
数据采集与融合技术第三次作业
| 学号姓名 | 102202132 郑冰智 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13287 |
| 这个作业的目标 | 熟悉掌握scrapy框架爬取相关网页信息 |
| 实验二仓库地址 | https://gitee.com/zheng-bingzhi/2022-level-data-collection/tree/master/实验三 |
一、作业①:
要求:
- 指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
- 务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
Gitee文件夹链接:https://gitee.com/zheng-bingzhi/2022-level-data-collection/tree/master/实验三/douban/myproject
1.1实验代码及结果:
1.1.1核心代码:
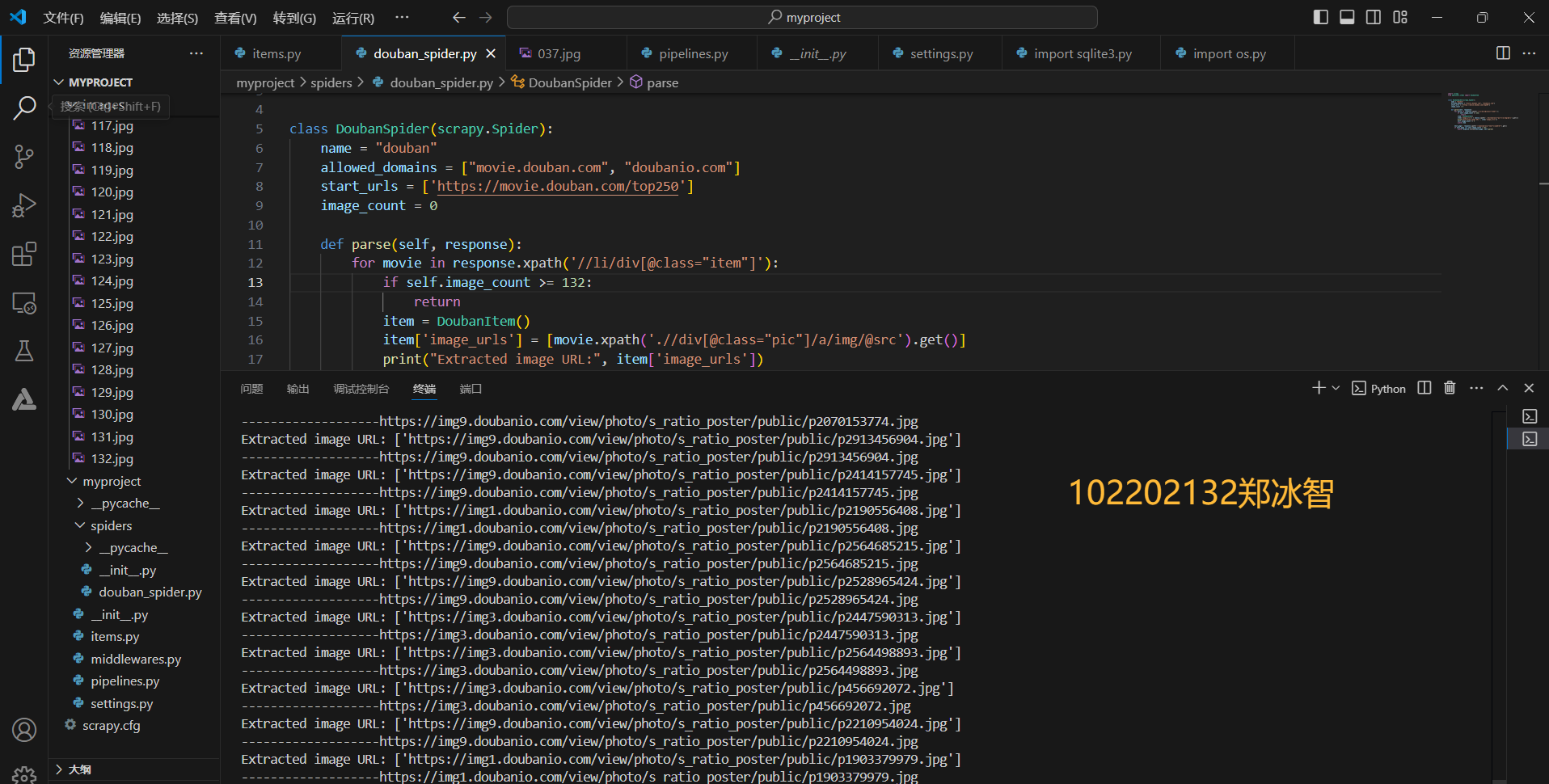
- spider蜘蛛爬虫 解析函数: 使用xpath表达式在response(可能是网页响应内容的某种表示对象)中查找符合//li/div[@class="item"]模式的元素,if self.image_count >= 132限制爬取图片为132张。
#douban_spider.py:
def parse(self, response):
for movie in response.xpath('//li/div[@class="item"]'):
if self.image_count >= 132:
return
item = DoubanItem()
item['image_urls'] = [movie.xpath('.//div[@class="pic"]/a/img/@src').get()]
print("Extracted image URL:", item['image_urls'])
self.image_count += 1
yield item
- pipelines.py:DoubanImagesPipeline类用于处理从豆瓣(或其他类似网站)获取的图片相关的管道类。它继承自ImagesPipeline。
- get_media_requests方法为每个在item中的图片 URL 创建一个下载请求。
- file_path方法确定下载的图片在本地存储的文件名。
class DoubanImagesPipeline(ImagesPipeline):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def get_media_requests(self, item, info):
if 'image_urls' in item:
for image_url in item['image_urls']:
print('-------------------' + image_url)
yield Request(image_url, headers={
'User - Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'cookie': 'bid=zRt_plpndug; _pk_id.100001.4cf6=16ba515416abd13f.1730033312.; __yadk_uid=AtDwldRyCjDyJJLDM9D6eKbGbqQBy2k5; __utmz=30149280.1730110523.2.2.utmcsr=cnblogs.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmz=223695111.1730110523.2.2.utmcsr=cnblogs.com|utmccn=(referral)|utmcmd=referral|utmcct=/; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1730166855%2C%22https%3A%2F%2Fwww.cnblogs.com%2F%22%5D; _pk_ses.100001.4cf6=1; __utma=30149280.1180626636.1730033313.1730110523.1730166855.3; __utmb=30149280.0.10.1730166855; __utmc=30149280; __utma=223695111.21755573.1730033313.1730110523.1730166855.3; __utmb=223695111.0.10.1730166855; __utmc=223695111; ap_v=0,6.0'
})
def file_path(self, request, response = None, info = None, *, item = None):
image_dir = self.store.basedir
existing_files = [f for f in os.listdir(image_dir) if os.path.isfile(os.path.join(image_dir, f))]
number = len(existing_files) + 1
filename = f"{str(number).zfill(3)}.jpg"
return filename
def item_completed(self, results, item, info):
item['image_path'] = [x['path'] for ok, x in results if ok]
return item
1.1.2实验结果:
- 将图片下载至本地中并在终端输出下载下来的图片URL:
本地文件夹(myproject/images):
1.2实验问题与心得:
1.2.1实验问题及解决方法:
- 问题1:
蜘蛛程序成功爬取并解析douban网站的图片URL,却无法成功将图片下载下来 - 解决方法:
-allowed_domains内要补充完整的域名信息,图片的域名信息与网页不同导致无法下载图片
-seeting.py文件中要修改ROBOTSTXT_OBEY = False.
1.2.2实验心得:
- 在技术方法方面,DoubanImagesPipeline类的运用继承自ImagesPipeline,通过重写get_media_requests方法,巧妙地为每个图片 URL 创建了带有特定请求头的下载请求。这种设置User - Agent和cookie的方式,有助于模拟真实浏览器行为,提高爬虫获取图片资源的成功率,规避可能的反爬虫限制。
- 在DoubanSpider类中,parse方法利用XPath表达式准确地从网页中提取电影图片的 URL。XPath的熟练运用使得能够精准定位到所需元素,高效地获取数据。同时,通过循环和条件判断,实现了对多个电影项目的图片 URL 提取,并在满足数量限制或页面遍历条件时进行相应的操作,如停止或继续爬取下一页。这种结合XPath和循环逻辑的方式,为大规模数据提取提供了一种有效的模式。
二、作业②
要求:
- 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
- 候选网站:东方财富网:https://www.eastmoney.com/
输出信息:MySQL数据库存储和输出格式如下:
- 表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
Gitee文件夹链接:
- https://gitee.com/zheng-bingzhi/2022-level-data-collection/tree/master/实验三/quotes_spider
- https://gitee.com/zheng-bingzhi/2022-level-data-collection/tree/master/实验三/stock_scraper
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额(万元) | 成交量(亿股) | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N 世华 | 28.47 | 10.92% | 26.13 | 7.6 | 22.34 | 32.0 | 28.08 | 30.20 | 17.55 |
2.1实验代码及结果
2.1.1核心代码:
-QuotesSpider.py:结合了 Scrapy 和 Selenium 的优势,能够处理动态加载的页面,并且使用self.driver.find_elements(By.XPATH, '//tr[@class="odd" or @class="even"]')找到页面中所有的表格行(奇数行和偶数行),这些行包含了股票数据。
def __init__(self, *args, **kwargs):
super(QuotesSpider, self).__init__(*args, **kwargs)
# 设置 Selenium WebDriver
chrome_options = Options()
# chrome_options.add_argument("--headless") # 无界面模式
chrome_options.add_argument("--disable-gpu")
self.driver = webdriver.Chrome(options=chrome_options)
def parse(self, response):
# 使用 Selenium 加载页面
self.driver.get(response.url)
time.sleep(3) # 等待页面加载(可调整时间或改为显性等待)
# 提取数据
rows = self.driver.find_elements(By.XPATH, '//tr[@class="odd" or @class="even"]')
for row in rows:
# 获取所有的td元素
tds = row.find_elements(By.TAG_NAME, "td")
# 检查是否有至少14个td元素
if len(tds) >= 14:
# 列表推导式,跳过第4个td元素(索引为3)
data = [td.text for i, td in enumerate(tds) if i != 3][:14]
- pipelines.py:增加写入MYSQL数据库的方法:
def open_spider(self, spider):
self.connection = mysql.connector.connect(
host=spider.settings.get('MYSQL_HOST'),
database=spider.settings.get('MYSQL_DBNAME'),
user=spider.settings.get('MYSQL_USER'),
password=spider.settings.get('MYSQL_PASSWORD')
)
self.cursor = self.connection.cursor()
# 创建表的SQL语句
create_table_sql = """
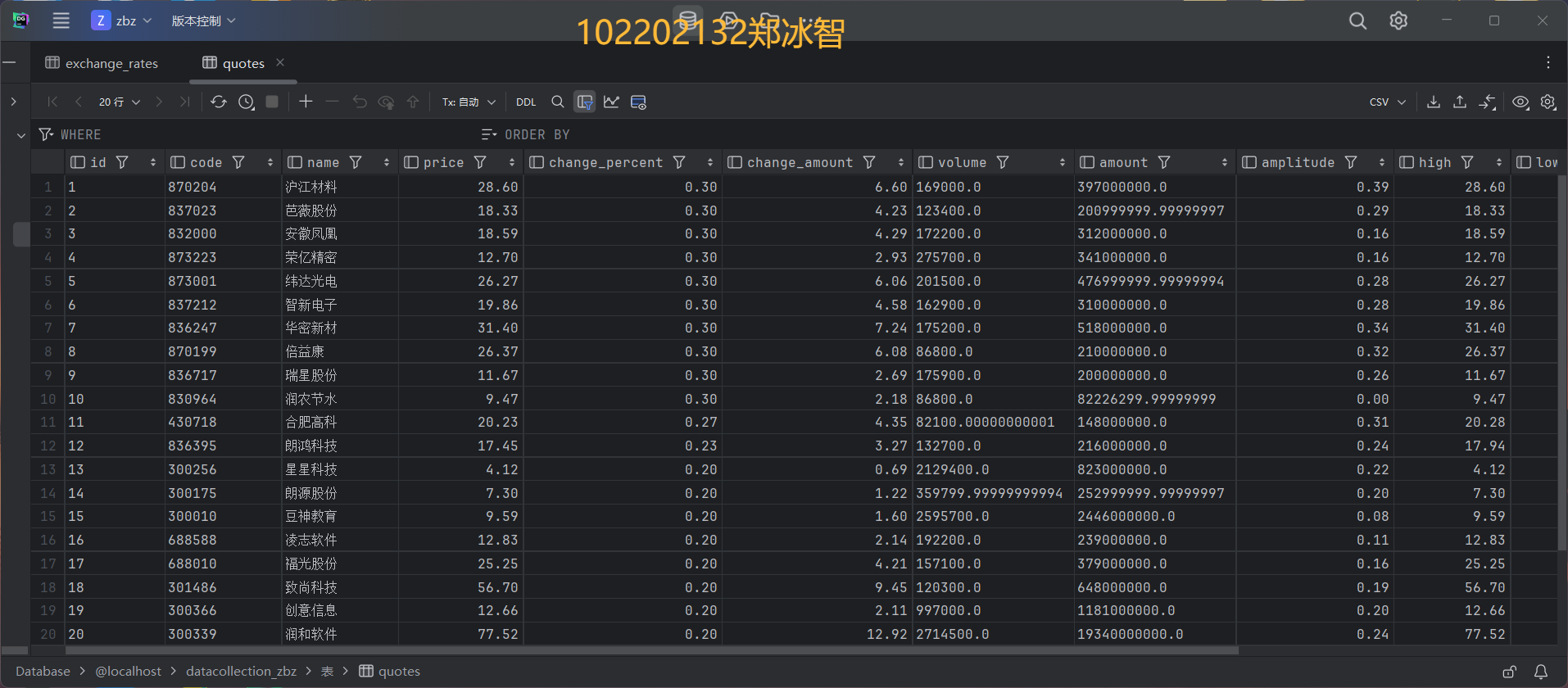
2.1.2实验结果:
- 成功将爬取的数据写入数据库:
2.2实验问题及结果:
2.2.1实验问题及解决方法:
- 问题1:
无法直接静态爬取出股票的数据,只能爬取相关的静态信息和框架 - 解决方法:
-通过抓包的方法,使用API接口爬取相关信息(将文件一块放入仓库中了)
-通过selenium技术模拟用户访问,抓取动态页面的信息 - 问题2:
无法将数据成功导入MYSQL - 解决方法:
确保建表时每个数据的属性值与插入数据的属性值一致(注意%,万,亿等单位)
2.2.2实验心得:
- 通过使用 Selenium 方法结合 Scrapy 框架进行网页数据抓取:Selenium 在处理动态页面加载方面表现出色。利用find_elements方法和 XPath 定位页面元素,能够准确地获取到股票数据所在的表格行及具体单元格数据。这种基于浏览器自动化的方式,有效地解决了传统爬虫无法获取动态生成内容的问题,大大扩展了数据抓取的能力范围。
- 在将数据导入数据库方面,首先需要设计合理的数据库结构来存储抓取到的股票数据,如创建相应的表和字段来对应QuoteItem中的各个属性。然后,使用数据库操作库(如 SQLAlchemy 等)将QuoteItem实例中的数据批量插入或更新到数据库中。这一过程需要注意数据类型的匹配和事务处理,以确保数据的完整性和一致性。同时,要考虑数据库的性能优化,如建立合适的索引等,以便快速查询和检索数据。
- 通过这样的实践,我不仅提升了数据抓取技能,还对数据存储和管理有了更深入的理解,为后续的数据分析和应用奠定了基础。
三、作业③:
要求:
- 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
- 候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:
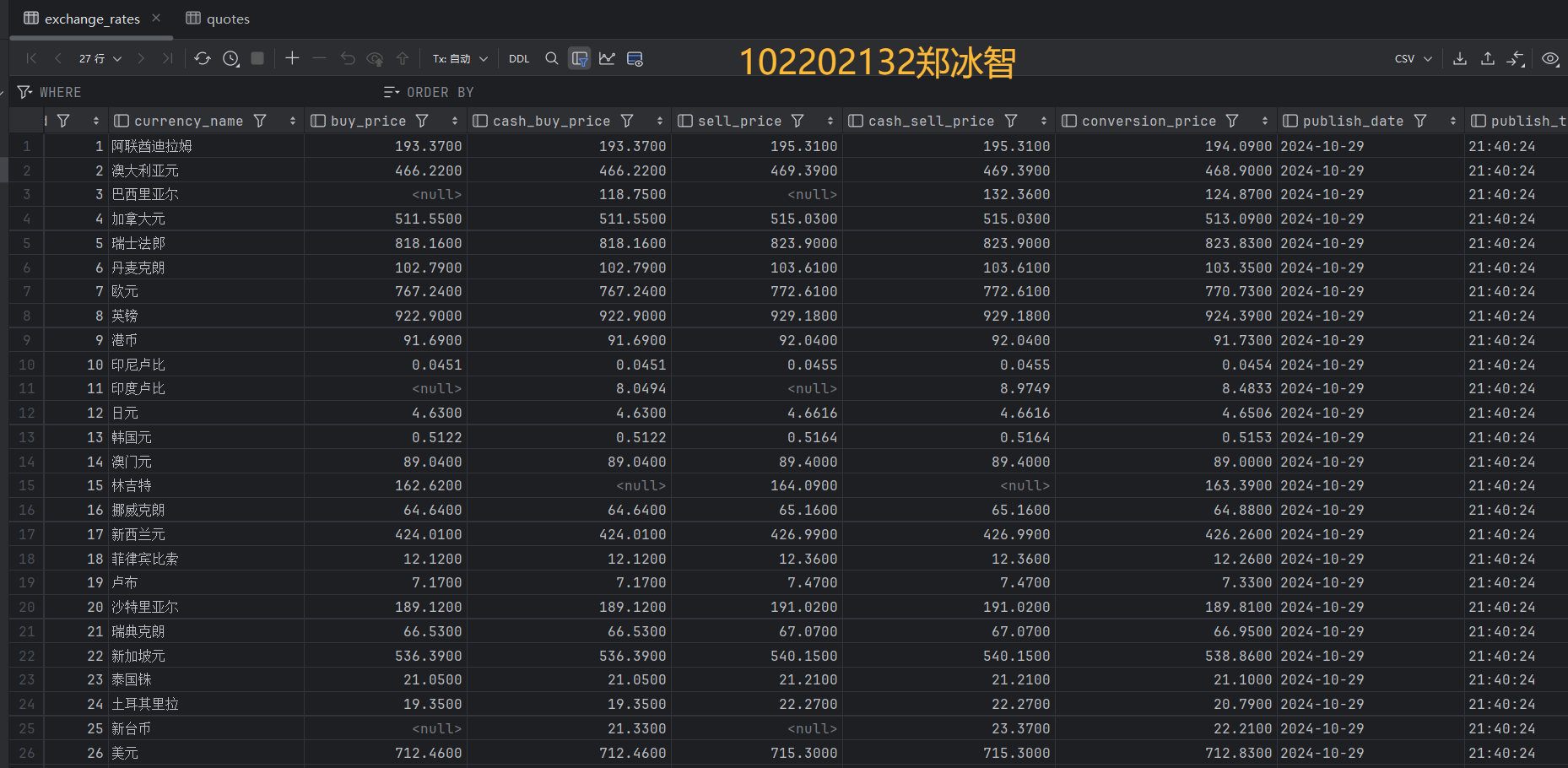
| Currency | TBP | CBP | TSP | CSP | Time |
|---|---|---|---|---|---|
| 阿联酋迪拉姆 | 198.58 | 192.31 | 199.98 | 206.59 | 11:27:14 |
3.1实验代码及结果
3.1.1核心代码:
- boc_spider.py:使用xpath的方法爬取相关网页内容:
class BocSpider(scrapy.Spider):
name = "boc"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
rows = response.xpath('//table//tr[position()>1]')
for row in rows:
item = ForeignExchangeItem()
item['currency_name'] = row.xpath('./td[1]/text()').get()
item['buy_price'] = row.xpath('./td[2]/text()').get()
item['cash_buy_price'] = row.xpath('./td[3]/text()').get()
item['sell_price'] = row.xpath('./td[4]/text()').get()
item['cash_sell_price'] = row.xpath('./td[5]/text()').get()
item['conversion_price'] = row.xpath('./td[6]/text()').get()
item['publish_date'] = row.xpath('./td[7]/text()').get()
item['publish_time'] = row.xpath('./td[8]/text()').get()
yield item
- MYSQL创建表与写入内容:
class MySQLPipeline:
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS exchange_rates ( #...
)
''')
self.connection.commit()
except Error as e:
print(f"Error connecting to MySQL: {e}")
def close_spider(self, spider):
if self.cursor:
self.cursor.close()
if self.connection and self.connection.is_connected():
self.connection.close()
def process_item(self, item, spider):
if self.cursor is None:
print("Cursor not initialized; skipping item.")
return item # 如果 cursor 没有初始化,跳过该项
try:
self.cursor.execute('''
INSERT INTO exchange_rates (currency_name, buy_price, cash_buy_price,
sell_price, cash_sell_price, conversion_price, publish_date, publish_time)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
''', (
item['currency_name'] #...
))
self.connection.commit()
except Error as e:
print(f"Error inserting item: {e}")
return item
3.1.2实验结果:
3.2实验问题及心得:
3.2.1实验问题
- 问题1:输出部分为空
- 解决方法: 使用selenium等动态爬取,仍然为空(尚未解决)
3.2.2实验心得:
- 在本次实验中,我深入学习了Scrapy框架中的Item和Pipeline组件,并掌握了它们在数据序列化和输出方面的关键作用。
- 通过编写boc_spider.py,我学会了如何使用Scrapy框架结合XPath技术爬取外汇网站数据。在解析过程中,我能够提取出货币名称、买卖价格等关键信息,并将其封装到自定义的ForeignExchangeItem中。
- 此外,我还实现了一个MySQLPipeline,用于将爬取的数据存储到MySQL数据库中,这不仅加深了我对数据库操作的理解,也提高了数据处理的效率。
- 整个过程中,我体会到了Scrapy框架的强大和灵活性,以及在数据采集和存储方面的优势。通过这次实践,我对Scrapy框架有了更深入的认识,并为将来处理更复杂的数据采集任务打下了坚实的基础。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)