

算法学习笔记1:CNN
卷积神经网络
卷积神经网络(Convolutional Neural Network)简称CNN,CNN是所有深度学习课程、书籍必教的模型,CNN在影像识别方面的为例特别强大,许多影像识别的模型也都是以CNN的架构为基础去做延伸。另外值得一提的是CNN模型也是少数参考人的大脑视觉组织来建立的深度学习模型,学会CNN之后,对于学习其他深度学习的模型也很有帮助,本文主要讲述了CNN的原理以及使用CNN来达成99%正确度的手写字体识别。 CNN的概念图如下:
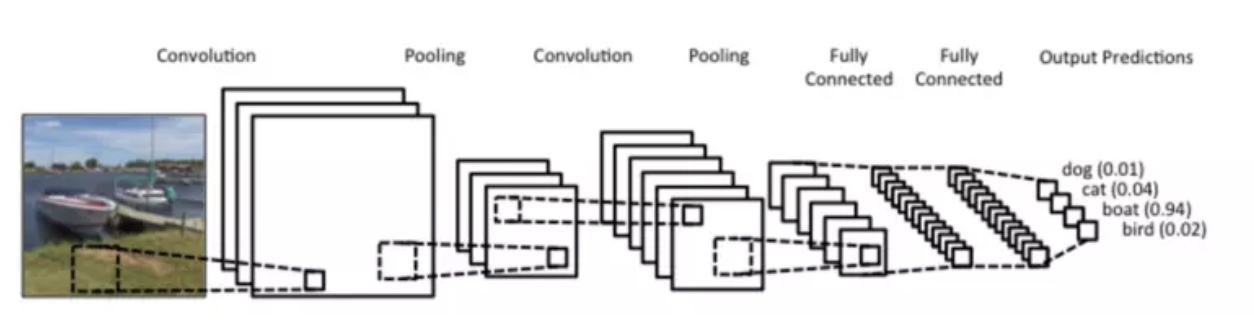
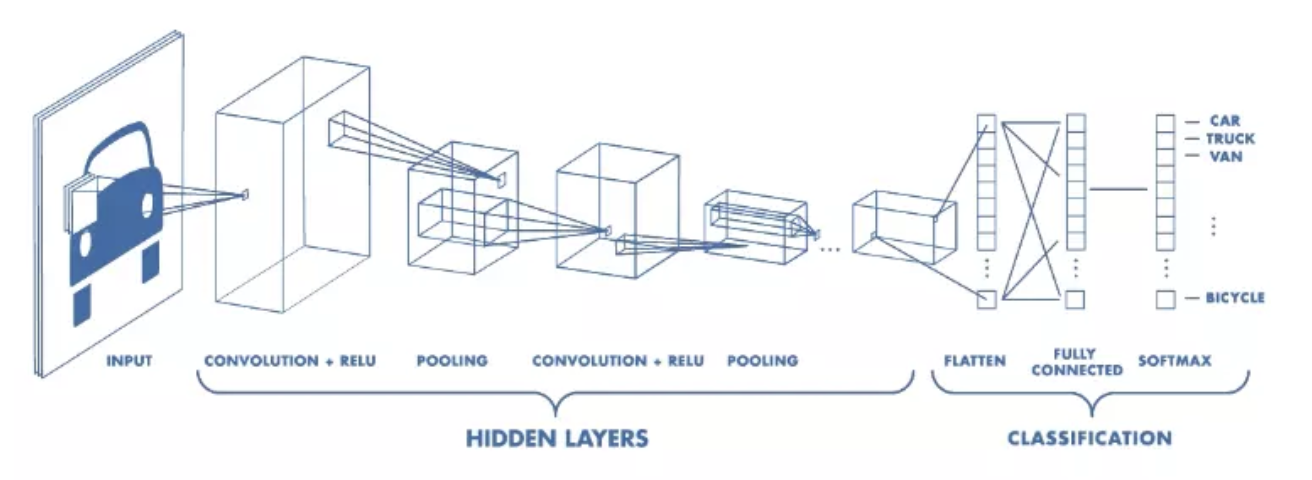
1 Convolution Layer卷积层
卷积运算就是将原始图片的与特定的Feature Detector(filter)做卷积运算(符号⊗),卷积运算就是将下图两个3x3的矩阵作相乘后再相加,3x3矩阵也叫“滤波器”、“核”或“特征探测器”,在原图上滑动滤波器、点乘矩阵所得的矩阵称为“卷积特征”、“激励映射”或“特征映射”。
以下图为例0 *0 + 0*0 + 0*1+ 0*1 + 1 *0 + 0*0 + 0*0 + 0*1 + 0*1 =0
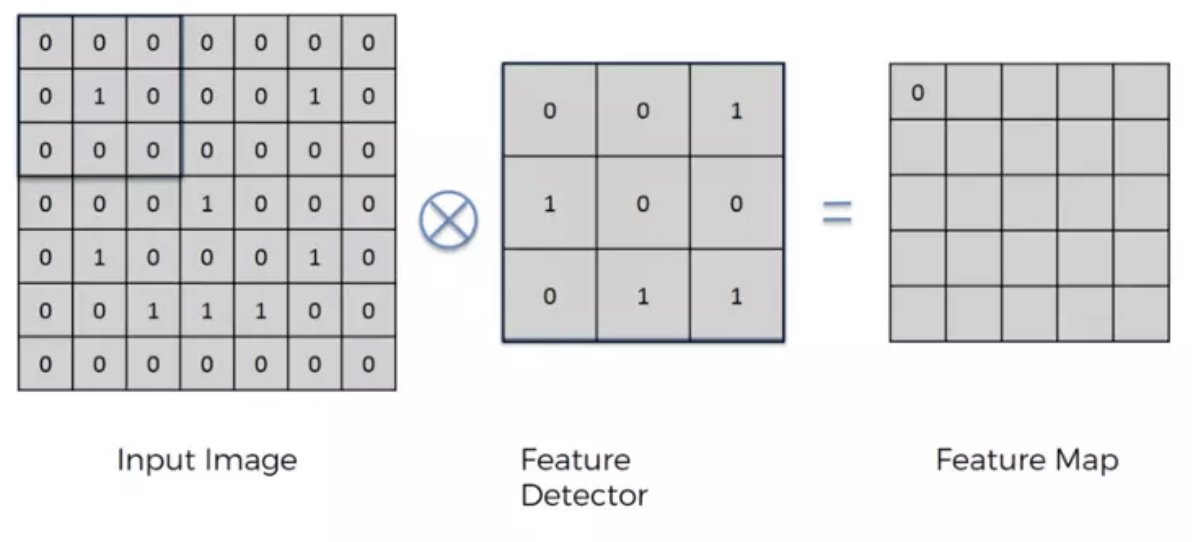
每次移动一步,我们可以一次做完整张表的计算,如下:

下面的动图更好地解释了计算过程:
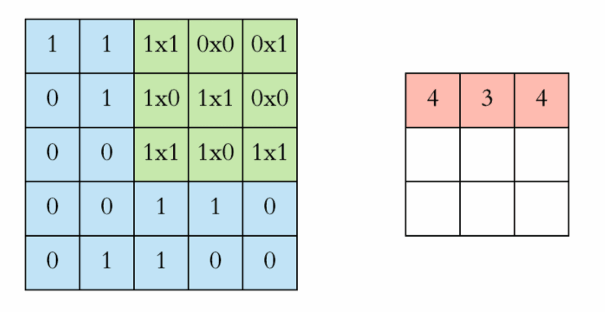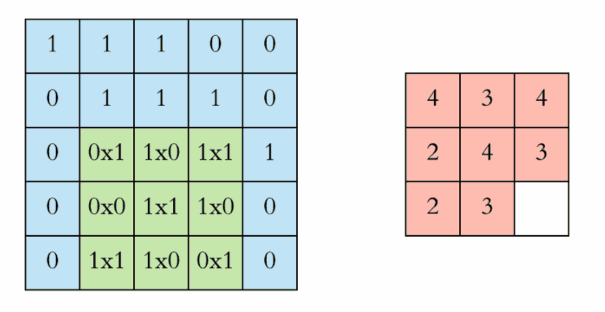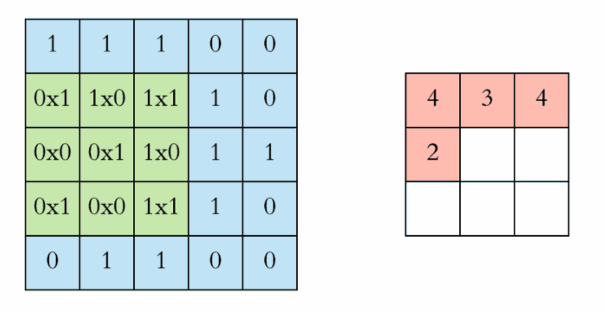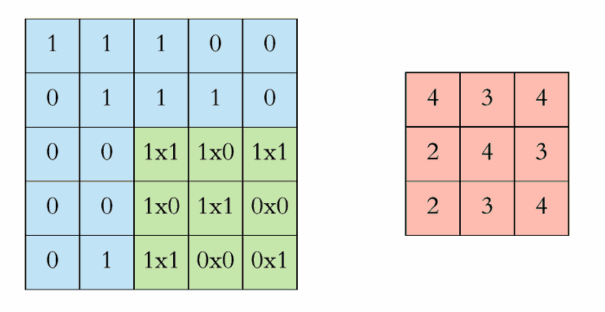
中间的Feature Detector(Filter)会随机产生好几种(ex:16种),Feature Detector的目的就是帮助我们萃取出图片当中的一些特征(ex:形状),就像人的大脑在判断这个图片是什么东西也是根据形状来推测
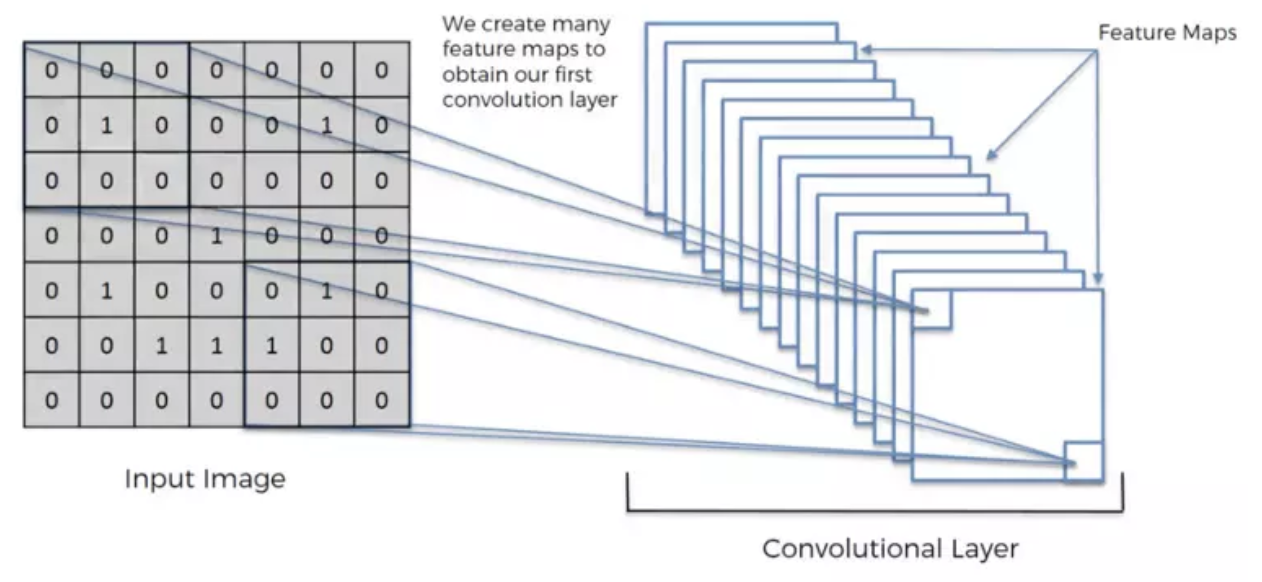
利用Feature Detector萃取出物体的边界
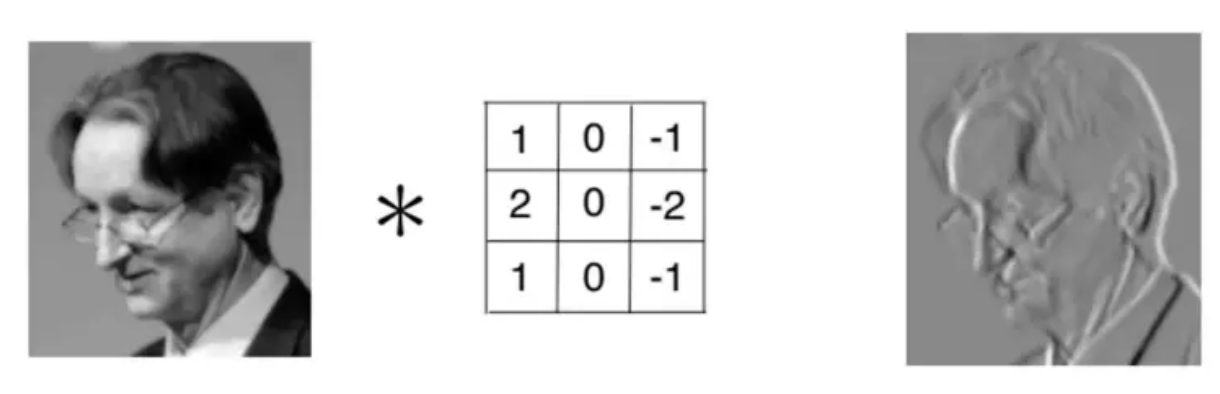
对于同一张照片,不同的滤波器将会产生不同的特征映射。比如考虑下面这张输入图片:

下表可见各种不同卷积核对于上图的效果。只需调整滤波器的数值,我们就可以执行诸如边缘检测、锐化、模糊等效果——这说明不同的滤波器会从图片中探测到不同的特征,比如边缘、曲线等。

另一种对卷积操作很好的理解方式就是观察图6的动画:

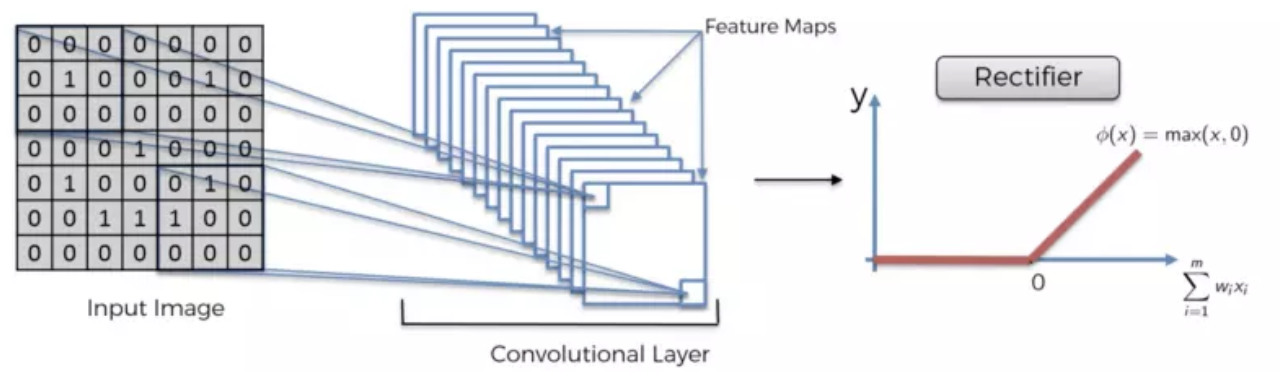
使用Relu函数去掉负值,更能淬炼出物体的形状
我们在输入上进行了多次卷积,其中每个操作使用不同的过滤器。这导致不同的特征映射。最后,我们将所有这些特征图放在一起,作为卷积层的最终输出。
下图可以帮助我们清晰地理解,ReLU应用在得到的特征映射上,输出的新特征映射也叫“纠正”特征映射。(黑色被抹成了灰色)

就像任何其他神经网络一样,我们使用激活函数使输出非线性。在卷积神经网络的情况下,卷积的输出将通过激活函数。这可能是ReLU激活功能
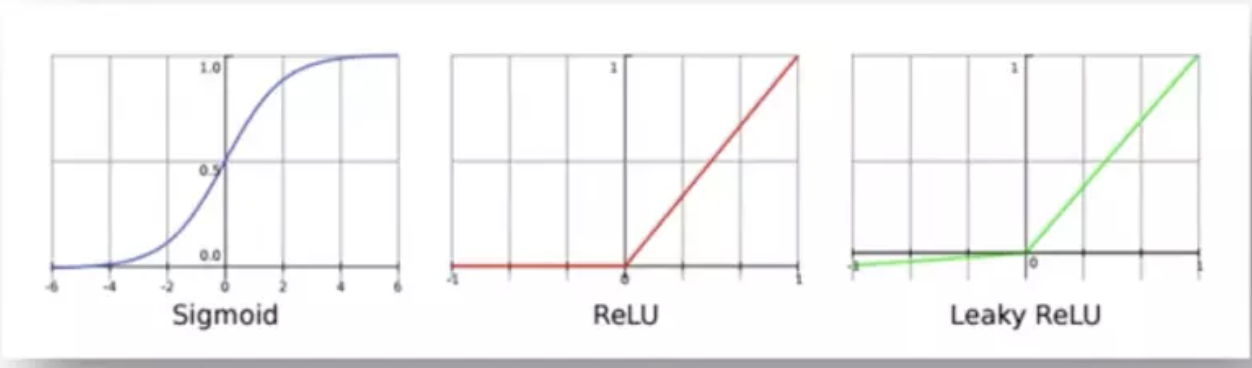
这里还有一个概念就是步长,Stride是每次卷积滤波器移动的步长。步幅大小通常为1,意味着滤镜逐个像素地滑动。通过增加步幅大小,您的滤波器在输入上滑动的间隔更大,因此单元之间的重叠更少。
下面的动画显示步幅大小为1。
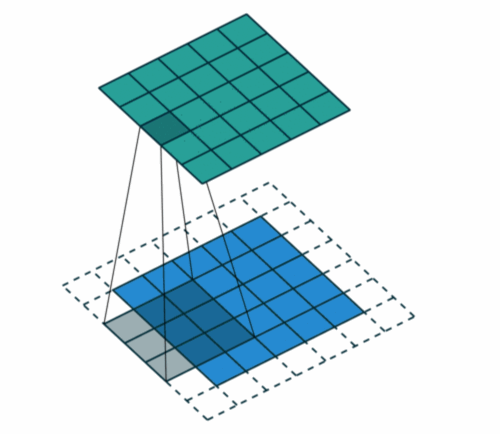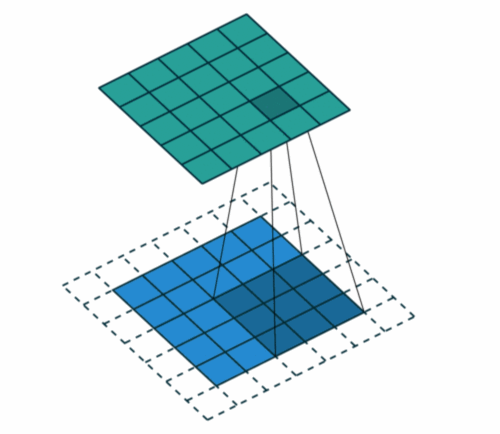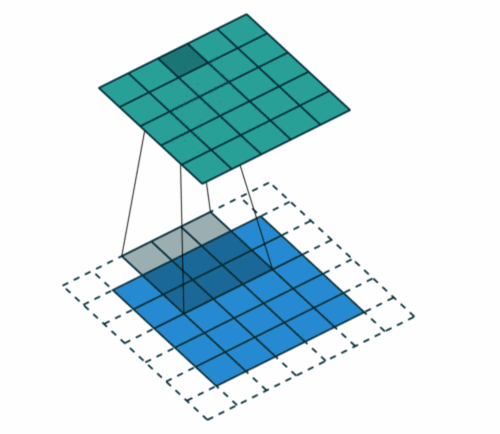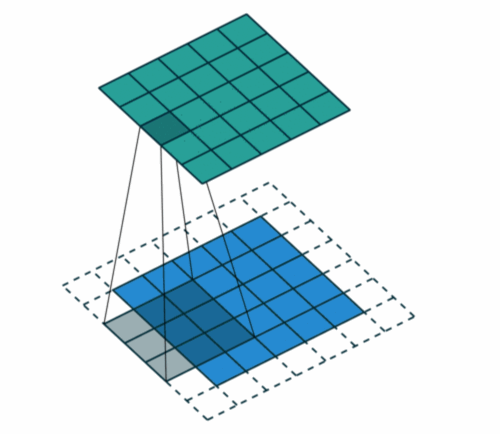
添加一层零值像素以使用零环绕输入,这样我们的要素图就不会缩小。除了在执行卷积后保持空间大小不变,填充还可以提高性能并确保内核和步幅大小适合输入。
可视化卷积层的一种好方法如下所示,最后我们以一张动图解释下卷积层到底做了什么
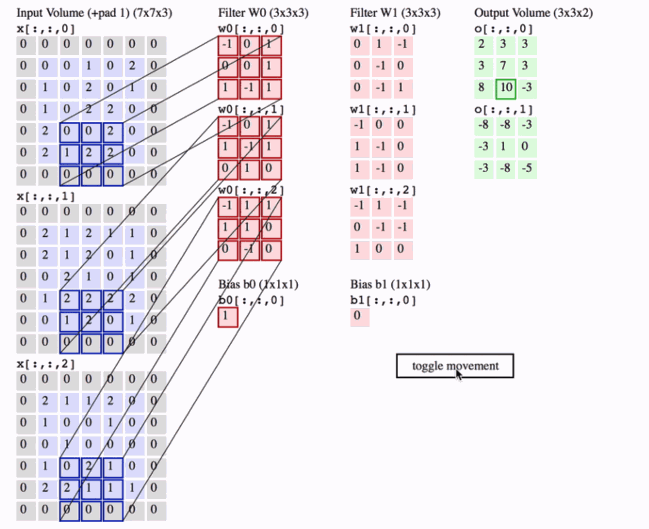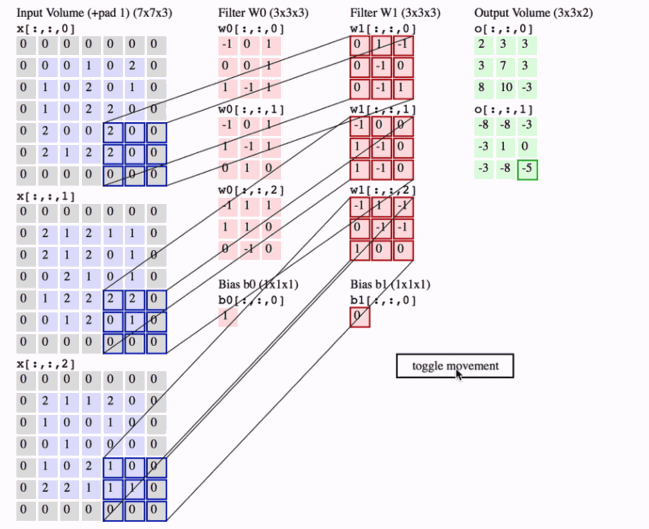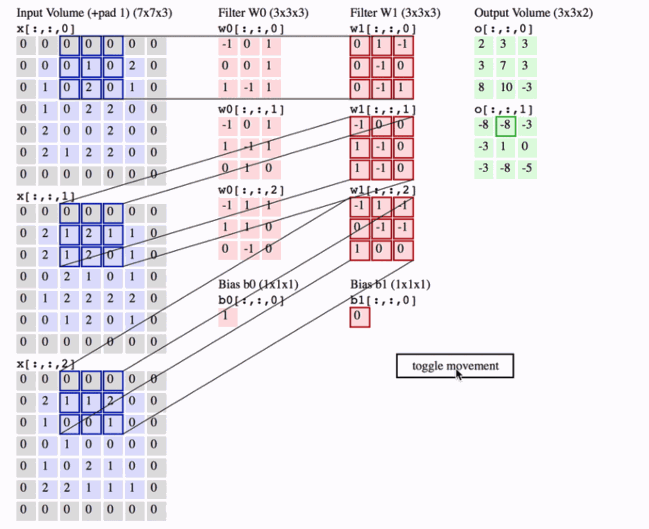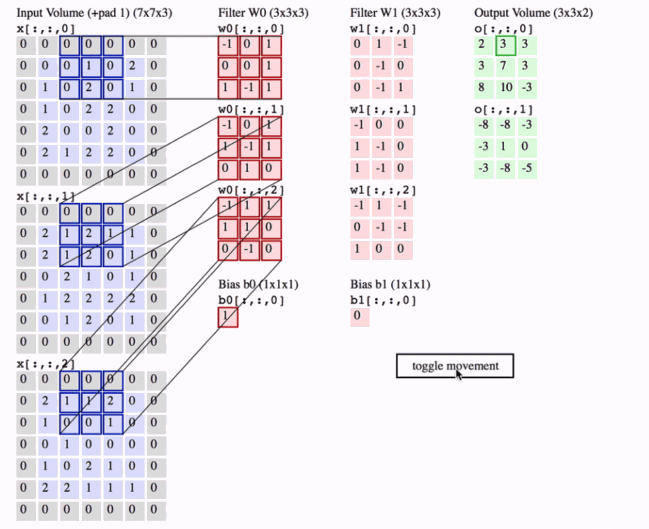
2 Pooling Layer 池化层
在卷积层之后,通常在CNN层之间添加池化层。池化的功能是不断降低维数,以减少网络中的参数和计算次数。这缩短了训练时间并控制过度拟合。
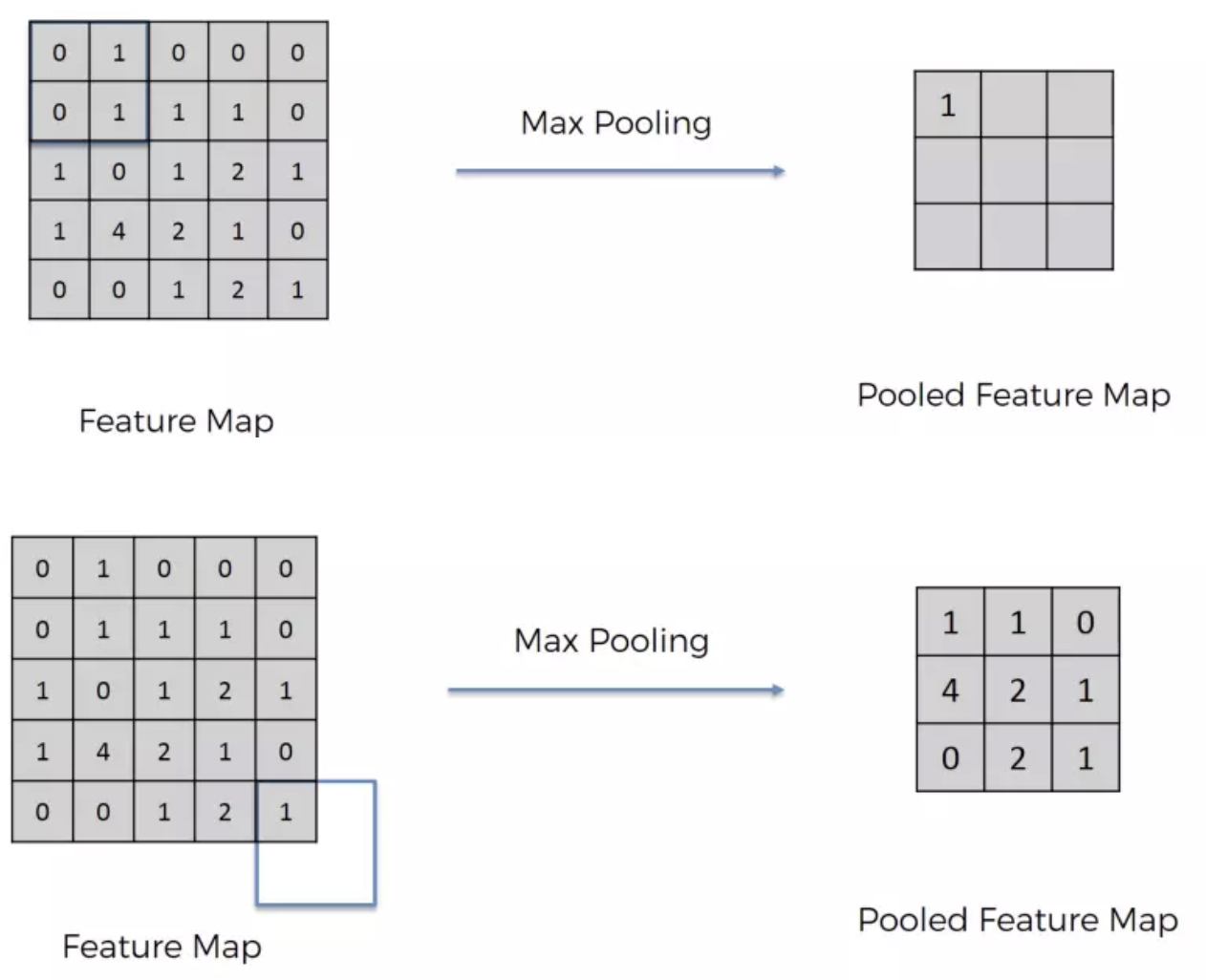
最常见的池类型是max pooling,它在每个窗口中占用最大值。需要事先指定这些窗口大小。这会降低特征图的大小,同时保留重要信息。
Max Pooling主要的好处是当图片整个平移几个Pixel的话对判断上完全不会造成影响,以及有很好的抗杂讯功能。
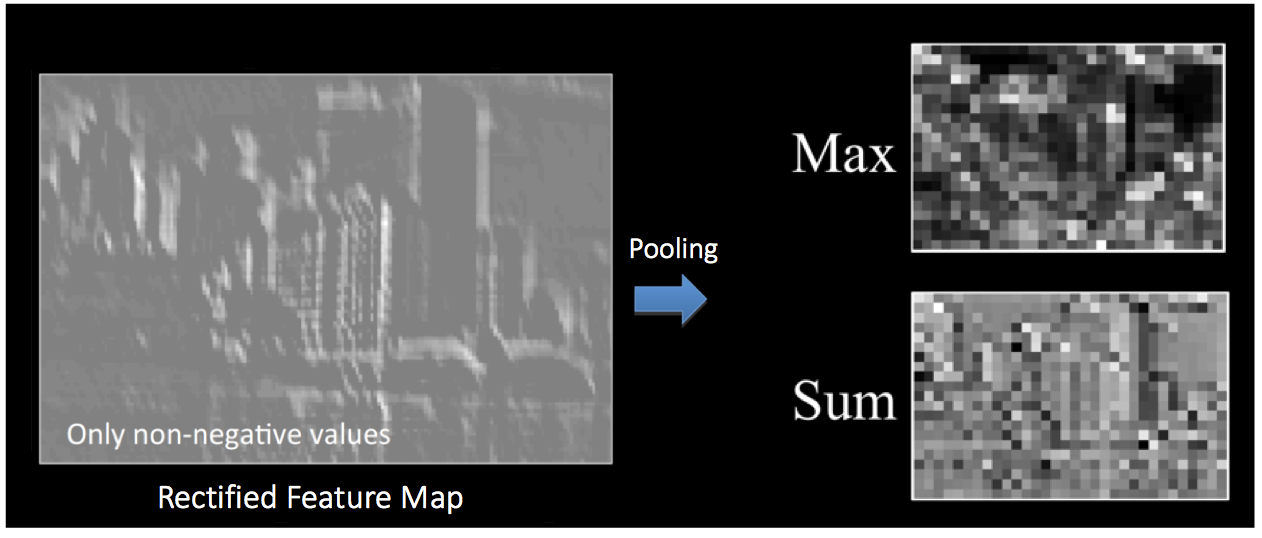
上图为不同池化操作所的纠正特征映射上的效果。
池化的功能室逐步减少输入表征的空间尺寸。特别地,池化
- 使输入表征(特征维度)更小而易操作
- 减少网络中的参数与计算数量,从而遏制过拟合
- 增强网络对输入图像中的小变形、扭曲、平移的鲁棒性(输入里的微小扭曲不会改变池化输出——因为我们在局部邻域已经取了最大值/平均值)。
- 帮助我们获得不因尺寸而改变的等效图片表征。这非常有用,因为这样我们就可以探测到图片里的物体,不论那个物体在哪。
3 Fully Connected Layer 全连接层
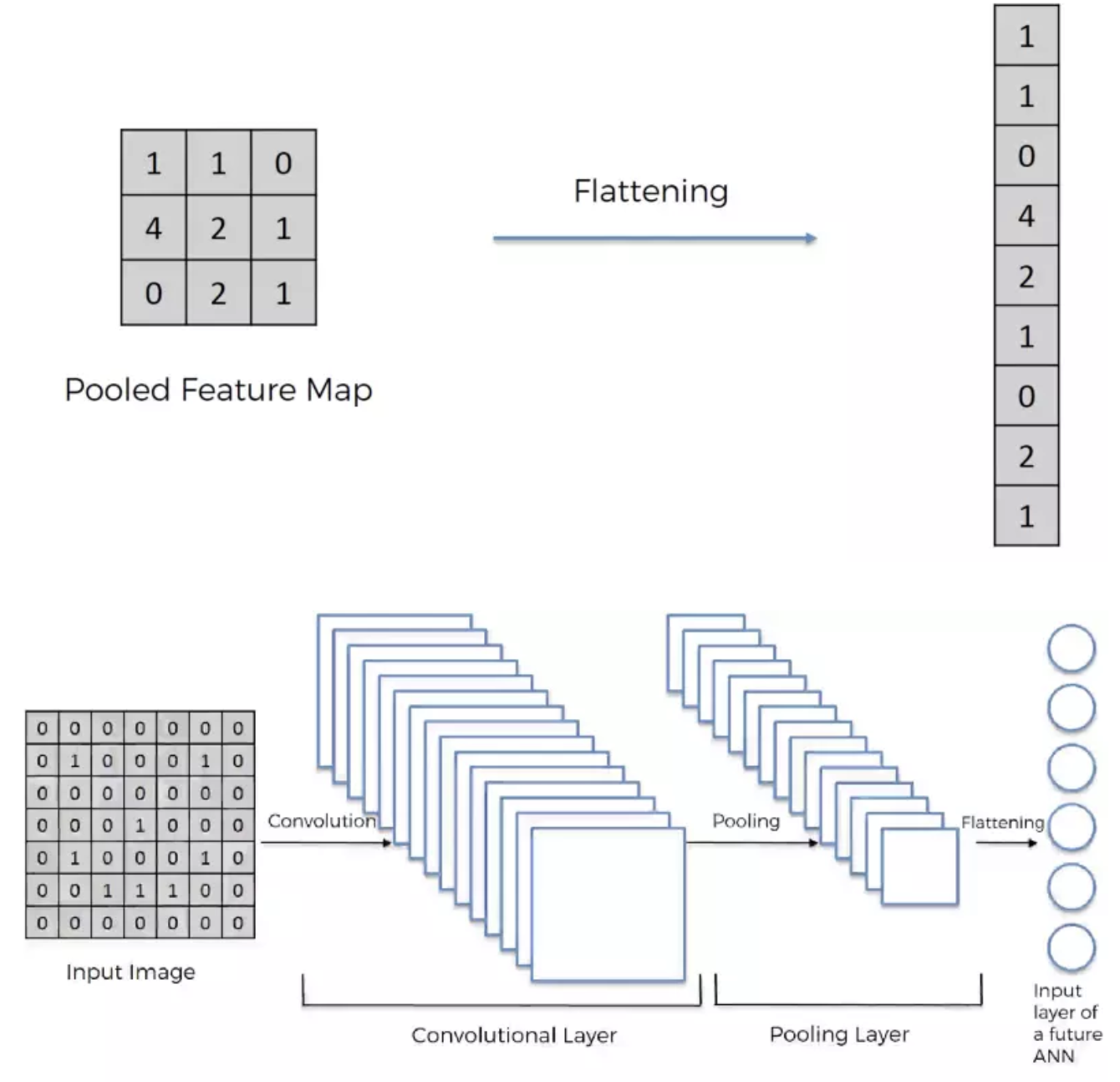
基本上全连接层的部分就是将之前的结果平坦化之后接到最基本的神经网络了
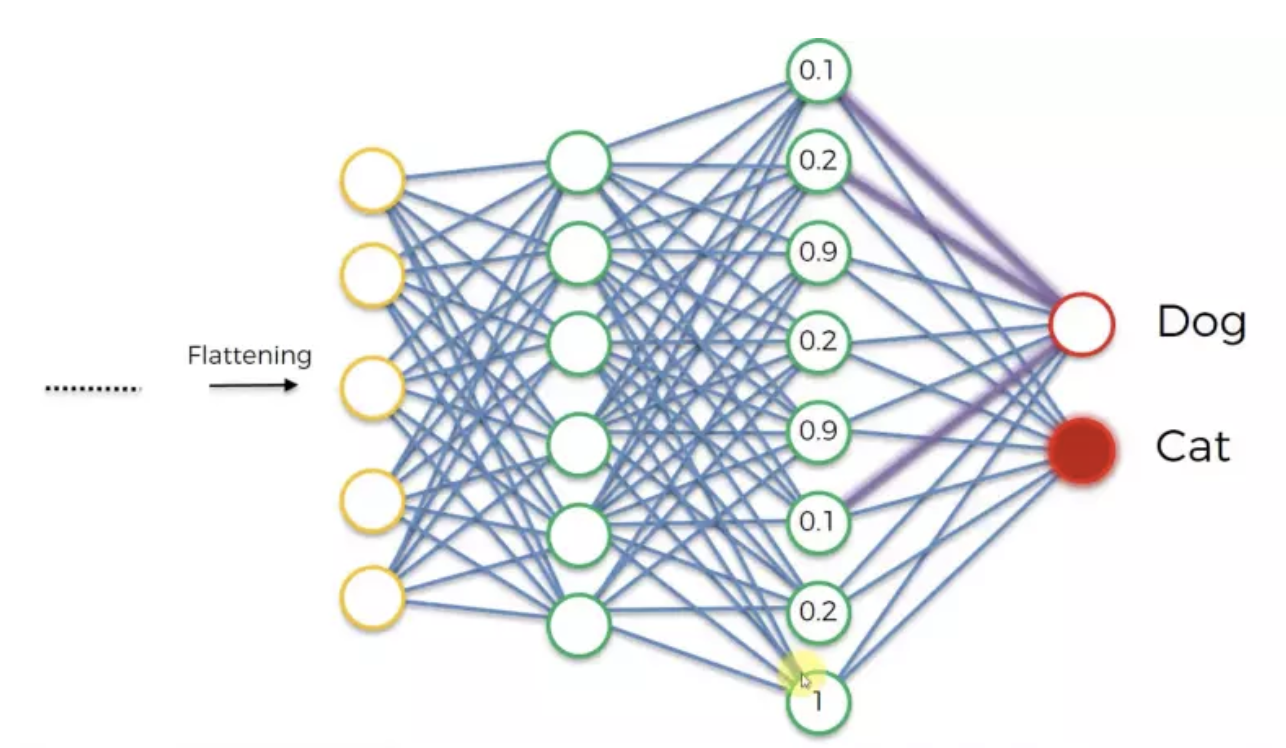
可视化卷积神经网络
一般来说,卷积层越多,能学会的特征也就越复杂。比如在图像分类中,一个卷积神经网络的第一层学会了探测像素中的边缘,然后第二层用这些边缘再去探测简单的形状,其他层再用形状去探测高级特征,比如脸型,如图17所示——这些特征是Convolutional Deep Belief Network学得的。这里只是一个简单的例子,实际上卷积滤波器可能会探测出一些没有意义的特征。

Adam Harley做了一个非常惊艳的卷积神经网络可视化,这个网络是用MNIST手写数字数据库训练而来的。我强烈推荐大家玩一玩,以便更深地理解卷积神经网络的细节。
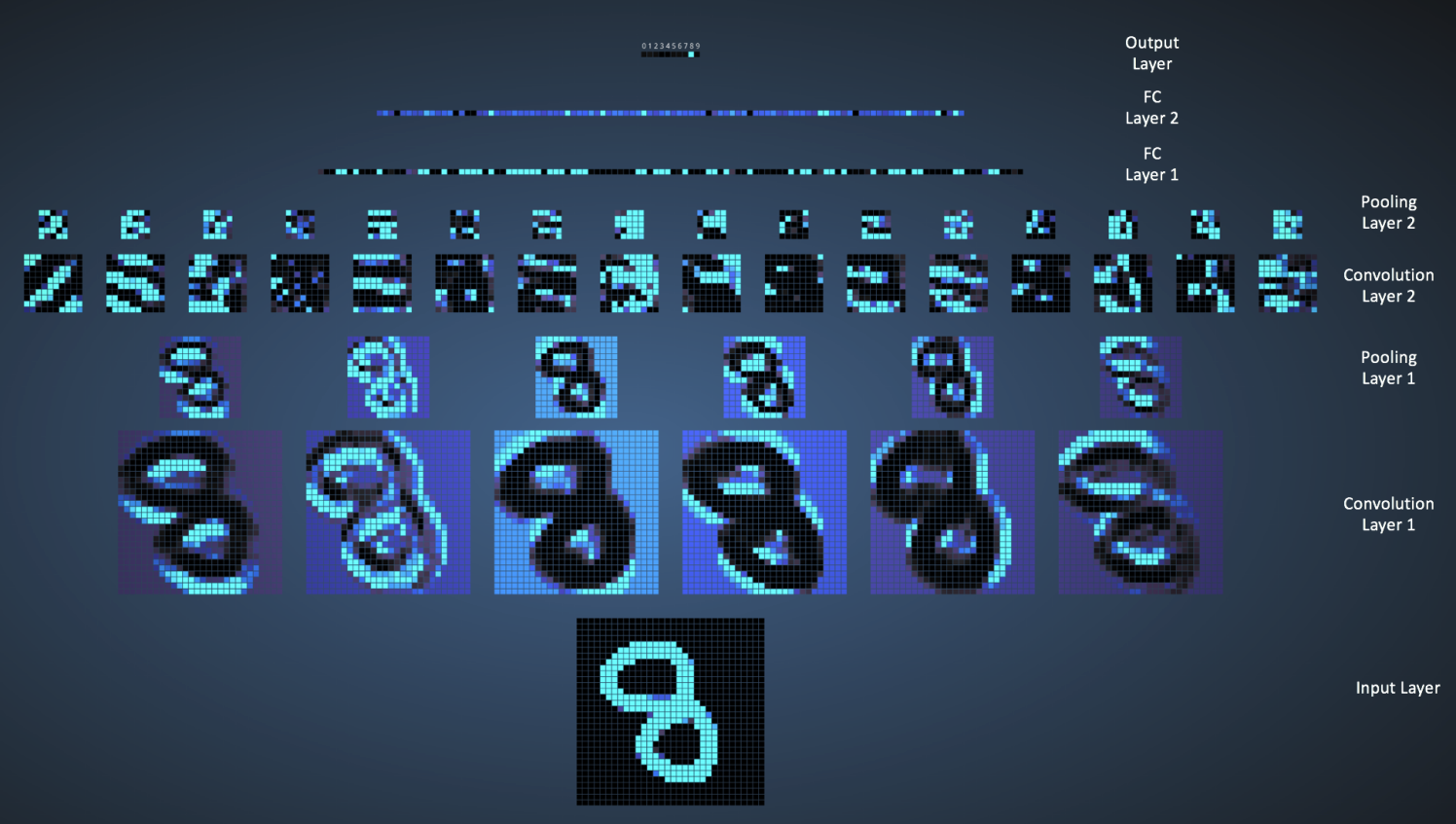
输入图像有1024个像素(32x32图片),第一个卷积层(Convolution Layer 1)有六个不同的5x5滤波器(Stride = 1)。由图可见,六个不同的滤波器产生了深度为6的特征映射。
Convolutional Layer 1 后面跟着Pooling Layer 1, 对六个特征映射分别进行2x2的最大池化(Stride = 2)。你可以在动态网页中的每个像素上活动鼠标指针,观察其在前一个卷积层里对应的4x4网格(如下图)。不难发现,每个4x4网格里的最亮的像素(对应最大值)构成了池化层。

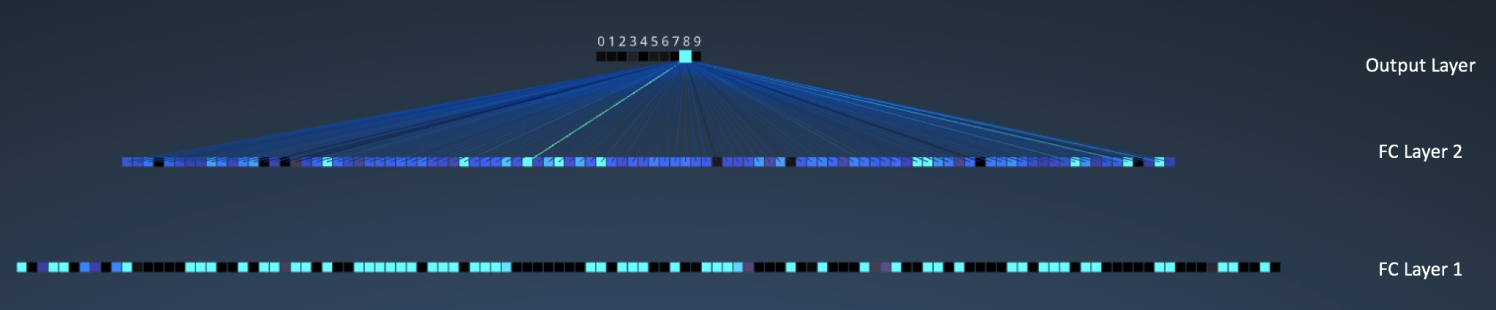
之后我们有三个全连接(FC)层:
- FC 1: 120神经元
- FC 2: 100神经元
- FC 3: 10神经元,对应10个数字——也即输出层
在下图,输出层10个节点中的每一个,都与第二个全连接层的100个节点相连(所以叫“全连接”)。
注意输出层里的唯一的亮点对应着8——这说明网络正确的识别了手写数字(越亮的节点代表越高的概率,比如这里8就拥有最高的概率)
可视化3D版本见这里
其他卷积网络架构
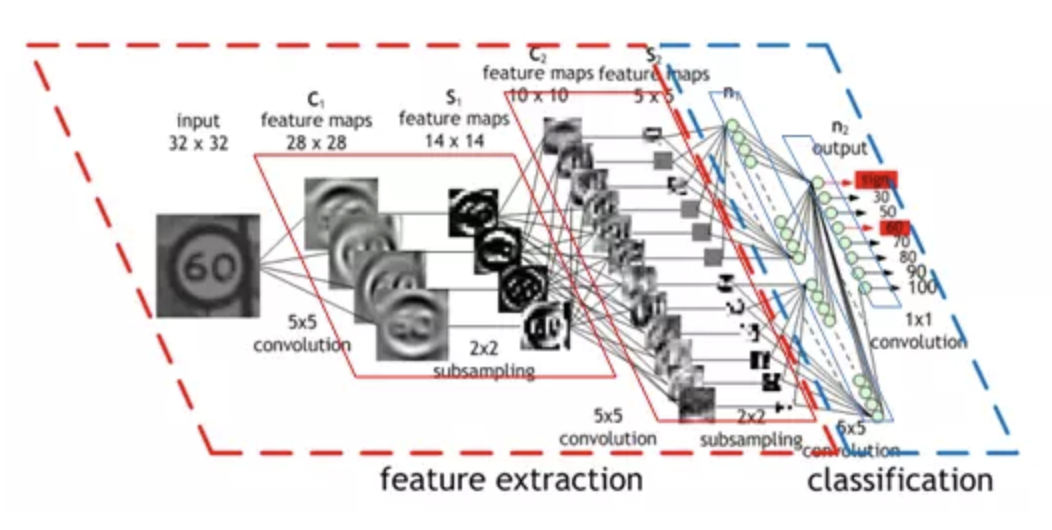
卷积神经网络始自1990年代起,我们已经认识了最早的LeNet,其他一些很有影响力的架构列举如下:
-
1990s至2012:从90年代到2010年代早期,卷积神经网络都处于孵化阶段。随着数据量增大和计算能力提高,卷积神经网络能搞定的问题也越来越有意思了。
-
AlexNet(2012):2012年,Alex Krizhevsky发布了AlexNet,是LeNet的更深、更宽版本,并且大比分赢得了当年的ImageNet大规模图像识别挑战赛(ILSVRC)。这是一次非常重要的大突破,现在普及的卷积神经网络应用都要感谢这一壮举。
-
ZF Net(2013):2013年的ILSVRC赢家是Matthew Zeiler和Rob Fergus的卷积网络,被称作ZF Net,这是调整过架构超参数的AlexNet改进型。
-
GoogleNet(2014):2014的ILSVRC胜者是来自Google的Szegedy et al.。其主要贡献是研发了Inception Module,它大幅减少了网络中的参数数量(四百万,相比AlexNet的六千万)。
-
VGGNet(2014):当年的ILSVRC亚军是VGGNet,突出贡献是展示了网络的深度(层次数量)是良好表现的关键因素。
-
ResNet(2015): Kaiming He研发的Residual Network是2015年的ILSVRC冠军,也代表了卷积神经网络的最高水平,同时还是实践的默认选择(2016年5月)。
-
DenseNet(2016年8月): 由Gao Huang发表,Densely Connected Convolutional Network的每一层都直接与其他各层前向连接。DenseNet已经在五个高难度的物体识别基础集上,显式出非凡的进步。
利用CNN识别MNIST手写字体
下面这部分主要是关于如何使用Keras实现CNN以及手写字体识别的应用

import numpy as np import pandas as pd import keras from keras.utils import np_utils (x_Train, y_Train),(x_Test,y_Test) = keras.datasets.mnist.load_data() # print('x_train_image:',x_Train.shape) # print('y_trian_image:', y_Train.shape) # print('x_test_image:',x_Test.shape) # print('y_test_image:', y_Test.shape) import matplotlib.pyplot as plt def plot_image(image): fig = plt.gcf() fig.set_size_inches(2,2) plt.imshow(image, cmap='binary') plt.show() plot_image(x_Train[2]) import matplotlib.pyplot as plt def plot_images_labels_prediction(images,labels, prediction,idx,num=10): fig = plt.gcf() fig.set_size_inches(12, 14) if num>25: num=25 for i in range(0, num): ax=plt.subplot(5,5, 1+i) ax.imshow(images[idx], cmap='binary') title= "label=" +str(labels[idx]) if len(prediction)>0: title+=",predict="+str(prediction[idx]) ax.set_title(title,fontsize=10) ax.set_xticks([]);ax.set_yticks([]) idx+=1 plt.show() plot_images_labels_prediction(x_Train,y_Train,[],0,10) # 多加一个颜色的维度 x_Train4D = x_Train.reshape(x_Train.shape[0],28,28,1).astype('float32') x_Test4D = x_Test.reshape(x_Test.shape[0],28,28,1).astype('float32') # 将数值缩放到0-1 x_Train4D_normalize = x_Train4D / 255 x_Test4D_normalize = x_Test4D / 255 # 把类别做onehot 编码 y_Train_onehot = np_utils.to_categorical(y_Train) y_Test_onehot = np_utils.to_categorical(y_Test) # CNN from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D model = Sequential() # filter为16,Kernel size 为(5,5),padding 为same model.add(Conv2D(filters=16, kernel_size = (5,5), padding = 'same', input_shape = (28,28,1), activation='relu')) # Maxpooling_size为(2,2) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Conv2D(filters=36, kernel_size=(5,5), padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Dropout(0.25)) # 平坦化 model.add(Flatten()) model.add(Dense(128,activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10,activation='softmax')) print(model.summary()) # 训练模型 model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy']) train_history=model.fit(x=x_Train4D_normalize, y=y_Train_onehot,validation_split=0.2, epochs=20, batch_size=300,verbose=2) import matplotlib.pyplot as plt def show_train_history(train_acc,test_acc): plt.plot(train_history.history[train_acc]) plt.plot(train_history.history[test_acc]) plt.title('Train History') plt.ylabel('Accuracy') plt.xlabel('Epoch') plt.legend(['train','test'], loc = 'upper left') plt.show() show_train_history('acc', 'val_acc') show_train_history('loss','val_loss') # 评估模型准确率 scores = model.evaluate(x_Test4D_normalize, y_Test_onehot) # 预测结果 prediction = model.predict_classes(x_Test4D_normalize) # 查看预测结果 def plot_image_labels_prediction(image,labels,prediction,idx,num=10): fig = plt.gcf() fig.set_size_inches(12,14) if num >25: num=25 for i in range(0,num): ax = plt.subplot(5,5,l+i) ax.imshow(image[idx], cmap='binary') ax.set_title("label=" + str(labels[idx])+ ",predict=" + str(prediction[idx]), fontsize =10) ax.set_xticks([]);ax.set_yticks([]) idx+=1 plt.show() plot_images_labels_prediction(x_Test,y_Test,prediction,idx=0) # 混淆矩阵 import pandas as pd pd.crosstab(y_Test, prediction, rownames=['label'], colnames=['predict'])
TensorFlow与Flask结合打造手写体数字识别
参考慕课网上的学习资料TensorFlow与Flask结合打造手写体数字识别
项目效果如下:
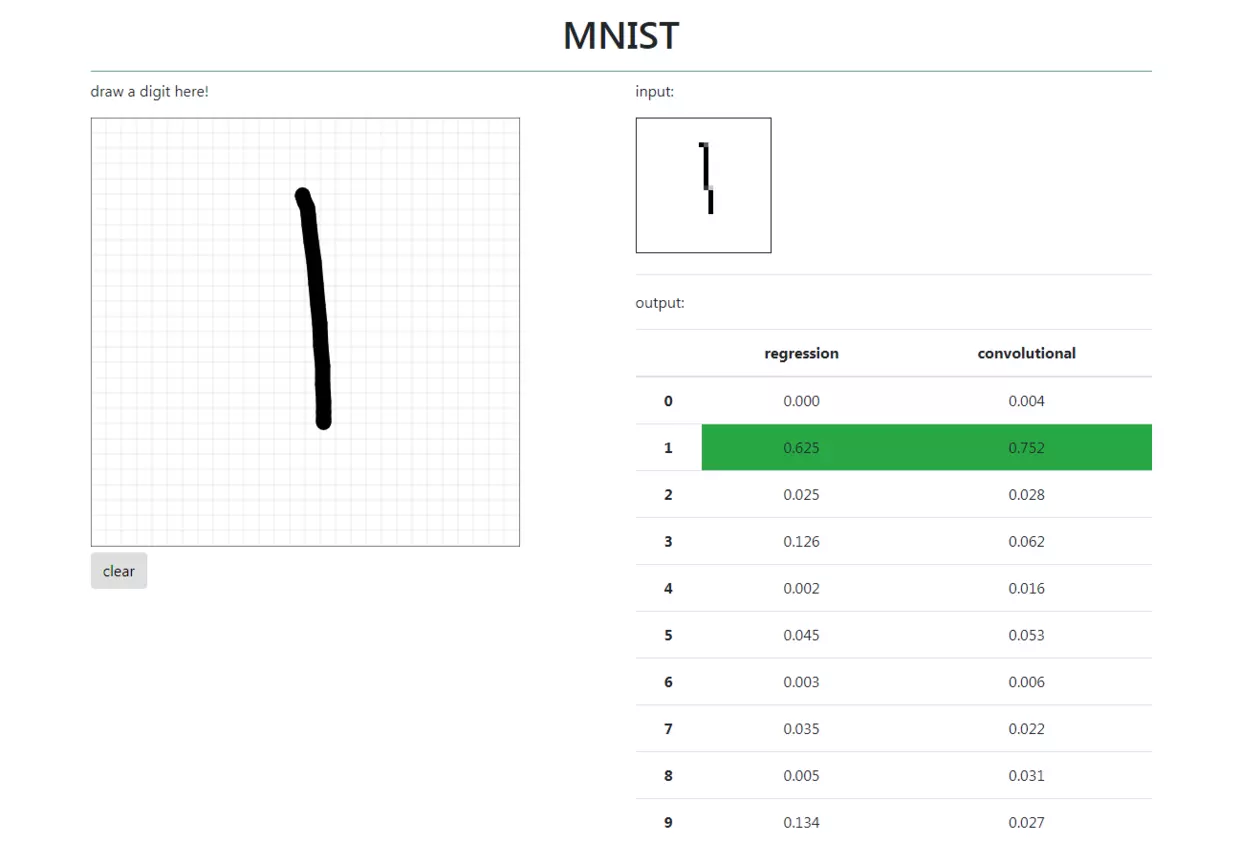
参考GitHub项目传送门--->TensorFlow-MNIST-WEBAPP
参考资料
- [資料分析&機器學習] 第5.1講: 卷積神經網絡介紹(Convolutional Neural Network)
- An Intuitive Explanation of Convolutional Neural Networks – the data science blog
- Convolutional Neural Network (CNN) | Skymind
- Convolutional Neural Networks (LeNet) — DeepLearning 0.1 documentation
- CS231n Convolutional Neural Networks for Visual Recognition
- 卷积神经网络(CNN)学习笔记1:基础入门 | Jey Zhang
- Deep Learning(深度学习)学习笔记整理系列之(七) - CSDN博客


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南