
数据采集与融合技术第一次作业
| 学号姓名 | 102202132 郑冰智 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13286 |
| 这个作业的目标 | 用requests和BeautifulSoup库方法定向爬取各网页内容 |
| 实验一仓库地址 | https://gitee.com/zheng-bingzhi/2022-level-data-collection/tree/master/实验一 |
1.作业①
要求:用requests和BeautifulSoup库方法定向爬取给定网址( http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
输出信息:
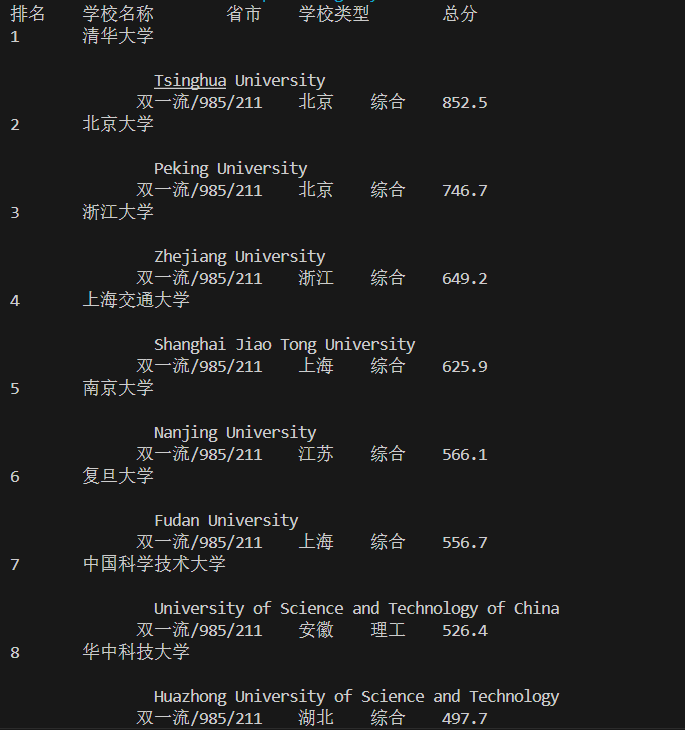
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
1.1核心代码:
1.1.1 获取网页内容与解析
通过 requests.get(url) 获取目标网页的 HTML 内容,并用 BeautifulSoup 进行解析,提取网页数据结构。
import requests
from bs4 import BeautifulSoup
# 目标URL
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
# 发送请求并获取网页HTML内容
response = requests.get(url)
html = response.text
# 解析HTML内容
soup = BeautifulSoup(html, 'html.parser')
1.1.2. 定位并提取表格
找到包含排名的表格,通过类名 'rk-table' 进行选择,并提取表格中的所有行 (<tr> 标签)。
# 查找表格
table = soup.find("table", {'class': 'rk-table'})
rows = table.find_all('tr')
1.1.3. 提取并清理数据
遍历表格的每一行,从每一列中提取排名、学校名称、所在省市、学校类型及总分,并使用 .text.strip() 方法清理数据格式。
# 输出表头
print("排名\t学校名称\t省市\t学校类型\t总分")
# 遍历表格行并提取数据
for row in rows[1:]:
cols = row.find_all('td')
rank = cols[0].text.strip() # 排名
school_name = cols[1].text.strip() # 学校名称
province = cols[2].text.strip() # 省市
school_type = cols[3].text.strip() # 学校类型
score = cols[4].text.strip() # 总分
print(f"{rank}\t{school_name}\t{province}\t{school_type}\t{score}")
整体功能
- 网页请求: 获取并读取网页内容。
- HTML解析: 使用 BeautifulSoup 定位表格元素,提取表格数据。
- 数据输出: 格式化排名信息,按行输出清理后的数据。
1.2.实现结果:
在终端输出:
1.3.实验心得:
1.3.1. 网页抓取与解析
通过使用requests抓取网页内容,并结合BeautifulSoup解析HTML结构,提升了我对网页数据提取的理解。
1.3.2. 实践与应用
实践了从网页到本地提取并格式化数据的完整流程,进一步巩固了Python网络爬虫技术的应用能力。
2作业②: 淘宝价格定向爬虫
2.1核心代码思路
2.1.1数据爬取
功能
- 从淘宝的相关推荐接口获取商品数据。
实现思路 - 使用
requests库发送HTTP GET请求来获取网页内容,并设置headers模拟浏览器请求头。 - 核心代码:
response = requests.get(url, headers=headers)
2.1.2数据提取与保存
功能
- 从返回内容中提取JSON数据并保存到
taobao_data.txt文件。
实现思路 - 利用正则表达式去掉JSONP的回调包装获取纯JSON数据,再用
with语句写入文件。 - 核心代码:
json_data = re.search(r'mtopjsonp\d+\((.*)\)', response.text).group(1)
with open('taobao_data.txt', 'w', encoding='utf-8') as f:
f.write(json_data)
2.1.3二次提取与打印
功能
- 从
taobao_data.txt文件读取内容,用正则表达式提取商品标题和价格并打印。
实现思路 - 先读取文件内容,再定义两个正则表达式分别匹配标题和价格,通过
re.findall找到匹配项并用zip组合打印。 - 核心代码:
with open('taobao_data.txt', 'r', encoding='utf-8') as f:
content = f.read()
title_pattern = r'"TITLE":"(.*?)"
price_pattern = r'"GOODSPRICE":"(.*?)"
titles = re.findall(title_pattern, content)
prices = re.findall(price_pattern, content)
for title, price in zip(titles, prices):
print(f'TITLE: {title}, GOODSPRICE: {price}')
2.1.4数据导出为CSV
功能
- 将提取的商品标题和价格数据保存为CSV文件。
实现思路 - 用
with语句打开CSV文件创建csv.writer对象,先写入表头再逐行写入数据,最后打印保存成功信息。 - 核心代码:
csv_filename = 'extracted_data.csv'
with open(csv_filename, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['TITLE', 'GOODSPRICE'])
writer.writerows(zip(titles, prices))
print(f'Data saved to {csv_filename}')
2.2.实现结果
2.2.1.终端输出

2.2.2.本地输出(csv)

2.3.心得体会
2.3.1.淘宝过时的Cookie分析
时效性问题
- 淘宝Cookie时效性强,几小时内就可能失效,无法长期依赖,会阻碍后续数据获取。
失效影响 - Cookie失效会使爬虫无法获取正确数据,导致程序中断,可能返回空数据或错误提示页面。
2.3.2.淘宝翻页难以实现
操作复杂性
- 淘宝翻页不直观,目前靠存URL解决,该方式不灵活,页面多易出错且URL规则变化时需重新调整。
数据获取问题 - 存URL可能导致数据获取不完整,效率低,存在重复或不必要请求。
2.3.3.爬取方法的新得
正则表达式运用
- 正则表达式能有效处理淘宝数据,从复杂文本准确提取信息,但编写需技巧,如提取标题和价格的正则表达式。
多步骤处理流程 - 爬取过程采用多步骤处理,可分解复杂任务,便于测试和优化,提高程序可维护性和稳定性。
3.作业③:爬取给定页面图像
3.1核心代码思路
3.1.1请求,处理页面响应
思路
- 发送请求后,检查响应状态码。若为200则请求成功,可继续操作;否则表示请求失败并打印错误信息。
核心代码
if response.status_code == 200:
print(f"Successfully fetched page {page_num}.")
# 后续操作(解析页面、下载图片)
else:
print(f"Failed to retrieve page {page_num}. Status code: {response.status_code}")
3.1.2解析页面并查找图片
思路
- 成功获取页面内容后,使用
BeautifulSoup解析HTML,通过find_all方法查找src属性以.jpg结尾的img标签来定位图片。
核心代码
soup = BeautifulSoup(response.text, "html.parser")
img_tags = soup.find_all("img", src=lambda src: src and src.endswith(".jpg"))
3.1.3下载并保存图片
思路
- 对找到的每个图片标签,获取其URL,若不完整则用
urljoin转换为完整路径,再用requests.get获取图片二进制数据并保存到本地,文件名依页面编号和图片顺序确定。
核心代码
for idx, img_tag in enumerate(img_tags):
img_url = img_tag["src"]
full_url = urljoin("https://news.fzu.edu.cn/", img_url)
img_data = requests.get(full_url).content
img_filename = os.path.join(download_folder, f"page{page_num}_image{idx + 1}.jpg")
with open(img_filename, "wb") as img_file:
img_file.write(img_data)
print(f"Downloaded {img_filename} from {full_url}")
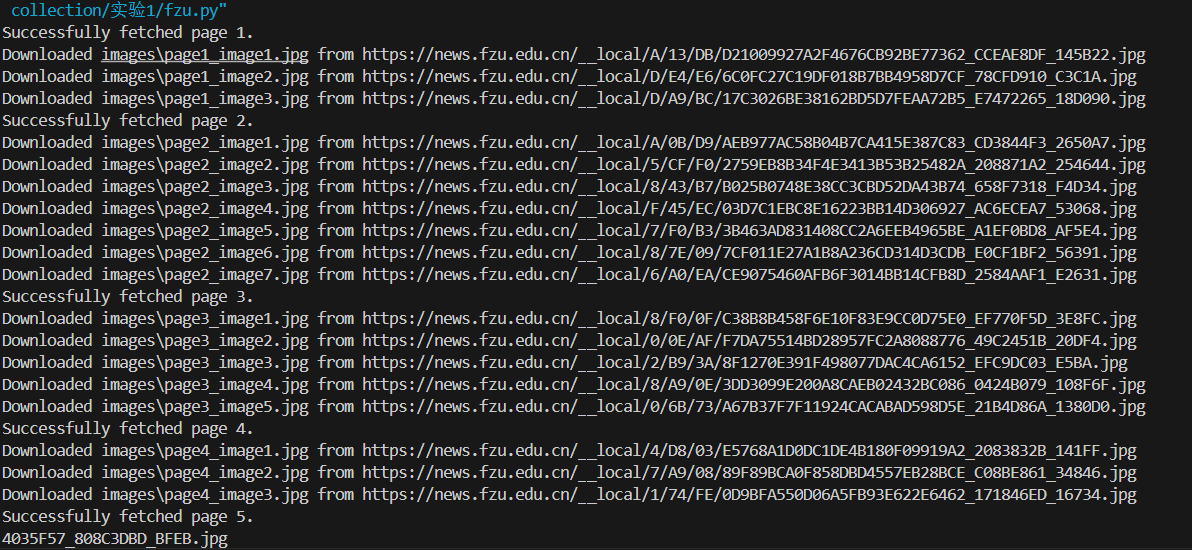
3.2实验结果
3.2.1翻页下载
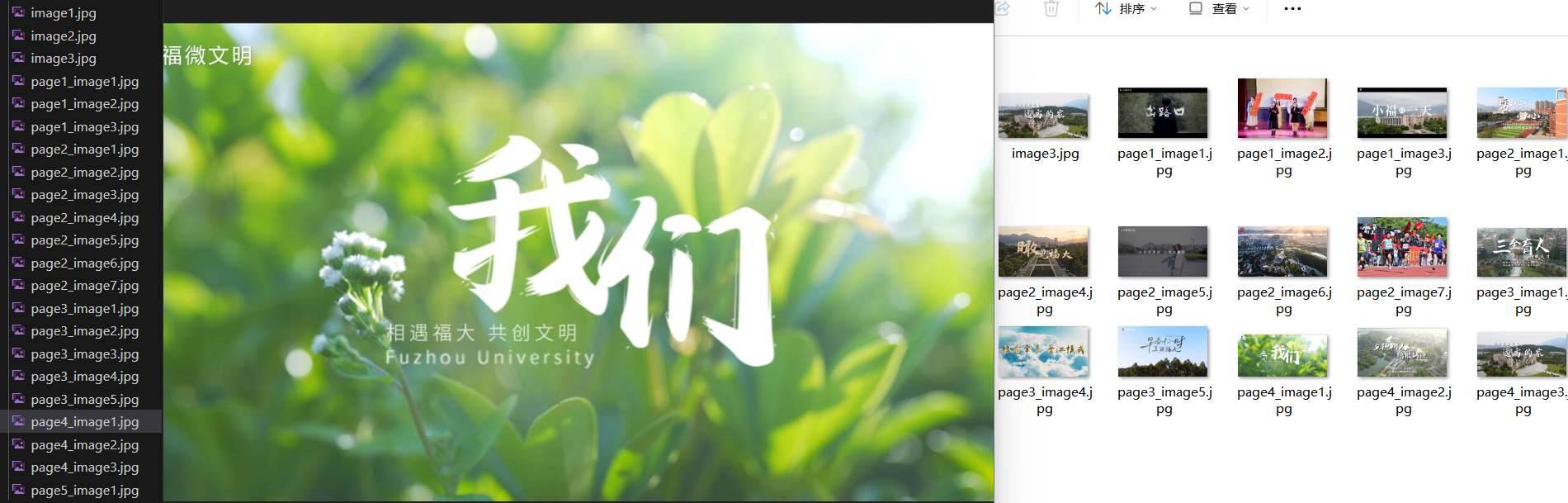
3.2.2本地存储
3.3实验心得
3.3.1翻页处理
循环构建URL的便利性
- 通过循环和字符串格式化构建不同页面URL(如
base_url = "https://news.fzu.edu.cn/yxfd/{}.htm"与for page_num in range(1, 6): url = base_url.format(page_num)),这种方法对已知页码范围的情况简单有效,无需手动逐个输入URL。
局限性与可能的改进方向 - 当页面URL结构更复杂(如页码位置不固定或分页逻辑不规则)时,这种循环构建URL的方式不适用。可考虑分析页面分页链接元素提取链接来翻页,或研究网站分页接口获取分页数据。
3.3.2图片爬取
利用BeautifulSoup查找图片标签的高效性
- 使用
BeautifulSoup的find_all("img", src=lambda src: src and src.endswith(".jpg"))可高效筛选出以.jpg结尾的图片链接,基于标签属性和条件筛选能准确定位目标图片元素,提高爬取准确性和效率。
图片下载与保存的关键要点 - 下载图片时,需用
urljoin确保图片URL完整(如full_url = urljoin("https://news.fzu.edu.cn/", img_url)),防止因URL不完整无法正确下载。保存图片时,以二进制模式("wb")打开文件写入图片数据(with open(img_filename, "wb") as img_file: img_file.write(img_data))可确保图片正确保存到本地。
可能遇到的问题与解决方法 - 图片爬取可能遇图片加载慢或部分无法访问的问题,可能由网络或网站访问限制导致。可在
requests.get中添加timeout参数设置合理超时时间避免程序停滞,对无法访问的图片可记录URL后续排查或尝试其他获取途径。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)