
Kaggle图像分割比赛:keras平台训练unet++模型识别盐沉积区(二)
一、加载模型
from keras.models import load_model model = load_model(r"E:\Kaggle\salt\competition_data/model\Kaggle_Salt_02-0.924.hdf5")
二、识别图片
从验证集随机选择图片,识别显示:
max_images = 10 grid_width = 10 grid_height = int(max_images / grid_width) + 2 show_ids = np.random.randint(0,len(valid_ids),size=max_images)
fig, axs = plt.subplots(grid_height, grid_width, figsize=(20, 4)) for i, idx in enumerate(valid_ids[show_ids]): img = train_df.loc[idx].images mask = train_df.loc[idx].masks ax = axs[int(i / grid_width), i % grid_width] ax.imshow(img, cmap="Greys") ax = axs[int(i / grid_width)+1, i % grid_width] ax.imshow(mask, cmap="Greens") ax = axs[int(i / grid_width)+2, i % grid_width] ax.imshow(preds_valid[i], cmap="Greens") ax.set_yticklabels([]) ax.set_xticklabels([]) plt.show()
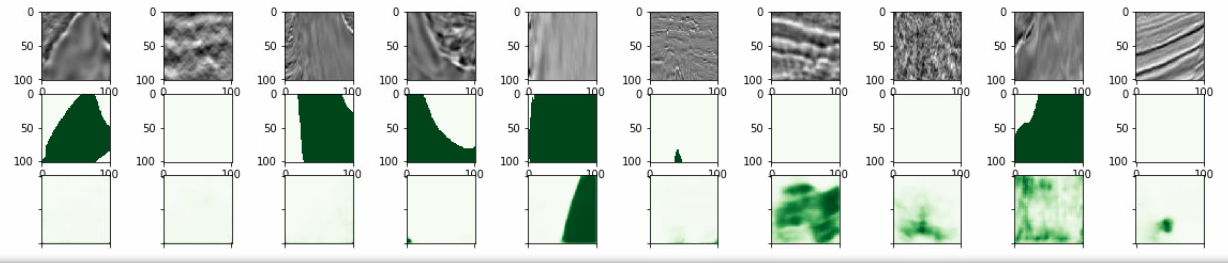
结果识别的好像不太好。
三、根据验证集找最佳阈值
# src: https://www.kaggle.com/aglotero/another-iou-metric def iou_metric(y_true_in, y_pred_in, print_table=False): labels = y_true_in y_pred = y_pred_in true_objects = 2 pred_objects = 2 intersection = np.histogram2d(labels.flatten(), y_pred.flatten(), bins=(true_objects, pred_objects))[0] # Compute areas (needed for finding the union between all objects) area_true = np.histogram(labels, bins = true_objects)[0] area_pred = np.histogram(y_pred, bins = pred_objects)[0] area_true = np.expand_dims(area_true, -1) area_pred = np.expand_dims(area_pred, 0) # Compute union union = area_true + area_pred - intersection # Exclude background from the analysis intersection = intersection[1:,1:] union = union[1:,1:] union[union == 0] = 1e-9 # Compute the intersection over union iou = intersection / union # Precision helper function def precision_at(threshold, iou): matches = iou > threshold true_positives = np.sum(matches, axis=1) == 1 # Correct objects false_positives = np.sum(matches, axis=0) == 0 # Missed objects false_negatives = np.sum(matches, axis=1) == 0 # Extra objects tp, fp, fn = np.sum(true_positives), np.sum(false_positives), np.sum(false_negatives) return tp, fp, fn # Loop over IoU thresholds prec = [] if print_table: print("Thresh\tTP\tFP\tFN\tPrec.") for t in np.arange(0.5, 1.0, 0.05): tp, fp, fn = precision_at(t, iou) if (tp + fp + fn) > 0: p = tp / (tp + fp + fn) else: p = 0 if print_table: print("{:1.3f}\t{}\t{}\t{}\t{:1.3f}".format(t, tp, fp, fn, p)) prec.append(p) if print_table: print("AP\t-\t-\t-\t{:1.3f}".format(np.mean(prec))) return np.mean(prec) def iou_metric_batch(y_true_in, y_pred_in): batch_size = y_true_in.shape[0] metric = [] for batch in range(batch_size): value = iou_metric(y_true_in[batch], y_pred_in[batch]) metric.append(value) return np.mean(metric)
识别验证集:
preds_valid = model.predict(valid_x).reshape(-1, train_img_w, train_img_h) preds_valid = np.array([train2orig(x) for x in preds_valid]) valid_y_ori = np.array([train_df.loc[idx].masks for idx in valid_ids]) thresholds = np.linspace(0, 1, 50) ious = np.array([iou_metric_batch(valid_y_ori, np.int32(preds_valid > threshold)) for threshold in thresholds])
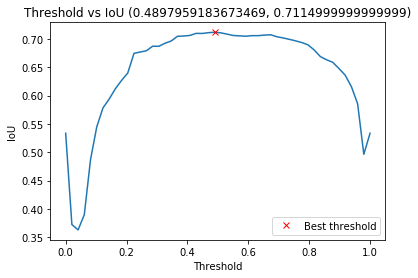
根据iou和阈值的对应关系得到最佳阈值:
threshold_best_index = np.argmax(ious) iou_best = ious[threshold_best_index] threshold_best = thresholds[threshold_best_index]
plt.plot(thresholds, ious) plt.plot(threshold_best, iou_best, "xr", label="Best threshold") plt.xlabel("Threshold") plt.ylabel("IoU") plt.title("Threshold vs IoU ({}, {})".format(threshold_best, iou_best)) plt.legend() plt.show()
四、生成结果文件
得到测试集id:
depths_df = pd.read_csv(depths_csv, index_col="id") train_df = train_df.join(depths_df) test_df = depths_df[~depths_df.index.isin(train_df.index)]
# Source https://www.kaggle.com/bguberfain/unet-with-depth def RLenc(img, order='F', format=True): """ img is binary mask image, shape (r,c) order is down-then-right, i.e. Fortran format determines if the order needs to be preformatted (according to submission rules) or not returns run length as an array or string (if format is True) """ bytes = img.reshape(img.shape[0] * img.shape[1], order=order) runs = [] ## list of run lengths r = 0 ## the current run length pos = 1 ## count starts from 1 per WK for c in bytes: if (c == 0): if r != 0: runs.append((pos, r)) pos += r r = 0 pos += 1 else: r += 1 # if last run is unsaved (i.e. data ends with 1) if r != 0: runs.append((pos, r)) pos += r r = 0 if format: z = '' for rr in runs: z += '{} {} '.format(rr[0], rr[1]) return z[:-1] else: return runs
读取测试集图片:
x_test = np.array([orig2tain(np.array(load_img("{}/images/{}.png".format(test_imgs_path, idx), grayscale=False))) / 255 for idx in test_df.index]).reshape(-1, train_img_w, train_img_h, 3)
识别:
preds_test = model.predict(x_test)
根据最佳阈值得到结果文件:
threshold_best = round(threshold_best, 5) pred_dict = {idx: RLenc(np.round(train2orig(preds_test[i]) > threshold_best)) for i, idx in enumerate(test_df.index.values)} sub = pd.DataFrame.from_dict(pred_dict,orient='index') sub.index.names = ['id'] sub.columns = ['rle_mask'] sub.to_csv(root + r'\submission.csv')
五、结果提交到Kaggle
需先注册,才能参加比赛,提交结果。提交后Public Score:0.68594、Private Score:0.72593,和第一名0.89646还有不小距离,排名2500/3229,很一般。


