


数据结构-ziplist压缩列表
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。
压缩列表结构
struct ziplist<T> {
int32 zlbytes;
int32 zltail_offset;
int16 zllength;
T[] entries;
int8 zlend;
}
- zlbytes:整个压缩列表占用的字节数,占4Byte。
- zltail_offset:最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个元素,占4Byte。
- zllength:压缩列表的元素个数,占2Byte。
- entries:压缩列表的元素,可以包含多个节点,每个节点可以保存一个字节数组或者一个整数值。
- zlend:压缩列表结束标志,值等于 0xFF,占1Byte。
压缩列表节点结构
typedef struct zlentry { unsigned int prevrawlensize, prevrawlen; unsigned int lensize, len; unsigned int headersize; unsigned char encoding; unsigned char *p; } zlentry;
- prevrawlen:前一个节点的长度
- prevrawlensize:存储前一个节点长度(prevrawlen属性)所需的字节数
- len:当前节点长度
- lensize:储当前节点长度(len属性)所需的字节数
- headersize:当前节点的header大小
- encoding:节点的编码方式
- p:指向节点的指针
虽然redis定义了节点zlentry结构体,但是redis却没有用zlentry结构来存储节点,因为,这个结构存小整数或短字符串太浪费空间。
zlentry结构体在32位系统占用28Byte,在64位系统占用32Byte,这不符合压缩列表提高内存利用率的设计目的,因此,在redis中,并没有使用zlentry结构,而是定义了宏来表示压缩列表的节点。
压缩列表的节点真正的结构如下图所示:
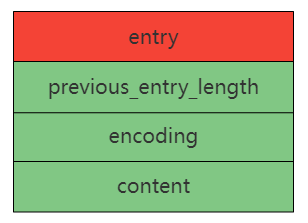
- previous_entry_length:前一个节点的长度,占1Byte或5Byte。
- 如果前一个节点的长度小于254Byte,则需要1Byte来保存前一个节点的长度。
- 如果前一个节点的长度大于等于254Byte,则需要5Byte来保存前一个节点的长度,第一个Byte固定为0xfe(254),后四个Byte表示前一个节点的长度。
- encoding:编码类型(字节数组,整数),保存了content的数据类型和长度,占用1Byte、2Byte或者5Byte。
- content:节点数据,节点数据类型和长度由encoding决定。
压缩列表查找

在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。
它的好处是更能节省内存空间,因为它所存储的内容都是在连续的内存区域当中的。当列表对象元素不大,每个元素也不大的时候,就采用ziplist存储。但当数据量过大时就ziplist就不是那么好用了。因为为了保证他存储内容在内存中的连续性,插入的复杂度是O(N),即每次插入都会进行realloc重新分配内存。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构