
Java中HashMap实现原理
类声明:
![]()
概述:
- 线程不安全;
- <Key, Value>两者都可以为null;
- 不保证映射的顺序,特别是它不保证该顺序恒久不变;
- HashMap使用Iterator;
- HashMap中hash数组的默认大小是16,增长方式一定是2的指数倍;
HashMap的数据结构:
在Java语言中,最基本的结构只有两种,一个是数组,另一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造。HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
通过分析这两种数据结构的优劣,才能得出HashMap这样设计的缘由:
-
数组:
数组存储区间是连续的,可以通过下标迅速访问数组中任何元素,同样,如果想删除一个元素,那么需要移动大量元素,插入操作同理。但占用内存严重,所以空间复杂度很大。不过数组的二分查找时间复杂度小,仅为O(1)。数组的特点是:寻址容易,插入和删除困难。 -
链表:
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,为O(N)。链表的特点是:寻址困难,插入和删除容易。 -
HashMap的选择:哈希表
哈希表综合了两者的特性,做出一种寻址容易,插入删除也容易的数据结构。哈希表(Hash table)既满足了数据的查找方便,同时不占用太多的内容空间。

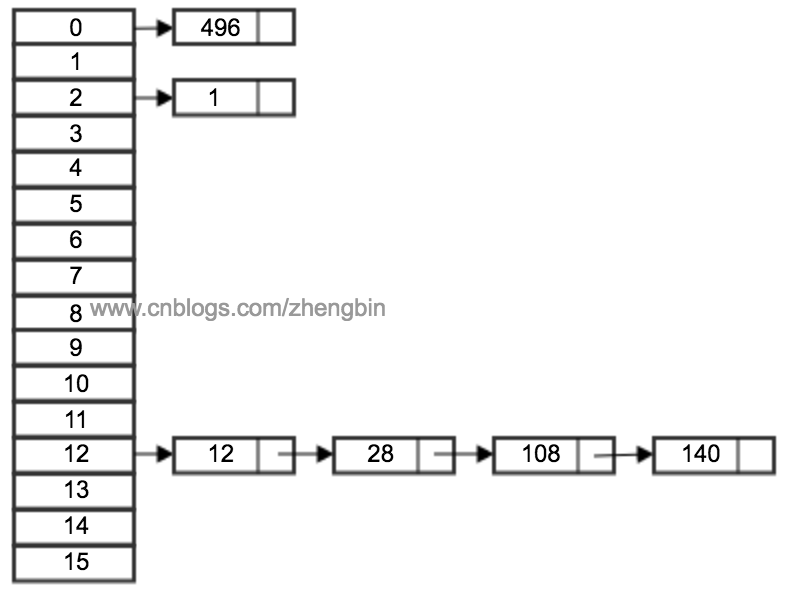
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。然后通过hash(key)%len获得元素存储在数组中的下标值,也就是元素的key的哈希值对数组长度取模得到。比如上图的哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108和140都存储在数组下标为12的位置。
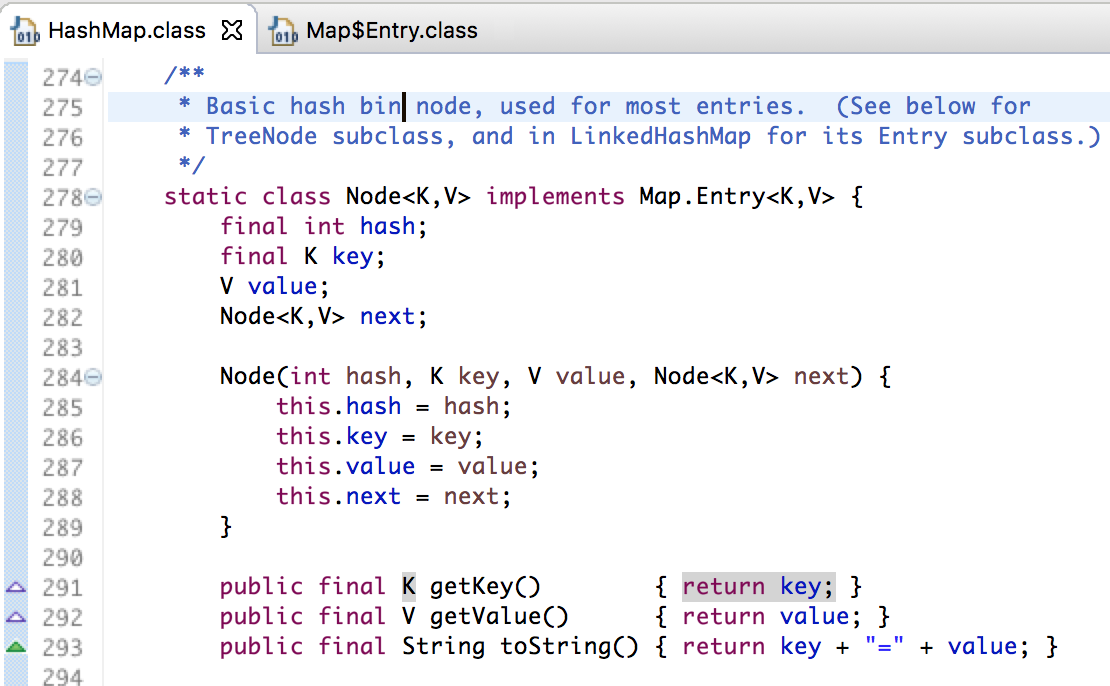
HashMap实现了一个静态内部类Node,其实现了Map.Entry接口。HashMap中实现的数组就是Node[],Map中的内容都保存在Node[]中,如下图所示。
梦想要一步步来!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号