Keras猫狗大战一:小样本4层卷积网络,74%精度
版权声明:本文为博主原创文章,欢迎转载,并请注明出处。联系方式:460356155@qq.com
一、下载数据集
百度搜索“kaggle 猫狗数据集”,可找到网盘共享的猫狗数据集,有815M。
二、准备数据集
整个数据集有25000张图,猫狗各12500,从中选取1000、500、200分别作为训练、验证、测试集。
import os import random import shutil # 随机得到样本子集 def get_sub_sample(sample_path, target_path, train, valid, test, file_name_format=None, class_name=None, class_num=None): """ sample_path: 样本全集目录 target_path: 样本子集目录 train, valid, test: 随机选取训练、验证、测试样本数 file_name_format:文件名格式过滤 class_name:样本类型名 class_num: 样本数 """ # 得到样本全集目录下的所有文件,不遍历子目录 all_files = [f for f in os.listdir(sample_path) if os.path.isfile(os.path.join(sample_path, f))] total = len(all_files) if file_name_format: # 针对一个目录放多种类型情况 num_per_class = int(total / class_num) fnames = [file_name_format.format(i) for i in range(num_per_class)] else: fnames = all_files # 打乱顺序 random.shuffle(fnames) os.makedirs(os.path.join(target_path, 'train', class_name)) os.makedirs(os.path.join(target_path, 'valid', class_name)) os.makedirs(os.path.join(target_path, 'test', class_name)) for i in range(train): src = os.path.join(sample_path, fnames[i]) dst = os.path.join(target_path, 'train', class_name, fnames[i]) shutil.copyfile(src, dst) for i in range(train, train + valid): src = os.path.join(sample_path, fnames[i]) dst = os.path.join(target_path, 'valid', class_name, fnames[i]) shutil.copyfile(src, dst) for i in range(train + valid, train + valid + test): src = os.path.join(sample_path, fnames[i]) dst = os.path.join(target_path, 'test', class_name, fnames[i]) shutil.copyfile(src, dst) src_path = r'D:\BaiduNetdiskDownload\train' dst_path = r'D:\BaiduNetdiskDownload\small' train_dir = os.path.join(dst_path, 'train') validation_dir = os.path.join(dst_path, 'valid') class_name = ['cat', 'dog'] if os.path.exists(dst_path): shutil.rmtree(dst_path) os.makedirs(dst_path) for cls in class_name: get_sub_sample(src_path, dst_path, 1000, 500, 200, file_name_format='%s.{}.jpg' % (cls), class_name=cls, class_num=2)
三、模型建立
from keras import layers from keras import models model = models.Sequential() # 输出图片尺寸:150-3+1=148*148,参数数量:32*3*3*3+32=896 model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3))) model.add(layers.MaxPooling2D((2, 2))) # 输出图片尺寸:148/2=74*74 # 输出图片尺寸:74-3+1=72*72,参数数量:64*3*3*32+64=18496 model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) # 输出图片尺寸:72/2=36*36 # 输出图片尺寸:36-3+1=34*34,参数数量:128*3*3*64+128=73856 model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) # 输出图片尺寸:34/2=17*17 # 输出图片尺寸:17-3+1=15*15,参数数量:128*3*3*128+128=147584 model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) # 输出图片尺寸:15/2=7*7 # 多维转为一维:7*7*128=6272 model.add(layers.Flatten()) # 参数数量:6272*512+512=3211776 model.add(layers.Dense(512, activation='relu')) # 参数数量:512*1+1=513 model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
四、模型compile
from keras import optimizers # 二分类用binary_crossentropy model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
五、建立训练和验证数据
from keras.preprocessing.image import ImageDataGenerator # 归一化 train_datagen = ImageDataGenerator(rescale=1. / 255) test_datagen = ImageDataGenerator(rescale=1. / 255) train_generator = train_datagen.flow_from_directory( train_dir, # 输入训练图像尺寸 target_size=(150, 150), batch_size=20, # 二分类 class_mode='binary') validation_generator = test_datagen.flow_from_directory( validation_dir, target_size=(150, 150), batch_size=20, class_mode='binary')
六、训练
history = model.fit_generator( train_generator, # 2000张图 / 20 batch size steps_per_epoch=100, epochs=30, validation_data=validation_generator, # 1000张图 / 20 batch size validation_steps=50)
WARNING:tensorflow:From d:\program files\python37\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version. Instructions for updating: Use tf.cast instead. Epoch 1/30 100/100 [==============================] - 41s 409ms/step - loss: 0.6903 - acc: 0.5255 - val_loss: 0.6730 - val_acc: 0.6070 Epoch 2/30 100/100 [==============================] - 41s 406ms/step - loss: 0.6599 - acc: 0.6070 - val_loss: 0.6350 - val_acc: 0.6510 Epoch 3/30 100/100 [==============================] - 41s 408ms/step - loss: 0.6135 - acc: 0.6710 - val_loss: 0.6223 - val_acc: 0.6400 Epoch 4/30 100/100 [==============================] - 41s 410ms/step - loss: 0.5816 - acc: 0.6960 - val_loss: 0.5798 - val_acc: 0.6950 Epoch 5/30 100/100 [==============================] - 41s 411ms/step - loss: 0.5582 - acc: 0.7160 - val_loss: 0.5757 - val_acc: 0.6970 Epoch 6/30 100/100 [==============================] - 42s 420ms/step - loss: 0.5278 - acc: 0.7360 - val_loss: 0.5788 - val_acc: 0.6790 Epoch 7/30 100/100 [==============================] - 41s 412ms/step - loss: 0.5096 - acc: 0.7485 - val_loss: 0.5551 - val_acc: 0.7140 Epoch 8/30 100/100 [==============================] - 42s 418ms/step - loss: 0.4809 - acc: 0.7715 - val_loss: 0.5871 - val_acc: 0.6870 Epoch 9/30 100/100 [==============================] - 42s 416ms/step - loss: 0.4645 - acc: 0.7850 - val_loss: 0.5309 - val_acc: 0.7370 Epoch 10/30 100/100 [==============================] - 42s 415ms/step - loss: 0.4348 - acc: 0.7960 - val_loss: 0.5618 - val_acc: 0.7160 Epoch 11/30 100/100 [==============================] - 42s 420ms/step - loss: 0.4133 - acc: 0.8050 - val_loss: 0.5714 - val_acc: 0.7210 Epoch 12/30 100/100 [==============================] - 41s 409ms/step - loss: 0.3847 - acc: 0.8215 - val_loss: 0.5937 - val_acc: 0.7030 Epoch 13/30 100/100 [==============================] - 41s 413ms/step - loss: 0.3523 - acc: 0.8465 - val_loss: 0.6225 - val_acc: 0.7030 Epoch 14/30 100/100 [==============================] - 42s 416ms/step - loss: 0.3339 - acc: 0.8535 - val_loss: 0.5339 - val_acc: 0.7500 Epoch 15/30 100/100 [==============================] - 43s 428ms/step - loss: 0.3013 - acc: 0.8650 - val_loss: 0.5404 - val_acc: 0.7520 Epoch 16/30 100/100 [==============================] - 42s 417ms/step - loss: 0.2736 - acc: 0.8885 - val_loss: 0.5885 - val_acc: 0.7380 Epoch 17/30 100/100 [==============================] - 41s 415ms/step - loss: 0.2562 - acc: 0.8995 - val_loss: 0.5636 - val_acc: 0.7420 Epoch 18/30 100/100 [==============================] - 41s 415ms/step - loss: 0.2294 - acc: 0.9115 - val_loss: 0.5722 - val_acc: 0.7490 Epoch 19/30 100/100 [==============================] - 42s 415ms/step - loss: 0.2004 - acc: 0.9210 - val_loss: 0.6201 - val_acc: 0.7390 Epoch 20/30 100/100 [==============================] - 41s 413ms/step - loss: 0.1812 - acc: 0.9315 - val_loss: 0.6323 - val_acc: 0.7390 Epoch 21/30 100/100 [==============================] - 42s 423ms/step - loss: 0.1551 - acc: 0.9495 - val_loss: 0.5949 - val_acc: 0.7530 Epoch 22/30 100/100 [==============================] - 50s 500ms/step - loss: 0.1438 - acc: 0.9505 - val_loss: 0.6145 - val_acc: 0.7500 Epoch 23/30 100/100 [==============================] - 45s 447ms/step - loss: 0.1131 - acc: 0.9660 - val_loss: 0.7587 - val_acc: 0.7340 Epoch 24/30 100/100 [==============================] - 42s 415ms/step - loss: 0.1012 - acc: 0.9650 - val_loss: 0.7000 - val_acc: 0.7500 Epoch 25/30 100/100 [==============================] - 42s 425ms/step - loss: 0.0852 - acc: 0.9765 - val_loss: 0.7501 - val_acc: 0.7400 Epoch 26/30 100/100 [==============================] - 43s 427ms/step - loss: 0.0730 - acc: 0.9785 - val_loss: 0.7945 - val_acc: 0.7500 Epoch 27/30 100/100 [==============================] - 41s 410ms/step - loss: 0.0643 - acc: 0.9825 - val_loss: 0.7769 - val_acc: 0.7480 Epoch 28/30 100/100 [==============================] - 41s 415ms/step - loss: 0.0544 - acc: 0.9860 - val_loss: 0.8410 - val_acc: 0.7530 Epoch 29/30 100/100 [==============================] - 41s 410ms/step - loss: 0.0435 - acc: 0.9910 - val_loss: 0.8678 - val_acc: 0.7670 Epoch 30/30 100/100 [==============================] - 41s 411ms/step - loss: 0.0370 - acc: 0.9920 - val_loss: 0.8941 - val_acc: 0.7640
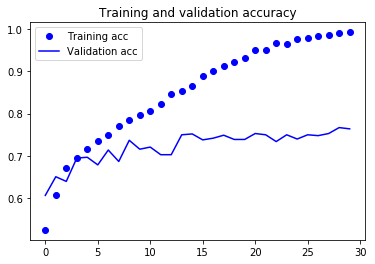
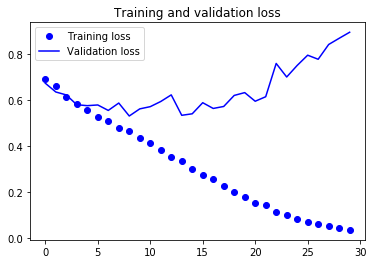
在第9次迭代时,验证损失达到最小,验证精度在74%左右,随着迭代次数增加,出现了过拟合。显示训练曲线:
% matplotlib inline import matplotlib.pyplot as plt acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(len(acc)) plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.legend() plt.figure() plt.plot(epochs, loss, 'bo', label='Training loss') plt.plot(epochs, val_loss, 'b', label='Validation loss') plt.title('Training and validation loss') plt.legend() plt.show()
七、保存模型
model.save('cats_and_dogs_small_1.h5')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号