


内存模型
JMM(Java Memory Model,Java 内存模型)
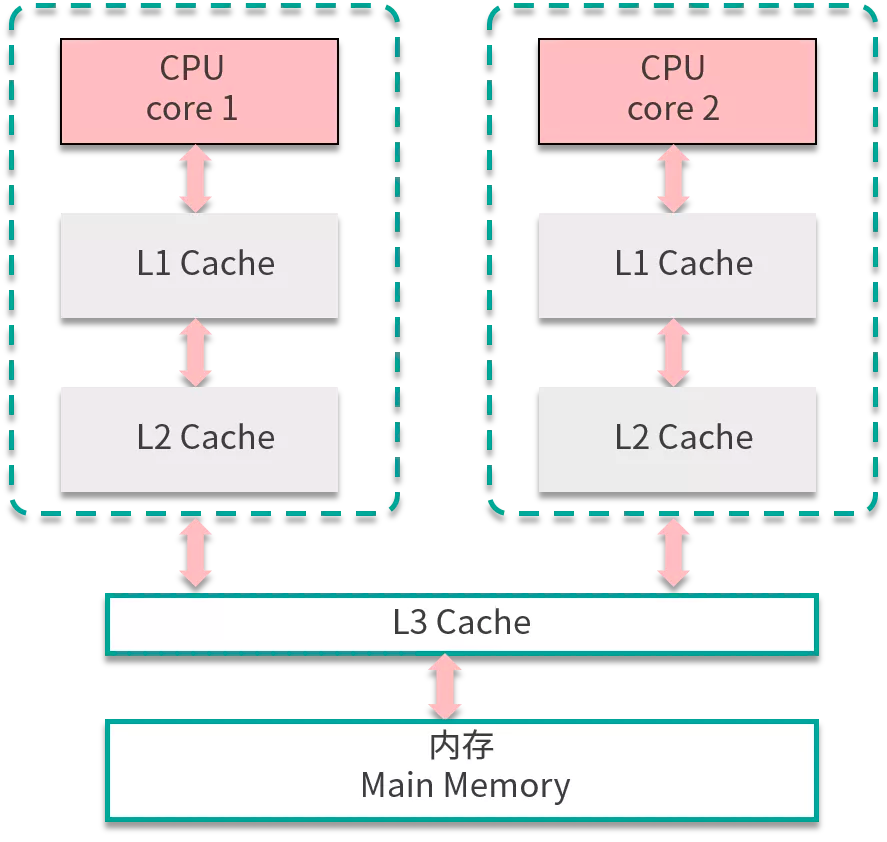
JMM 是一个抽象概念,由于 CPU 多核多级缓存、为了优化代码会发生指令重排的原因,JMM 为了屏蔽细节,定义了一套规范,保证最终的并发安全。它抽象出了工作内存与主内存的概念,并且通过八个原子操作以及内存屏障保证了原子性、内存可见性、防止指令重排,使得 volatile 能保证内存可见性并防止指令重排、synchronised 保证了内存可见性、原子性、防止指令重排导致的线程安全问题,JMM 是并发编程的基础。
JMM 最重要的三点内容:重排序、原子性、内存可见性。
指令重排序
编译器、JVM、甚至 CPU 都有可能出于优化性能的目的,并不能保证各个语句执行的先后顺序与输入的代码顺序一致,而是调整了顺序,这就是指令重排序。
Load、Store都是八种原子操作中之一。

经过重排序之后,情况如下图所示:

重排序后,对 a 操作的指令发生了改变,节省了一次 Load a 和一次 Store a,减少了指令执行,提升了速度改变了运行,这就是重排序带来的好处。
重排序
编译器优化
CPU 重排序
内存“重排序”
不是真正意义的重排序,由于内存有缓存的存在,在 JMM 里表现为主存和本地内存,而主存和本地内存的内容可能不一致,所以这也会导致程序表现出乱序的行为。
每个线程只能够直接接触到工作内存,无法直接操作主内存,而工作内存中所保存的数据正是主内存的共享变量的副本,主内存和工作内存之间的通信是由 JMM 控制的。
内存可见性

public class Visibility { int x = 0; public void write() { x = 1; } public void read() { int y = x; } }
内存可见性问题:当 x 的值已经被第一个线程修改了,但是其他线程却看不到被修改后的值。
假设两个线程执行的上面的代码,第 1 个线程执行的是 write 方法,第 2 个线程执行的是 read 方法。下面我们来分析一下,代码在实际运行过程中的情景是怎么样的,如下图所示:

它们都可以从主内存中去获取到这个信息,对两个线程来说 x 都是 0。可是此时我们假设第 1 个线程先去执行 write 方法,它就把 x 的值从 0 改为了 1,但是它改动的动作并不是直接发生在主内存中的,而是会发生在第 1 个线程的工作内存中,如下图所示。

如果线程 1 的工作内存还未同步给主内存,此时假设线程 2 开始读取,那么它读到的 x 值不是 1,而是 0,也就是说虽然此时线程 1 已经把 x 的值改动了,但是对于第 2 个线程而言,根本感知不到 x 的这个变化,这就产生了可见性问题。
volatile、synchronized、final、和锁都能保证可见性。要注意的是 volatile,每当变量的值改变的时候,都会立马刷新到主内存中,所以其他线程想要读取这个数据,则需要从主内存中刷新到工作内存上。
而锁和同步关键字就比较好理解一些,它是把更多个操作强制转化为原子化的过程。由于只有一把锁,变量的可见性就更容易保证。
原子性
我们大致可以认为基本数据类型变量、引用类型变量、声明为 volatile 的任何类型变量的访问读写是具备原子性的(long 和 double 的非原子性协定:对于 64 位的数据,如 long 和 double,Java 内存模型规范允许虚拟机将没有被 volatile 修饰的 64 位数据的读写操作划分为两次 32 位的操作来进行,即允许虚拟机实现选择可以不保证 64 位数据类型的 load、store、read 和 write 这四个操作的原子性,即如果有多个线程共享一个并未声明为 volatile 的 long 或 double 类型的变量,并且同时对它们进行读取和修改操作,那么某些线程可能会读取到一个既非原值,也不是其他线程修改值的代表了“半个变量”的数值。但由于目前各种平台下的商用虚拟机几乎都选择把 64 位数据的读写操作作为原子操作来对待,因此在编写代码时一般也不需要将用到的 long 和 double 变量专门声明为 volatile)。这些类型变量的读、写天然具有原子性,但类似于 “基本变量++” / “volatile++” 这种复合操作并没有原子性。比如 i++;
Java 内存模型如何解决?
JMM 抽象出主存储器(Main Memory)和工作存储器(Working Memory)两种。
- 主存储器是实例位置所在的区域,所有的实例都存在于主存储器内。比如,实例所拥有的字段即位于主存储器内,主存储器是所有的线程所共享的。
- 工作存储器是线程所拥有的作业区,每个线程都有其专用的工作存储器。工作存储器存有主存储器中必要部分的拷贝,称之为工作拷贝(Working Copy)。
线程是无法直接对主内存进行操作的,如下图所示,线程 A 想要和线程 B 通信,只能通过主存进行交换。
经历下面 2 个步骤:
1)线程 A 把本地内存 A 中更新过的共享变量刷新到主内存中去。
2)线程 B 到主内存中去读取线程 A 之前已更新过的共享变量。
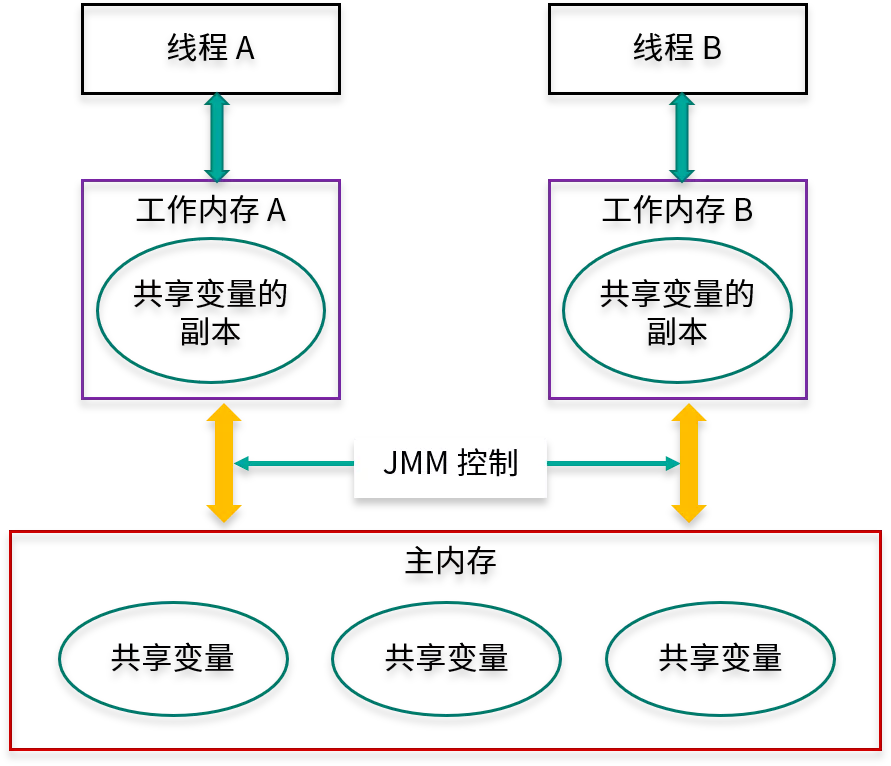
从抽象角度看,JMM 定义了线程与主内存之间的抽象关系:
- 线程之间的共享变量存储在主内存(Main Memory)中;
- 每个线程都有一个私有的本地内存(Local Memory),本地内存是 JMM 的一个抽象概念,并不真实存在,它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。本地内存中存储了该线程以读/写共享变量的拷贝副本。
- 从更低的层次来说,主内存就是硬件的内存,而为了获取更好的运行速度,虚拟机及硬件系统可能会让工作内存优先存储于寄存器和高速缓存中。
- Java 内存模型中的线程的工作内存(working memory)是 cpu 的寄存器和高速缓存的抽象描述。而 JVM 的静态内存储模型(JVM 内存模型)只是一种对内存的物理划分而已,它只局限在内存,而且只局限在 JVM 的内存。
原子性保障
八种原子操作中,JMM 保证了 read、load、assign、use、store 和 write 六个操作具有原子性,可以认为除了 long 和 double 类型以外,对其他基本数据类型所对应的内存单元的访问读写都是原子的。
但是当你想要更大范围的的原子性保证就需要使用 ,就可以使用 lock 和 unlock 这两个操作。
内存屏障:内存可见性与指令重排序
JMM 如何防止指令重排序排序,内存可见性带来并发访问问题?
内存屏障(Memory Barrier)用于控制在特定条件下的重排序和内存可见性问题。JMM 内存屏障可分为读屏障和写屏障,Java 的内存屏障实际上也是上述两种的组合,完成一系列的屏障和数据同步功能。Java 编译器在生成字节码时,会在执行指令序列的适当位置插入内存屏障来限制处理器的重排序。
组合如下:
- Load-Load Barriers:load1 的加载优先于 load2 以及所有后续的加载指令,在指令前插入 Load Barrier,使得高速缓存中的数据失效,强制重新从驻内存中加载数据。
- Load-Store Barriers:确保 load1 数据的加载先于 store2 以及之后的存储指令刷新到内存。
- Store-Store Barriers:确保 store1 数据对其他处理器可见,并且先于 store2 以及所有后续的存储指令。在 Store Barrie 指令后插入 Store Barrie 会把写入缓存的最新数据刷新到主内存,使得其他线程可见。
- Store-Load Barriers:在 Load2 及后续所有读取操作执行前,保证 Store1 的写入对所有处理器可见。这条内存屏障指令是一个全能型的屏障,它同时具有其他 3 条屏障的效果,而且它的开销也是四种屏障中最大的一个。
分类:
Java / JMM
, Java


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构