


HashMap
流程
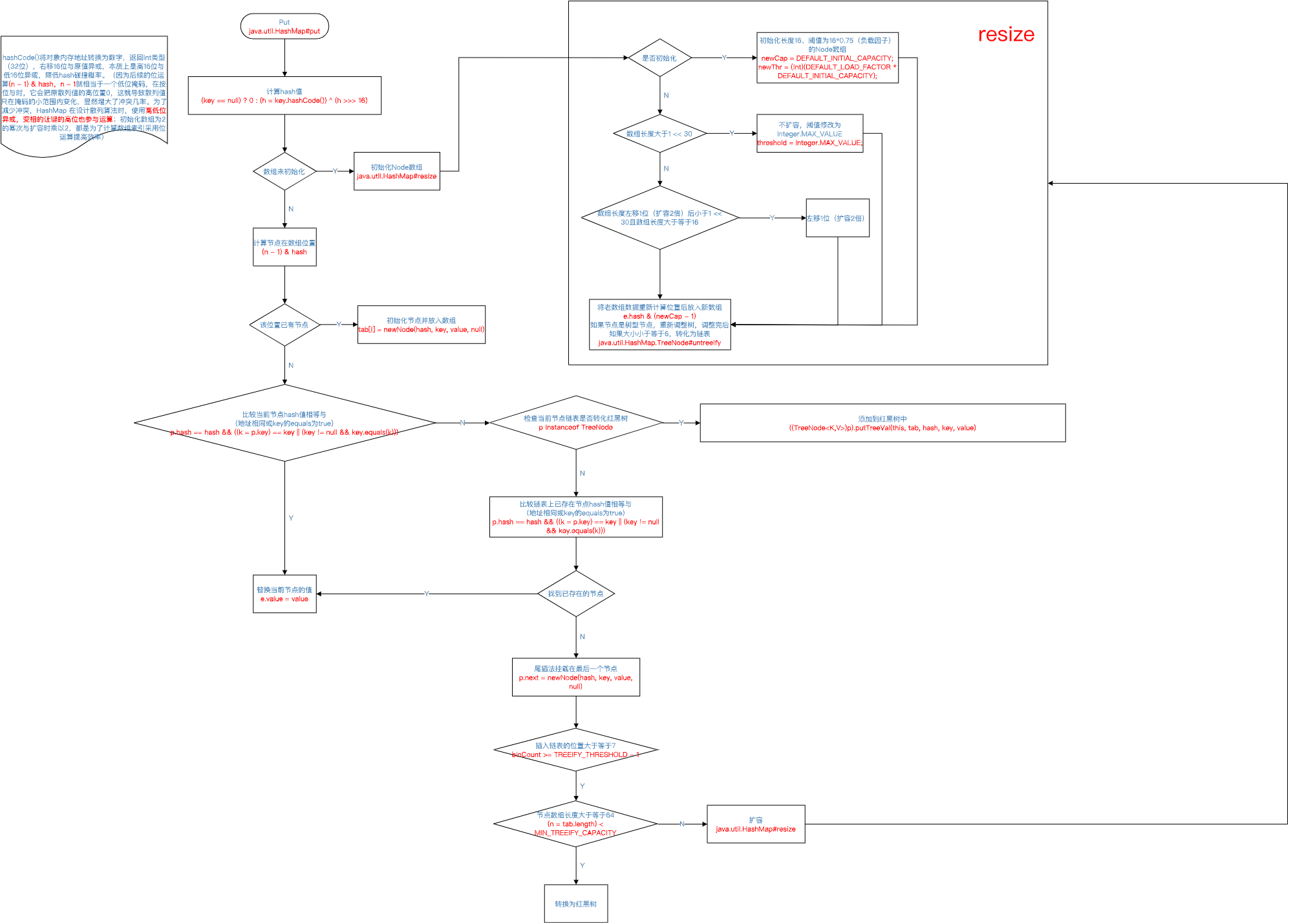
resize
初始化大小16,负载因子0.75。
当桶节点个数大于扩容阈值,会进行扩容,容量扩大到2倍。

//离100最近的2次幂是128,默认负载因子是0.75,所以扩容阈值是128*0.75=96,以下put发生rehash HashMap hashMap = new HashMap(100); for (int i = 0; i < 100; i++) { hashMap.put(i, i); } //离10000最近的2次幂是16384,默认负载因子是0.75,所以扩容阈值是16384*0.75=12288,以下put不发生rehash hashMap = new HashMap(10000); for (int i = 0; i < 10000; i++) { hashMap.put(i, i); }
get、put操作时间复杂度
在JDK8之前
用单链表HashMap作为一个桶来储存存在哈希碰撞的元素。无论是get还是put方法,步骤都可以分为第一步找桶(找桶时间都为O(1),可以忽略),第二步在桶内进行操作(查找或者插入),首先最好的情况为没有任何哈希碰撞的情况,即所有元素分配在不同的桶,最坏的情况为所有元素碰撞在一起,即全部被分配在同一个桶。所以情况复杂度如下:
- GET最好情况:O(1)
- GET最坏情况:O(N) (即单链表查询的时间复杂度)
- 平均:O(1)
- PUT最好情况:O(1)
- PUT最坏情况:O(1) (JDK8前才用头插法,即在单链表头部直接插入,不需要遍历)
- 平均:O(1)
在JDK8之后
当桶内元素元素大于8个,桶内的储存结构会由单链表转化为红黑树。时间复杂度如下
- GET最好情况:O(1)
- GET最坏情况:当桶内元素不大于6个:O(N)(即单链表查询的时间复杂度),当桶内元素大于8个:O(logN)(红黑树查询的时间复杂度为O(logN)与二分查找类似)
- 平均:O(1)
- PUT最好情况:O(1)
- PUT最坏情况:当桶内元素不大于6个:O(N)(JDK8才用尾插法,遍历到尾部再插入),当桶内元素大于8个:O(logN)(红黑树插入的时间复杂度为O(logN)与二分插入类似)
- 平均:O(1)
解释
平均复杂O(1),因为哈希碰撞频率实际上不是十分多,即使存在,也比较少出现极端情况。 空间复杂度:O(N)。N为map元素的个数。因为几乎每多一个元素就多一个空间储存,多一个桶或者在桶内多一个位置。
自定义对象作为HashMap的key需要注意什么?
在路由哪个桶时,需要计算key的hash值,需要调用key的hashcode方法;在比较桶内元素是否相等时,需要比较key的内存地址是否相等或者调用key的equals方法;所以需要重写key对象的hashcode、equals方法。
//计算hash值 (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16) //对比key是否相等 p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))
线程不安全
put的时候导致的多线程数据不一致
比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的 hash桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的 hash桶索引和线程B要插入的记录计算出来的 hash桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
resize而引起死循环(JDK1.8已经不会出现该问题)
这种情况发生在JDK1.7 中HashMap自动扩容时,当2个线程同时检测到元素个数超过 数组大小 × 负载因子。此时2个线程会在put()方法中调用了resize(),使用了头插法,两个线程同时修改一个链表结构会产生一个循环链表(JDK1.7中,会出现resize前后元素顺序倒置的情况,具体原因可以参考这篇文章)。接下来再想通过get()获取某一个元素,就会出现死循环。所以在1.8的HashMap就进行了改进,使用了尾插法,保证顺序的情况下同时不会造成死循环。毕竟是在多线程情况下,虽然不会造成死循环,但是会造成语义不正确的情况。
JDK1.8的优化
-
头插法改为尾插法。
-
高16位与低16位进行异或运算,降低hash碰撞。
为什么要链表和红黑树的转换?
链表查询时间复杂度O(N) ,红黑树查询时间复杂度O(logN)。
链表和红黑树的转换是基于时间和空间的权衡,链表只有指向下一个节点的指针和数据值,而红黑树需要左右指针来分别指向左节点和右节点,TreeNodes 占用空间是普通 Nodes 的两倍,因此红黑树相较于链表需要更多的存储空间,但是红黑树的查找效率要优于链表。
当然这些优势都是基于数据量的前提下的,只有当容器中的节点数量足够多的时候才会转红黑树。数据量小的时候两者查询效率不会相差很多,但是红黑树需要的存储容量更多,因此需要设置一个转换的阈值分别是8和6。注意前提条件是桶个数要大于等于64,否则优先进行resize。
为什么进化红黑树的阈值是8?
这个HashMap的设计者在源码的注释中给予说明了,其实很多的疑惑都可以从源码的阅读中得到答案。
 当理想情况下,即哈希值离散性很好、哈希碰撞率很低的时候,数据是均匀分布在容器的各链表中,不会出现数据比较集中的情况,这时候红黑树是没必要的。但是现实中每个对象的哈希算法随机性高,因此就可能导致不均匀的数据分布。
当理想情况下,即哈希值离散性很好、哈希碰撞率很低的时候,数据是均匀分布在容器的各链表中,不会出现数据比较集中的情况,这时候红黑树是没必要的。但是现实中每个对象的哈希算法随机性高,因此就可能导致不均匀的数据分布。
/* Because TreeNodes are about twice the size of regular nodes, we * use them only when bins contain enough nodes to warrant use * (see TREEIFY_THRESHOLD). And when they become too small (due to * removal or resizing) they are converted back to plain bins. In * usages with well-distributed user hashCodes, tree bins are * rarely used. Ideally, under random hashCodes, the frequency of * nodes in bins follows a Poisson distribution * (http://en.wikipedia.org/wiki/Poisson_distribution) with a * parameter of about 0.5 on average for the default resizing * threshold of 0.75, although with a large variance because of * resizing granularity. Ignoring variance, the expected * occurrences of list size k are (exp(-0.5) * pow(0.5, k) / * factorial(k)). The first values are: * * 0: 0.60653066 * 1: 0.30326533 * 2: 0.07581633 * 3: 0.01263606 * 4: 0.00157952 * 5: 0.00015795 * 6: 0.00001316 * 7: 0.00000094 * 8: 0.00000006 * more: less than 1 in ten million */
之所以选择8是从概率的角度提出的,理想情况下,在随机哈希码算法下容器中的节点遵循泊松分布,在Map中一个链表长度达到8的概率微乎其微,可以看到8的时候概率是0.00000006,如果这种低概率的事都发生了说明链表的长度确实比较长了。至于为什么不选择同一个值作为阈值是为了缓冲,可以有效防止链表和红黑树的频繁转换。
为什么退化为链表的阈值是6?
主要是一个过渡,避免链表和红黑树之间频繁的转换。如果阈值是7的话,删除一个元素红黑树就必须退化为链表,增加一个元素就必须树化,来回不断的转换结构无疑会降低性能,所以阈值才不设置的那么临界。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构