算法学习笔记2:感知机
在机器学习中,感知机(perceptron)是二分类的线性分类模型,属于监督学习算法。输入为实例的特征向量,输出为实例的类别(取+1和-1)。感知机对应于输入空间中将实例划分为两类的分离超平面。感知机旨在求出该超平面,为求得超平面导入了基于误分类的损失函数,利用梯度下降法 对损失函数进行最优化(最优化)。感知机的学习算法具有简单而易于实现的优点,分为原始形式和对偶形式。感知机预测是用学习得到的感知机模型对新的实例进行预测的,因此属于判别模型。感知机由Rosenblatt于1957年提出的,是神经网络和支持向量机的基础。
1、定义
假设输入空间(特征向量)为X⊆Rn,输出空间为Y={-1, +1}。输入x∈X表示实例的特征向量,对应于输入空间的点;输出y∈Y表示示例的类别。由输入空间到输出空间的函数:f(x)=sign(w·x+b)称为感知机。
其中,参数w叫做权值向量weight,b称为偏置bias。w·x表示w和x的内积。∑i=1mwixi=w1x1+w2x2+...+wnxn
sign为符号函数,即
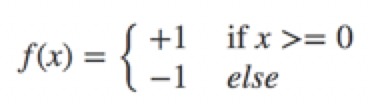
在二分类问题中,f(x)的值(+1或-1)用于分类x为正样本(+1)还是负样本(-1)。
感知机是一种线性分类模型,属于判别模型。我们需要做的就是找到一个最佳的满足w⋅x+b=0的w和b值,即分离超平面(separating hyperplane)。如下图,一个线性可分的感知机模型。
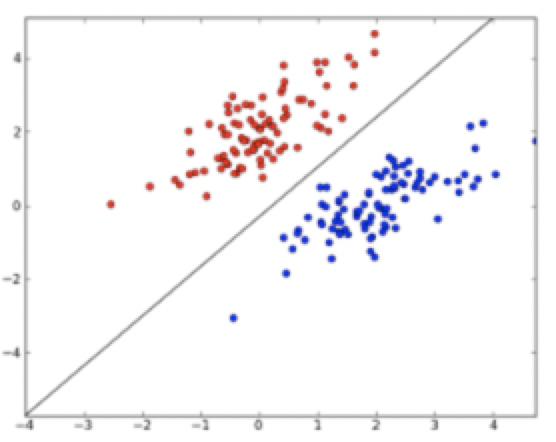
中间的直线即w⋅x+b=0这条直线。
线性分类器的几何表示有:直线、平面、超平面。
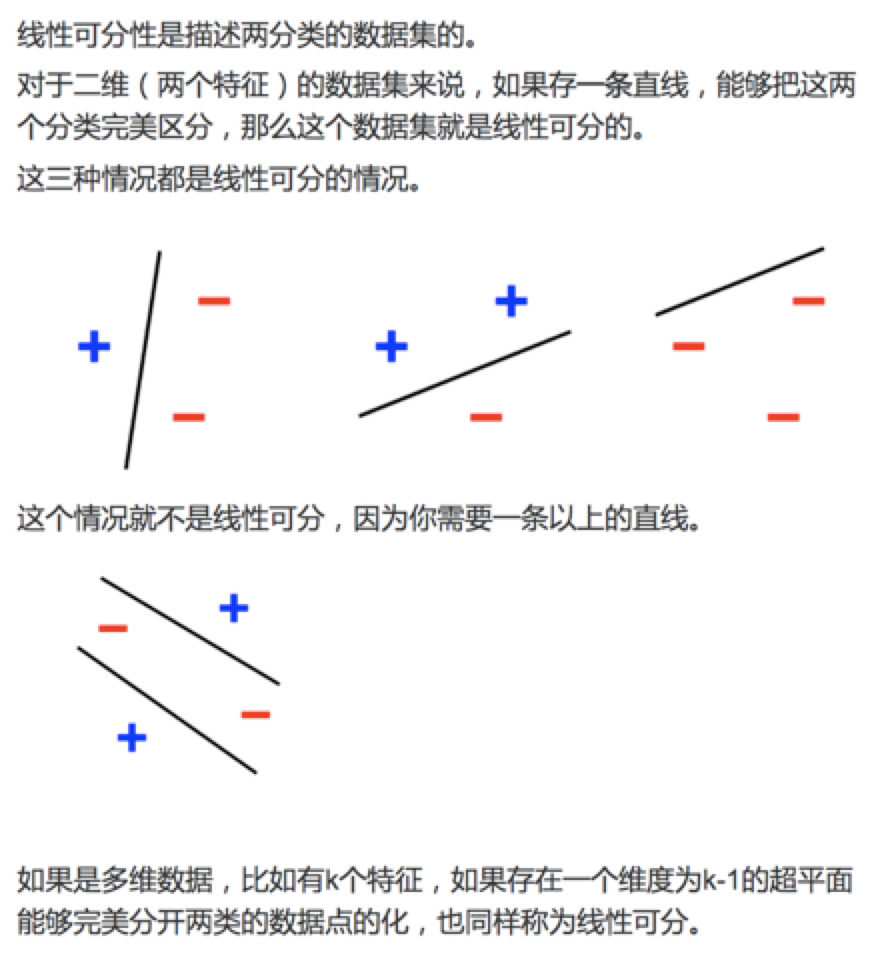
2、数据集的线性可分性

参考:李航《统计学习方法》
3、感知机学习策略
损失函数
如果训练集是可分的,感知机的学习目的是求得一个能将训练集正实例点和负实例点完全分开的分离超平面。为了找到这样一个平面(或超平面),即确定感知机模型参数w和b,即确定感知机模型参数w,b,需要确定一个学习策略,即定义(经验)损失函数并将损失函数极小化。
损失函数的一个自然选择是误分类点的总数,但是这样的损失函数不是参数w,b的连续可导函数,不易优化,损失函数的另一个选择是误分类点到超平面的距离(可以自己推算一下,这里采用的是几何间距,就是点到直线的距离)

其中||w||是L2范数。(什么是L2范数:机器学习中的范数规则化之(一)L0、L1与L2范数)
对于误分类点(xi,yi)来说:−yi(w∗xi+b)>0 成立
误分类点到超平面的距离为:
那么,所有点到超平面的总距离为:
不考虑
就得到感知机的损失函数了。
其中M为误分类的集合。这个损失函数就是感知机学习的经验风险函数。
可以看出,随时函数L(w,b)是非负的。如果没有误分类点,则损失函数的值为0,而且误分类点越少,误分类点距离超平面就越近,损失函数值就越小。一个特定的样本点的损失函数:在误分类时是参数w,b的线性函数,在正确分类时是0,因此,对于给定的训练数据集T,损失函数L(w,b)是连续可导函数。
感知机学习的策略是在假设空间中选取使损失函数式最小的模型参数w,b,即感知机模型。
4、感知机学习算法
感知机学习转变成求解损失函数L(w,b)的最优化问题。最优化的方法是随机梯度下降法(stochastic gradient descent),这里采用的就是该方法。关于梯度下降的详细内容,参考wikipedia Gradient descent。下面给出一个简单的梯度下降的可视化图:

上图就是随机梯度下降法一步一步达到最优值的过程,说明一下,梯度下降其实是局部最优。感知机学习算法本身是误分类驱动的,因此我们采用随机梯度下降法。
首先,任选一个超平面w0和b0,然后使用梯度下降法不断地极小化目标函数

极小化过程不是一次使M中所有误分类点的梯度下降,而是一次随机的选取一个误分类点使其梯度下降。使用的规则为 θ:=θ−α∇θℓ(θ),其中α是步长,∇θℓ(θ)是梯度。假设误分类点集合M是固定的,那么损失函数L(w,b)的梯度通过偏导计算:
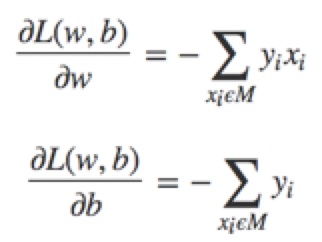
然后,随机选取一个误分类点,根据上面的规则,计算新的w,b,然后进行更新:
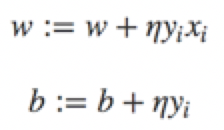
其中η是步长,大于0小于1,在统计学习中称之为学习率(learning rate)。这样,通过迭代可以期待损失函数L(w,b)不断减小,直至为0.
综上所述,得到如下算法:
4.1感知机学习算法原始形式
输入:T={(x1,y1),(x2,y2)...(xN,yN)}(其中xi∈X=Rn,yi∈Y={-1, +1},i=1,2...N,学习速率为η) 输出:w, b;感知机模型f(x)=sign(w·x+b) (1) 初始化w0,b0,权值可以初始化为0或一个很小的随机数 (2) 在训练数据集中选取(x_i, y_i) (3) 如果yi(w xi+b)≤0
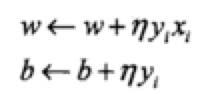
(4) 转至(2),直至训练集中没有误分类点
直观解释:当一个实例点被误分类时,调整w,b,使分离超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直至超越该点被正确分类。
上面的算法是感知机的基本算法,对应于后面的对偶形式,称为原始形式。
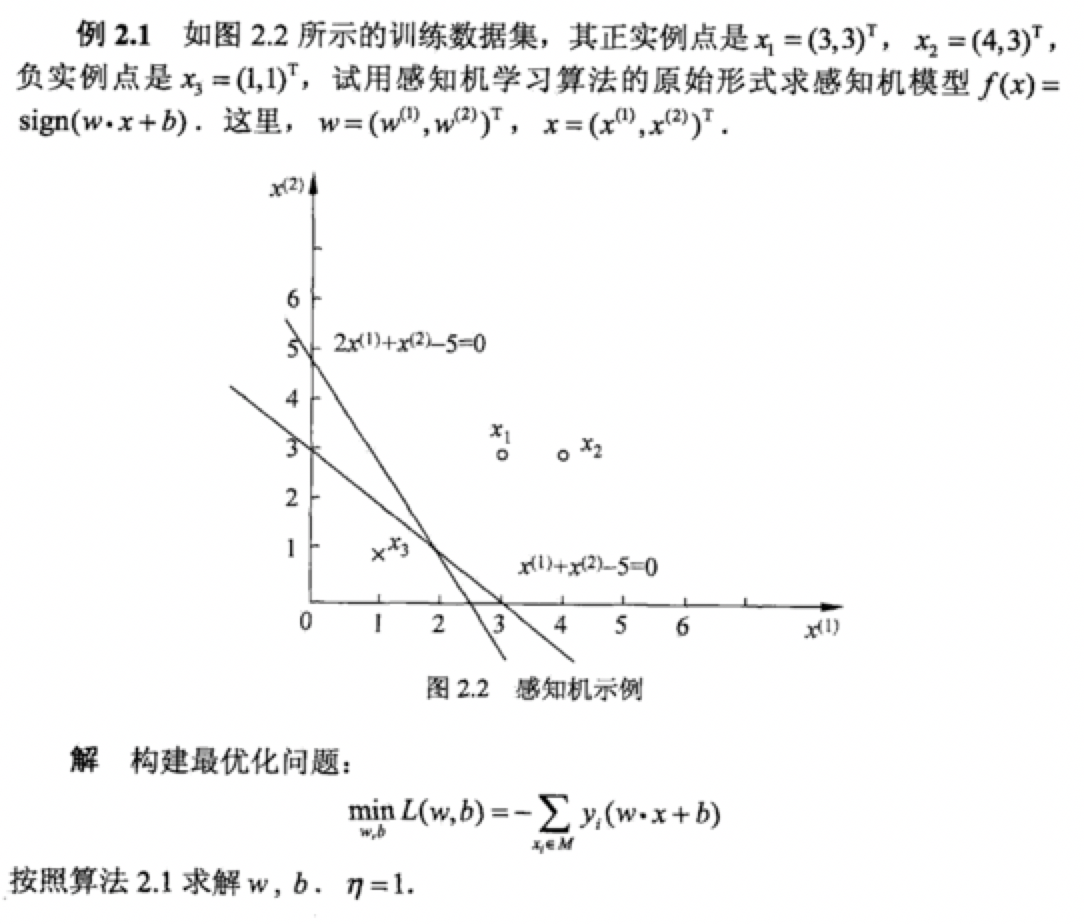

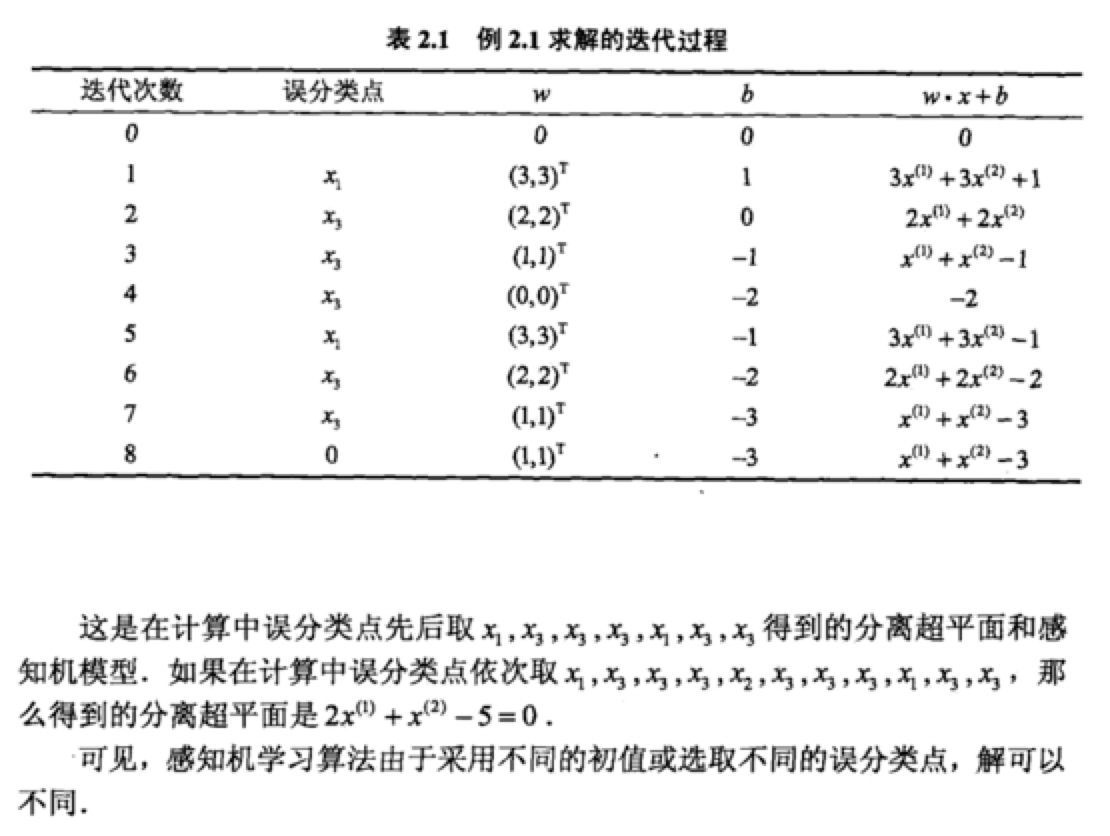
4.1感知机学习算法的对偶形式



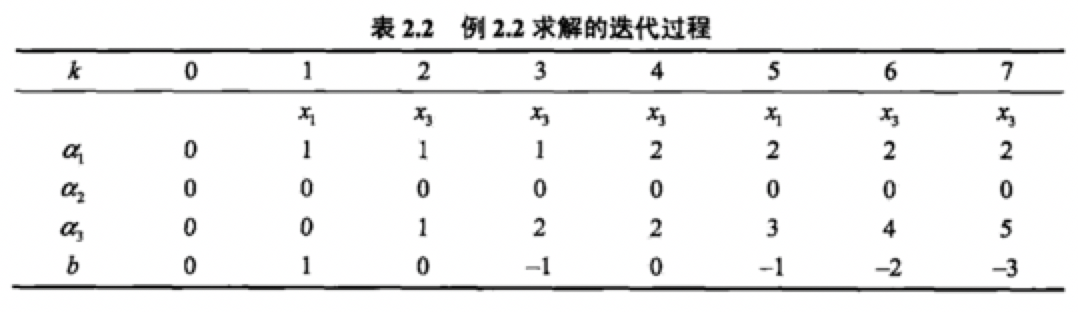
我们推导如下。从原始形式中我们可以知道。w的更新过程。
第一次更新是x1y1=((3,3)T,1 ) 点不能是函数模型大于零,所以 w1=w0+x1y1
第二次更新是x3y3=((1,1)T,-1 )点不能使其大于零,所以 w2=w1+x3y3
第三次更新是x3y3=((1,1)T,-1 )点不能使其大于零,所以 w3=w2+x3y3
第四次更新是x3y3=((1,1)T,-1 )点不能使其大于零,所以 w4=w3+x3y3
第五次更新是x1y1=((3,3)T,1 )点不能使其大于零,所以 w5=w4+x1y1
第六次更新是x3y3=((1,1)T,-1 )点不能使其大于零,所以 w6=w5+x3y3
第七次更新是x3y3=((1,1)T,-1 )点能使其大于零,所以 w7=w6+x3y3
然后我们得到
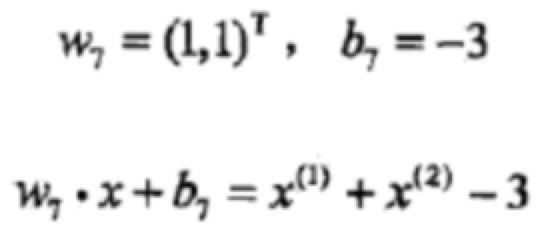
从上面可以总结出w7=w6+x3y3
w7=w5+x3y3 +x3y3
w7=w4+x1y1+x3y3 +x3y3
w7=w3+x3y3+x1y1+x3y3 +x3y3
w7=w2+x3y3+x3y3+x1y1+x3y3 +x3y3
w7=w1+x3y3 +x3y3+x3y3+x1y1+x3y3 +x3y3
w7=w0+x1y1 +x3y3 +x3y3+x3y3+x1y1+x3y3 +x3y3
所以我们可以得出最终w7的值为两次x1y1 +五次x3y3
也就等于在对偶形式中
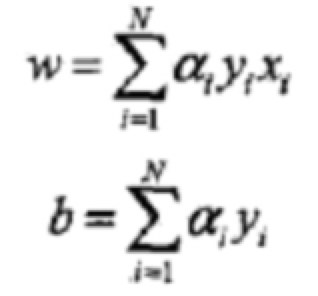
5、python实现


1 import random 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 def sign(v): 6 if v>=0: 7 return 1 8 else: 9 return -1 10 11 def train(train_num,train_datas,lr): 12 w=[0,0] 13 b=0 14 for i in range(train_num): 15 x=random.choice(train_datas) 16 x1,x2,y=x 17 if(y*sign((w[0]*x1+w[1]*x2+b))<=0): 18 w[0]+=lr*y*x1 19 w[1]+=lr*y*x2 20 b+=lr*y 21 return w,b 22 23 def plot_points(train_datas,w,b): 24 plt.figure() 25 x1 = np.linspace(0, 8, 100) 26 x2 = (-b-w[0]*x1)/w[1] 27 plt.plot(x1, x2, color='r', label='y1 data') 28 datas_len=len(train_datas) 29 for i in range(datas_len): 30 if(train_datas[i][-1]==1): 31 plt.scatter(train_datas[i][0],train_datas[i][1],s=50) 32 else: 33 plt.scatter(train_datas[i][0],train_datas[i][1],marker='x',s=50) 34 plt.show() 35 36 if __name__=='__main__': 37 train_data1 = [[1, 3, 1], [2, 2, 1], [3, 8, 1], [2, 6, 1]] # 正样本 38 train_data2 = [[2, 1, -1], [4, 1, -1], [6, 2, -1], [7, 3, -1]] # 负样本 39 train_datas = train_data1 + train_data2 # 样本集 40 w,b=train(train_num=50,train_datas=train_datas,lr=0.01) 41 plot_points(train_datas,w,b)
1 import random 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 def sign(v): 6 if v>=0: 7 return 1 8 else: 9 return -1 10 11 def train(train_num,train_datas,lr): 12 w=0.0 13 b=0 14 datas_len = len(train_datas) 15 alpha = [0 for i in range(datas_len)] 16 train_array = np.array(train_datas) 17 gram = np.matmul(train_array[:,0:-1] , train_array[:,0:-1].T) 18 for idx in range(train_num): 19 tmp=0 20 i = random.randint(0,datas_len-1) 21 yi=train_array[i,-1] 22 for j in range(datas_len): 23 tmp+=alpha[j]*train_array[j,-1]*gram[i,j] 24 tmp+=b 25 if(yi*tmp<=0): 26 alpha[i]=alpha[i]+lr 27 b=b+lr*yi 28 for i in range(datas_len): 29 w+=alpha[i]*train_array[i,0:-1]*train_array[i,-1] 30 return w,b,alpha,gram 31 32 def plot_points(train_datas,w,b): 33 plt.figure() 34 x1 = np.linspace(0, 8, 100) 35 x2 = (-b-w[0]*x1)/(w[1]+1e-10) 36 plt.plot(x1, x2, color='r', label='y1 data') 37 datas_len=len(train_datas) 38 for i in range(datas_len): 39 if(train_datas[i][-1]==1): 40 plt.scatter(train_datas[i][0],train_datas[i][1],s=50) 41 else: 42 plt.scatter(train_datas[i][0],train_datas[i][1],marker='x',s=50) 43 plt.show() 44 45 if __name__=='__main__': 46 train_data1 = [[1, 3, 1], [2, 2, 1], [3, 8, 1], [2, 6, 1]] # 正样本 47 train_data2 = [[2, 1, -1], [4, 1, -1], [6, 2, -1], [7, 3, -1]] # 负样本 48 train_datas = train_data1 + train_data2 # 样本集 49 w,b,alpha,gram=train(train_num=500,train_datas=train_datas,lr=0.01) 50 plot_points(train_datas,w,b)
6、参考资料
李航《统计学习方法》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号