Python爬虫学习笔记7:动态渲染页面爬取
参考:Python3网络爬虫开发实战
问题:Ajax 是javascript动态渲染页面的一种情形,可以通过分析Ajax,然后借用requests和urllib来实现数据爬取。不过Javascript动态渲染的页面不止这一种。
比如中国青年网(详见 http://news.youth.cn/gn/), 它的分页部分是由 JavaScript生成的,并非原始 HTML 代码,这其中并不包含 Ajax请求 。 比如 ECharts 的官方实例(详见 http://echarts.baidu.com/demo.html#bar-negative ),其图形都是经过 JavaScript计算之 后生成的。 再有淘宝这种页面,它即使是 Ajax获取的数据,但是其 Ajax接口含有很多加密参数,我 一一 们难以直接找出其规律,也很难直接分析 人jax来抓取
解决:使用模拟浏览器运行方式来实现,这样就可以做到在浏览器中看到是什么样,抓取的源码就是什么样,也即可见即可爬,这样就不用管网页内部的javascript用了什么渲染页面,不管网页后台的Ajax接口到底有哪些参数。
Python提供了许多模拟浏览器运行的库,如 Selenium、 Splash、 PyV8, Ghost等
7.1 Selenium 的使用
Selenium是一个 自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作, 同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。
基本使用
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw') # 找到输入框,根据id获取
input.send_keys('Python')
input.send_keys(Keys.ENTER)
wait = WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID,'content_left'))) # 里面要是一个元祖
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)
except:
print('Fail')
finally:
browser.close()
3. 声明浏览器对象
from selenium import webdriver browser = webdriver.Chrome() # google browser = webdriver.Firefox() # 火狐 browser = webdriver.Edge() browser = webdriver.PhantomJS() # 无界面 browser = webdriver.Safari() # mac自带浏览器
4. 访问页面
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com') # 通过get(url)
print(browser.page_source)
browser.close()
5. 查找节点
目的:找到输入框
·单个节点
淘宝

from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element_by_id('q') # id方式
input_second = browser.find_element_by_css_selector('#q') # css方式
input_third = browser.find_element_by_xpath('//*[@id="q"]') # xpath方式
print(input_first,input_second,input_third)
browser.close()
Selenium还提供了通用方法 find_element(),它需要传入两个参数: 查找方式 By和值。 实 际上,它就是 find_element_by_id()这种方法的通用函数版本,比如 find_element_by_id(id)就等价 于 find_element(By.ID, id)
·多个节点
find_element() 只能查找目标网页中的一个,要查找多个要用find_elements()
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd li')
print(lis)
browser.close()
6. 节点交互
http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement
输入文字:send_keys()
清空文字:clear()
点击按钮:click()
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element_by_id('q')
input.send_keys('iphone')
time.sleep(1)
input.clear()
input.send_keys('ipad')
button = browser.find_element_by_class_name('btn-search')
button.click()
淘宝要登陆,后面的看不到结果
7. 动作链
执行鼠标拖曳 、 键盘按键等动作
from selenium import webdriver from selenium.webdriver import ActionChains browser = webdriver.Chrome() url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable' browser.get(url) browser.switch_to.frame('iframeResult') source = browser.find_element_by_css_selector('#draggable') target = browser.find_element_by_css_selector('#droppable') actions = ActionChains(browser) actions.drag_and_drop(source, target) actions.perform()
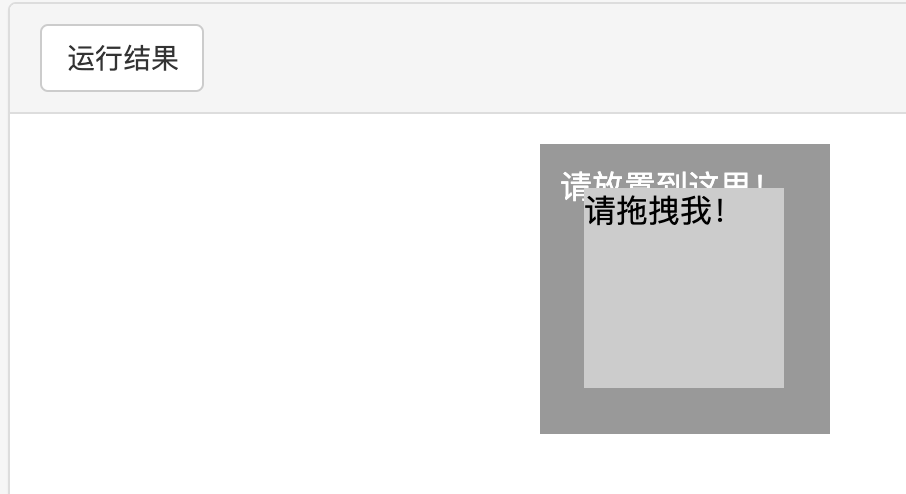
8 .执行javascript
对于没有提供的操作,如下拉进度条,可以使用excute_script()方法实现。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")') # 下拉到底部后,谈出alert提示框
9. 获取节点信息
page_source 属性可以获取网页的源代码,然后通过Beautiful soup pyquery进行信息提取
也可以使用selenium自带的获取属性、文本等
· 获取属性
get_attribute()方法来获取节点的属性
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
logo = browser.find_element_by_id('zh-top-link-logo')
print(logo)
print(logo.get_attribute('class'))
· 获取文本值
text()
·获取 id、位置、 标签名和大小
id 属性可以获取节点 id, location 属性可以获取该节点在页面中的相对位置, tag_name 属性可以获取标签名称, 就是宽高
10. 切换 Frame
网页中有一种节点叫作 iframe,也就是子 Frame,相当于页面的子页面,它的结构和外 部网页的结构完全一致。 Selenium打开页面后,它默认是在父级 Frame里面操作,而此时如果页面中 还有子 Frame,它是不能获取到子 Frame里面的节点的 。 这时就需要使用 switch_to.frame()方法来切 换 Frame
11. 延时等待
get()方法会在网页框架加载结束后结束执行,此时如果获取page_source,可能并不是浏览器完全加载完全的页面,如果有页面有额外的Ajax请求,在网页源代码中并不一定能成功获取,所以需要延时等待一下。
·隐式等待
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10) # 隐式等待,默认等待0秒,找不到继续等一会在找,容易受到页面加载时间的影响
browser.get('https://www.zhihu.com/explore')
input = browser.find_element_by_class_name('zu-top-add-question')
print(input)
·显式等待
指定一个最长等待时间
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser,10)
input = wait.until(EC.presence_of_element_located((By.ID,'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'.btn-search')))
print(input,button)
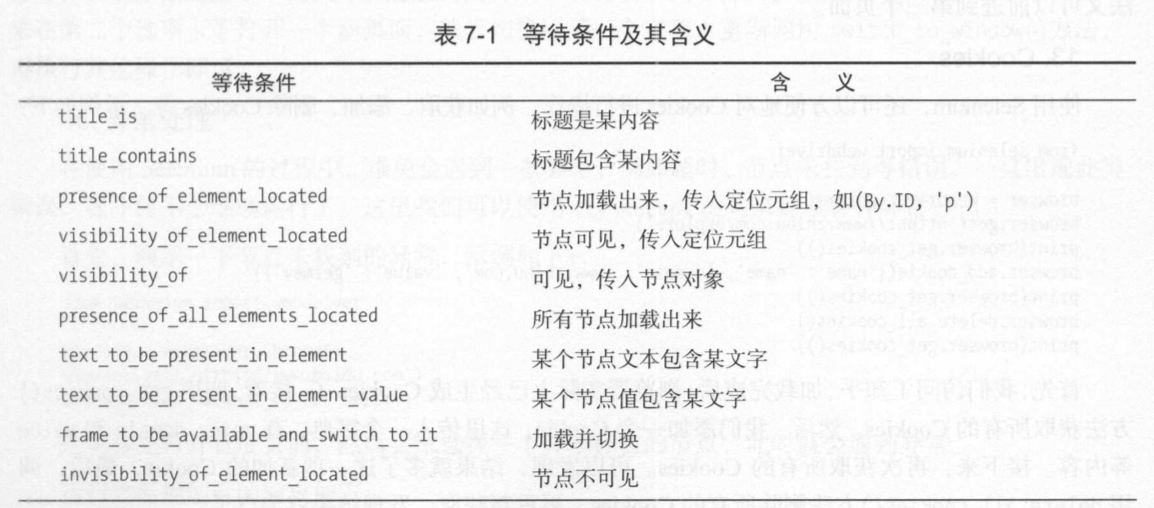

12. 前进和后退
forword() 前进下一个页面,back() 返回前一个页面
13. Cookies
get_cookies() 方法获取所有的 Cookie
add_cookies() 方法添加cookies
delete_all_cookies()方法删除所有的 Cookies
14. 选项卡管理
window handles 属性获取 当前开启 的所有选项卡 ,返回的是选项卡的代号列表
switch_to_window()方法 即可,其中参数是选项卡的代号
15. 异常处理
7.2 Splash 的使用

安装splash 要先安装docker,参考:http://www.runoob.com/docker/macos-docker-install.html

查看docker创建的容器,docker ps -l

查看创建的容器的映射 docker port 1defb38b57be
如果退出来了,执行docker run -p 8050:8050 scrapinghub/splash
4 Splash Lua脚本
function main(splash, args) #main 方法是固定的
splash:go("http://www.baidu.com")
splash:wait(0.5)
local title = splash:evaljs("document.title")
return { #返回可以是字符串形式也可以是字典形式
title = title
}
end
5 . Splash 对象属性
• args
• js_enabled 将其配置为 true或 false来控制是否执行 JavaScript 代码,默认为 true
• resource timeout 设置加载的超时时间,单位是秒
• images_enabled 设置图片是否加载,默认情况下是加载的。 禁用该属性后,可以节省网络流量并提高 网页加载速度
• plugins_enabled 控制浏览器插件(如 Flash插件)是否开启 。 默认情况下,此属性是 false
• scroll_position 设置此属性,我们可以控制页面上下或左右滚动
6. Splash 对象 的方法
•go() 用来请求某个链接,而且它可以模拟 GET 和 POST请求,同时支持传入请求头、表单等数据

• wait() 控制页面的等待时间

• jsfunc() 可以直接调用 JavaScript定义的方法,但是所调用的方法需要用双中括号包围,这相当于 实现了 JavaScript方法到 Lua脚本的转换
• evaljs()
可以执行 JavaScript代码并返回最后一条 JavaScript语句的返回结果
• runjs()
可以执行 JavaScript代码,它与 evaljs()的功能类似,但是更偏向于执行某些动作或声明 某些方法
• autoload()
此方法可以设置每个页面访问时自动加载的对象
7. Splash API 调用
• render.html
用于获取javascripte渲染页面 的HTML代码,接口地址就是splash的运行地址加此接口名称。
import requests curl = 'http://localhost:8050/render.html?url=http://www.baidu.com&wait=5' # 等待5秒 response = requests.get(curl) print(response.text)
• render.png
此接口可以获取网页截图,其参数比 render.html多了几个,比如通过 width 和 height 来控制宽高, 它返回的是 PNG格式的图片二进制数据
import requests
url = 'http://localhost:8050/render.png?url=http://www.jd.com&wait=5&width=1000&height=700'
response = requests.get(url)
with open('jd.png','wb') as f:
f.write(response.content)
• render.bar
此接口用于获取页面加载的 HAR数据
• render.json
此接口包含了前面接口的所有功能,返回结果是 JSON格式
• execute
此接口才是最为强大的接口 。 前面说了很多 SplashLua脚本的操作,用此接口便可实现与 Lua脚本的对接 。
前面的 render.html和 render.png等接口对于一般的 JavaScript渲染页面是足够了 ,但是如果要实现
一些交互操作的话,它们还是无能为力,这里就需要使用 execute接口。
import requests
from urllib.parse import quote
lua = '''
function main(splash) # 这里没有冒号
return 'hello'
end
'''
url = 'http://localhost:8050/execute?lua_source=' + quote(lua) # 对脚本进行URL转码
response = requests.get(url)
print(response.text)
7.3 Splash 负载均衡配置
7.4 使用 Selenium 爬取淘宝商品
淘宝,它的整个页面数据确实也是通过 Ajax获取的,但是这些 Ajax接口 参数比较复杂,可能会包含加密密钥等, 所以如果想自己构造 Ajax 参数,还是比较困难的 。 对于这 种页面 , 最方便快捷 的抓取方法就是通过 Selenium
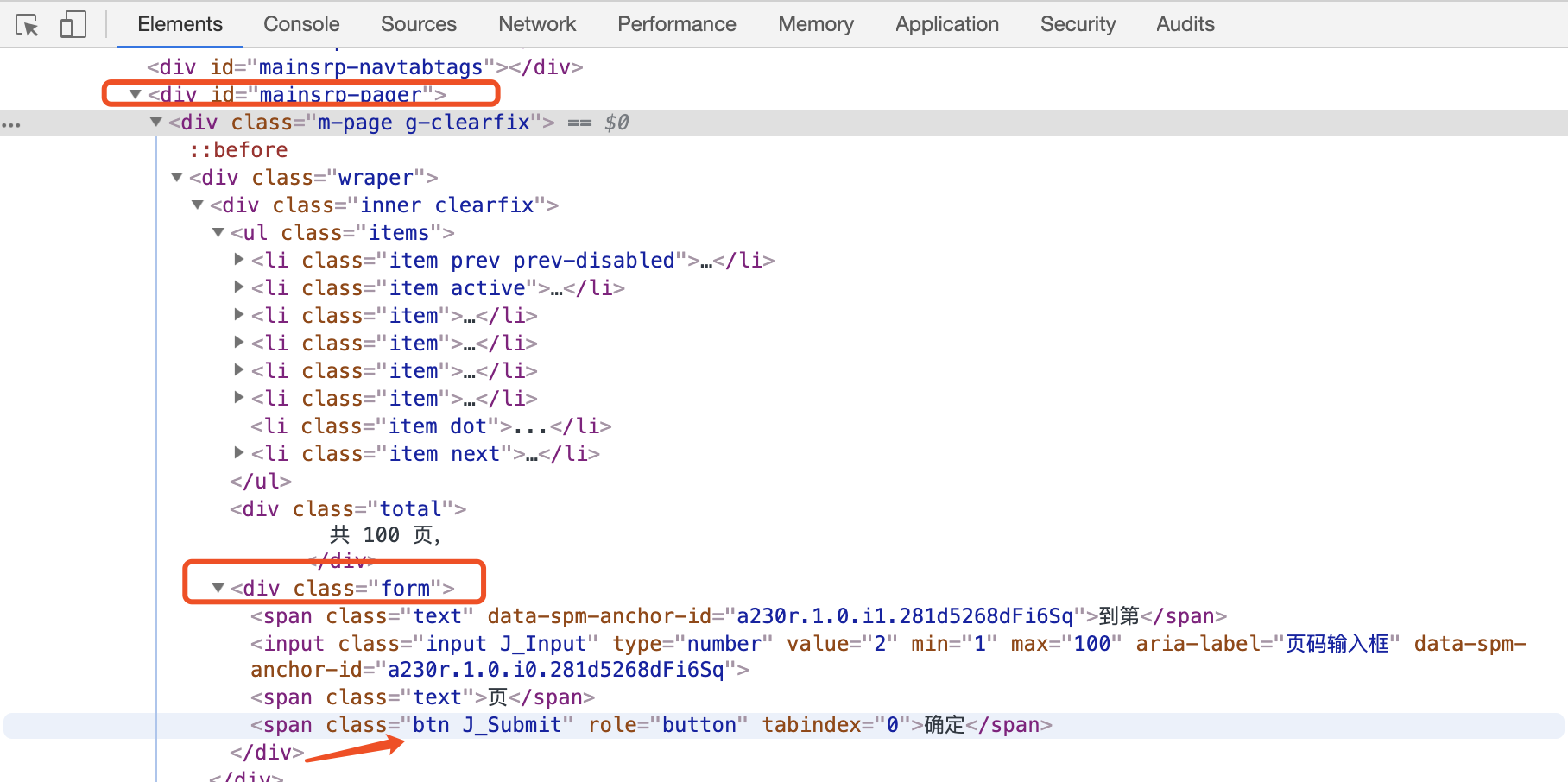
商品列表信息
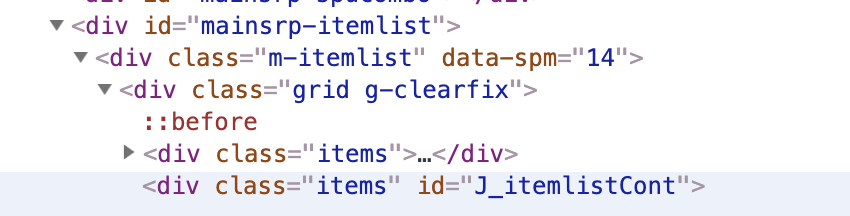
# 爬取淘宝页面商品信息,包括商品名称、商品价格、购买人数、店铺名称、店铺所在地
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from urllib.parse import quote
from pyquery import PyQuery as pq
import json
browser = webdriver.Chrome()
wait = WebDriverWait(browser,10)
KEYWORD = 'iPad'
def index_page(page):
print('正在爬取第',page,'页')
try:
url = 'https://www.taobao.com/search?q=' + quote(KEYWORD)
browser.get(url)
if page > 1: # 如果大于1,就进行跳转操作,否则等待页面加载完成
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager div.from>input'))
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#mainsrp-pager div.from>span.btn.J_Submit'))
)
input.clear()
input.send_keys(page)
submit.click()
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager li.item.active>span'),str(page))
)
wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'.m-itemlist .items .item'))
)
get_products()
except TimeoutException:
index_page(page)
def get_products():
taobao_data = []
html = browser.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('data-src'),
'price': item.find('.price').text(),
'deal': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
print(product)
taobao_data.append(product)
with open('taobao.json','a',encoding='utf-8') as f:
f.write(json.dumps(taobao_data, indent=2, ensure_ascii=False))
# MONGO_URL = 'localhost'
# MONGO_DB = 'taobao'
# MONGO_COLLECTION = 'products'
# client = pymongo.MongoClient(MONGO_URL)
# db = client[MONGO_DB]
#
# def save_to_mongo(result):
# try:
# if db[MONGO_COLLECTION].insert(result):
# print('存储到MongoBD 成功')
# except Exception:
# print('存储到MongoBD 失败')
MAX_PAGR = 100
def main():
for i in range(1,MAX_PAGR+1):
index_page(i)
main()
测试代码跑起来了,不过提示页面找不到了,没爬取成功,后面在补充学习
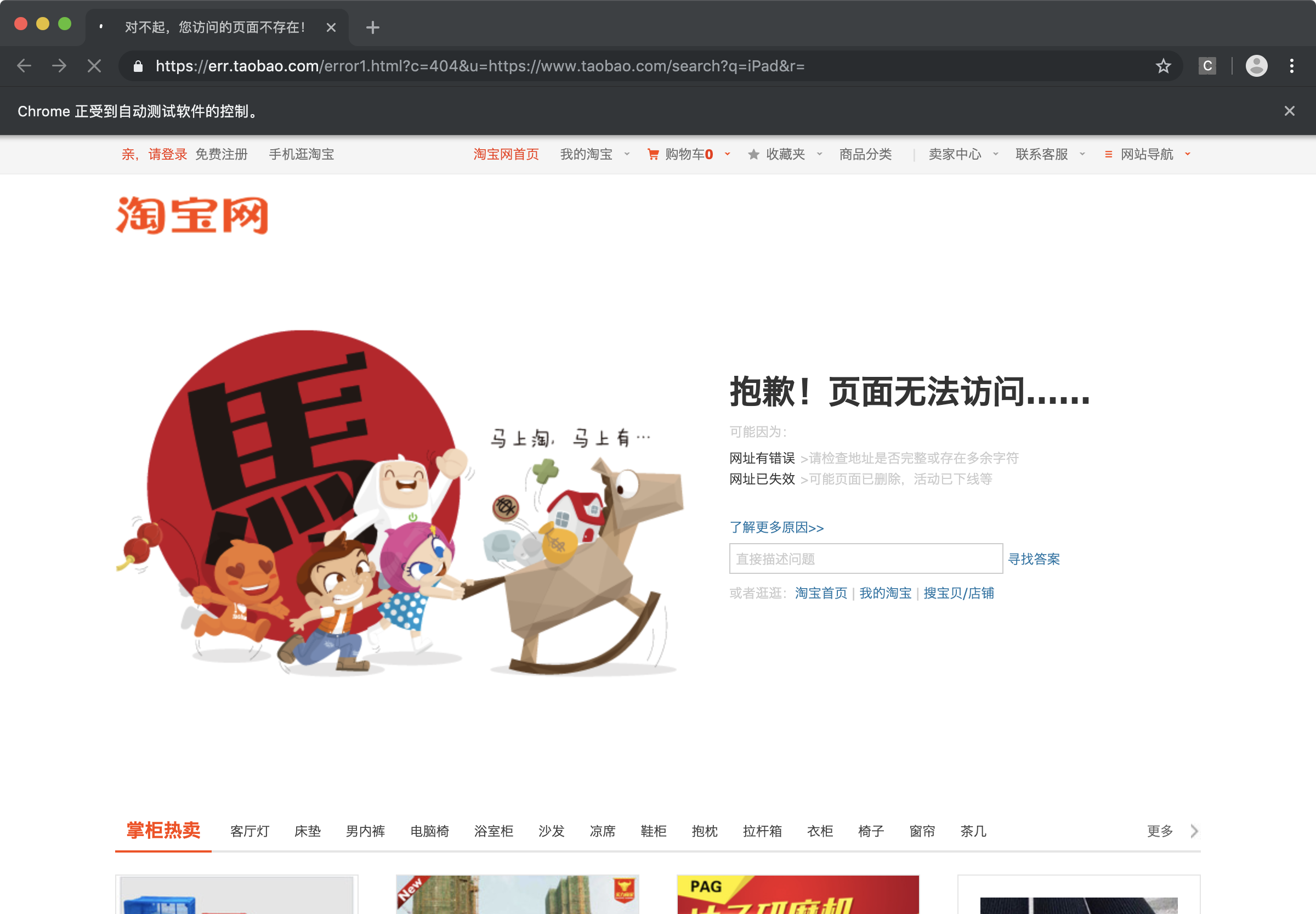
嗷嗷

 浙公网安备 33010602011771号
浙公网安备 33010602011771号