


change buffer
change buffer 是 buffer pool 里的一块区域。
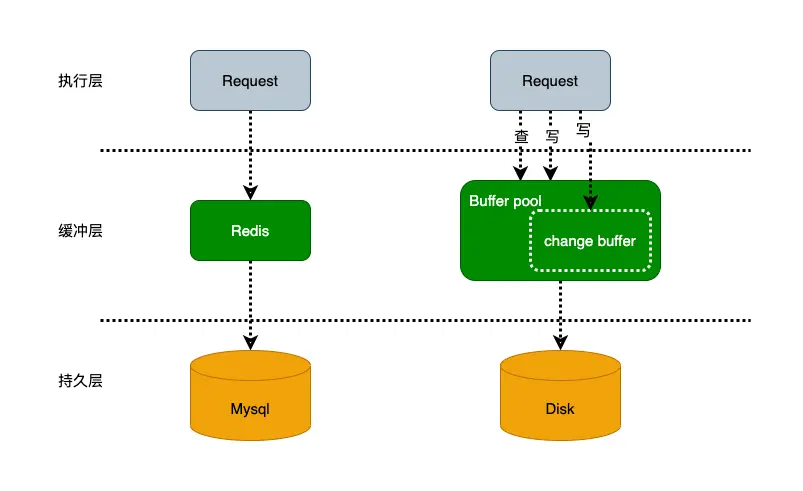
change buffer 不缓存聚簇索引的更新,二级索引的page假如符合使用 change buffer 更新条件的话,就不去读磁盘,直接使用 change buffer 的 page,change buffer 的 page 是连续分配的。写入完成后,假如用户的一次查询用到了这个二级索引的 Page,就把二级索引的数据页读上来和 change buffer 的 Page 做一个 merge 操作, 再返回给用户。
change buffer
当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,InnoDB 会将这些更新操作缓存在 change buffer 中,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行 change buffer 中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。 change buffer在内存中有拷贝,也会被写入磁盘。 将 change buffer 中的操作应用到原数据页,得到最新结果的过程称为 merge。除了访问这个数据页会触发 merge 外,系统有后台线程会定期 merge。在数据库正常关闭(shutdown)的过程中,也会执行 merge 操作。 可以看出来,如果能将更新操作先记录在change buffer,可以减少读磁盘,语句执行速度会得到明显提升。而且数据读入内存是需要占用 buffer pool 的,所以这种方式还能够避免占用内存,提高内存利用率。
meger时机:
- 用户线程选择二级索引进行数据查询,这时候必须要读入二级索引页,相应的ibuf entry需要merge到page中。之后该page会被刷新到磁盘。
- 当系统空闲或者slow shutdown时,后台master线程发起merge。
- change buffer 页面没有空间了。change buffer默认占有buffer pool内存的25%,最大为50%。
客户端怎么拿到修改行数呢?
change buffer对于不在内存中的聚簇索引页,innodb 都会去读磁盘,然后内存修改聚簇索引页中的元数据,其实这个时候就已经拿到了 affected rows 。然后才是轮到二级索引页的更新,change buffer 是针对二级索引页更新的优化。
唯一索引不能使用change buffer
对于唯一索引来说,所有的更新操作都要先判断这个操作是否违反唯一性约束。比如,要插入 (4,400) 这个记录,就要先判断现在表中是否已经存在 k=4 的记录,而这必须要将数据页读入内存才能判断。如果都已经读入到内存了,那直接更新内存会更快,就没必要使用 change buffer 了。 tips:change buffer 用的是 buffer pool 里的内存,因此不能无限增大。change buffer 的大小,可以通过参数 innodb_change_buffer_max_size 来动态设置。这个参数设置为 50 的时候,表示 change buffer 的大小最多只能占用 buffer pool 的 50%。
普通索引和唯一索引区别
- 如果要更新的目标页已经在内存中了,那么就直接更新操作;
- 如果要更新的目标页不在内存中:
-
- 对于唯一索引,因为要校验是否违反唯一性约束,所以需要先将数据页读到内存中,再执行更新操作;
- 对于普通索引,我们就能使用change buffer记录更新数据。
将数据从磁盘读入内存涉及随机IO的访问,是数据库里面成本最高的操作之一。change buffer 因为减少了随机磁盘访问,所以对更新性能的提升是会很明显的。所以可以看出来,对于更新操作,普通索引对比唯一索引有更大的优势,因为可以用到change buffer。
change buffer使用场景
使用 change buffer 对更新过程的加速作用, change buffer 只限于用在普通索引的场景下,而不适用于唯一索引。 但是change buffer会比较适合写多,读少的场景。因为如果写完后都是马上要读,那么会频繁的执行merge操作,这样随机访问的IO次数并不会减少,反而还要多维护一个change buffer。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY