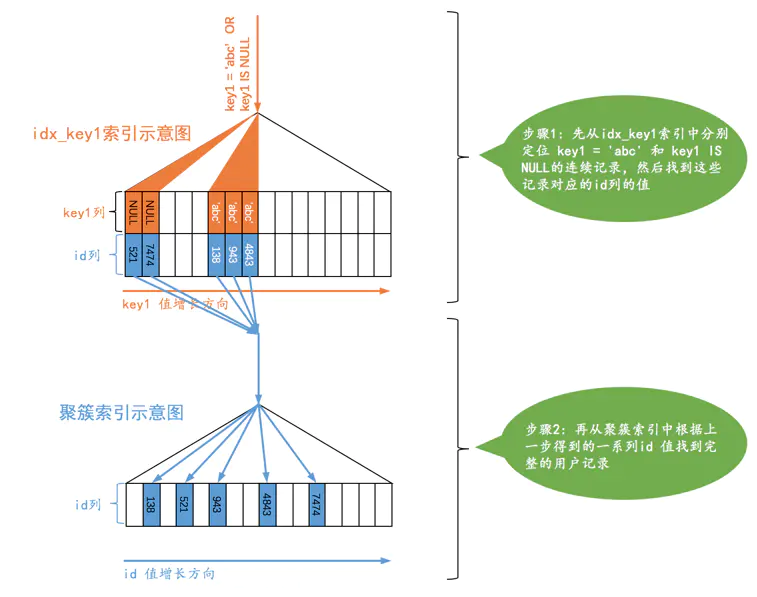
- 二级索引等值查询或者key is null条件
SELECT * FROM single_table WHERE key1 = 'abc' OR key1 IS NULL;
注:值为NULL的记录放在索引最左边。
range
- 索引列需要匹配某个或某些范围的值
SELECT * FROM single_table WHERE key2 IN (1438, 6328) OR (key2 >= 38 AND key2 <= 79);
注:此处所说的使用索引进行范围匹配中的 `索引` 可以是聚簇索引,也可以是二级索引。
index
看下边这个查询:
SELECT key_part1, key_part2, key_part3 FROM single_table WHERE key_part2 = 'abc';
由于key_part2并不是联合索引idx_key_part最左索引列,所以我们无法使用ref或者range访问方法来执行这个语句。但是这个查询符合下边这两个条件:
- 它的查询列表只有3个列:key_part1, key_part2, key_part3,而索引idx_key_part又包含这三个列。
- 搜索条件中只有key_part2列。这个列也包含在索引idx_key_part中。
也就是说我们可以直接通过遍历idx_key_part索引的叶子节点的记录来比较key_part2 = 'abc'这个条件是否成立,把匹配成功的二级索引记录的key_part1, key_part2, key_part3列的值直接加到结果集中就行了。由于二级索引记录比聚簇索记录小的多(聚簇索引记录要存储所有用户定义的列以及所谓的隐藏列,而二级索引记录只需要存放索引列和主键),而且这个过程也不用进行回表操作,所以直接遍历二级索引比直接遍历聚簇索引的成本要小很多,设计MySQL的大叔就把这种采用遍历二级索引记录的执行方式称之为:index。
all
最直接的查询执行方式就是我们已经提了无数遍的全表扫描,对于InnoDB表来说也就是直接扫描聚簇索引,设计MySQL的大叔把这种使用全表扫描执行查询的方式称之为:all。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通