
Tensorflow学习笔记4: Object_detection之准备数据生成TFRecord
1、PASCAL VOC数据集
PASCAL Visual Object Classes 是一个图像物体识别竞赛,用来从真实世界的图像中识别特定对象物体,共包括 4 大类 20 小类物体的识别。其类别信息如下。 Person: person Animal: bird, cat, cow, dog, horse, sheep Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor

为了更加方便以及规范化,在research下面新建一个date文件夹用于存放各种数据集
# From tensorflow/models/research/ wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar tar -xvf VOCtrainval_11-May-2012.tar
python object_detection/dataset_tools/create_pascal_tf_record.py \ --label_map_path=object_detection/data/pascal_label_map.pbtxt \ --data_dir=date/VOCdevkit \ # 注意修改路径 --year=VOC2012 \ # 如果下载的是07的则选用07 --set=train \ --output_path=date/VOCdevkit/pascal_train.record# 注意修改路径
python object_detection/dataset_tools/create_pascal_tf_record.py \
--label_map_path=object_detection/data/pascal_label_map.pbtxt \
--data_dir=date/VOCdevkit \
--year=VOC2012 \
--set=val \
--output_path=date/VOCdevkit/pascal_val.record
正确姿势:

TF-record结果集

2、Oxford-IIIT Pet数据集
The Oxford-IIIT Pet Dataset是一个宠物图像数据集,包含37种宠物,每种宠物200张左右宠物图片,并同时包含宠物轮廓标注信息。

下载数据,转化为TF-record
wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
tar -xvf annotations.tar.gz
tar -xvf images.tar.gz
python object_detection/dataset_tools/create_pet_tf_record.py \
--label_map_path=object_detection/data/pet_label_map.pbtxt \
--data_dir=`pwd`/date/Oxford-IIIT \
--output_dir=`pwd`/date/Oxford-IIIT
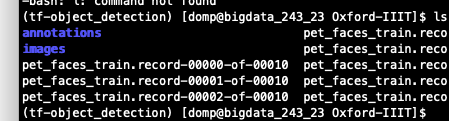
正确姿势:
TF-record结果集
3、训练自己数据集
准备图片和XML文件,xml文件可以用labelImg这个工具进行标注

3.1 按Oxford-IIIT Pet数据集形式生成
复制create_pet_tf_record.py并命名为create_pet_tf_record_sfz_hm.py
label_map_path=/data/zxx/models/research/date/sfz_fyj/sfz_hm_label_map.pbtxt
python object_detection/dataset_tools/create_pet_tf_record_sfz_hm.py \
--label_map_path=${label_map_path} \
--data_dir=`pwd`date/sfz_fyj \
--output_dir=`pwd`date/sfz_fyj
报错:tensorflow.python.framework.errors_impl.NotFoundError: /data/zxx/models/researchdate/sfz_fyj/annotations/trainval.txt; No such file or directory
查看了下sfz_fyj里面确实没有annotation 这个文件夹和annotations/trainval.txt,原因在于我们的数据文件格式未满足create_pet_tf_record_sfz_hm.py的要求
在annotations中除了xmls文件外,还有其余5个文件,

trimaps:数据集中每个图像的Trimap注释,像素注释:1:前景2:背景3:未分类
list.txt:Image CLASS-ID SPECIES BREED ID,类别ID:1-37类;动物种类ID:如猫,狗;BREED ID:1-25:猫1:12:狗
trainval.txt:文件描述了论文中使用的分裂,但是test.txt鼓励你尝试随机分割
所以上面是提供了两种素材分类的方式,一种是论文采用的,一种是自己随机分配
需要自己生成
参考1:http://androidkt.com/train-object-detection/
执行试了下,并不靠谱,弃用,不过还是保留在这,大神懂的,可以指点下下面代码是什么原理。
ls image | grep ".jpg" | sed s/.jpg// > annotations/trainval.txt
参考2:https://github.com/EddyGao/make_VOC2007/blob/master/


1 import os 2 import random 3 4 trainval_percent = 0.66 5 train_percent = 0.5 6 xmlfilepath = 'annotations/xmls' 7 txtsavepath = 'annotations' 8 total_xml = os.listdir(xmlfilepath) 9 10 num=len(total_xml) 11 list=range(num) 12 tv=int(num*trainval_percent) 13 tr=int(tv*train_percent) 14 trainval= random.sample(list,tv) 15 train=random.sample(trainval,tr) 16 17 ftrainval = open('annotations/trainval.txt', 'w') 18 ftest = open('annotations/test.txt', 'w') 19 ftrain = open('annotations/train.txt', 'w') 20 fval = open('annotations/val.txt', 'w') 21 22 for i in list: 23 name=total_xml[i][:-4]+'\n' 24 if i in trainval: 25 ftrainval.write(name) 26 if i in train: 27 ftrain.write(name) 28 else: 29 fval.write(name) 30 else: 31 ftest.write(name) 32 33 ftrainval.close() 34 ftrain.close() 35 fval.close() 36 ftest .close()
结果:

执行:
label_map_path=/data/zxx/models/research/date/sfz_fyj/sfz_hm_label_map.pbtxt
python object_detection/dataset_tools/create_pet_tf_record_sfz_hm.py \
--label_map_path=${label_map_path} \
--data_dir=`pwd`/date/sfz_fyj/ \
--output_dir=`pwd`/date/sfz_fyj/

3.2 按PASCAL数据集形式
参考:https://blog.csdn.net/Int93/article/details/79064428
三部曲:
import os import glob import pandas as pd import xml.etree.ElementTree as ET def xml_to_csv(path): xml_list = [] for xml_file in glob.glob(path + '/*.xml'): tree = ET.parse(xml_file) root = tree.getroot() for member in root.findall('object'): value = (root.find('filename').text, int(root.find('size')[0].text), int(root.find('size')[1].text), member[0].text, int(member[4][0].text), int(member[4][1].text), int(member[4][2].text), int(member[4][3].text) ) xml_list.append(value) column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax'] xml_df = pd.DataFrame(xml_list, columns=column_name) return xml_df def main(): image_path = os.path.join(os.getcwd(), 'path') xml_df = xml_to_csv(image_path) xml_df.to_csv('保存路径', index=None) print('Successfully converted xml to csv.') main()
#!/usr/bin/env python # coding: utf-8 # In[1]: import numpy as np import pandas as pd np.random.seed(1) # In[2]: full_labels = pd.read_csv('pg13_kg_0702/pg13_kg_labels.csv') # In[3]: # full_labels.head() # In[4]: # grouped = full_labels.groupby('filename') # In[5]: # grouped.apply(lambda x: len(x)).value_counts() # ### split each file into a group in a list # In[6]: gb = full_labels.groupby('filename') # In[7]: grouped_list = [gb.get_group(x) for x in gb.groups] # In[8]: # len(grouped_list) # In[9]: train_index = np.random.choice(len(grouped_list), size=3168, replace=False) test_index = np.setdiff1d(list(range(1357)), train_index) # In[10]: # len(train_index), len(test_index) # In[11]: # take first 200 files train = pd.concat([grouped_list[i] for i in train_index]) test = pd.concat([grouped_list[i] for i in test_index]) # In[12]: len(train), len(test) # In[13]: train.to_csv('pg13_kg_0702/pg13_kg_train_labels.csv', index=None) test.to_csv('pg13_kg_0702/pg13_kg_test_labels.csv', index=None) # In[ ]:
""" Usage: # From tensorflow/models/ # Create train data: python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=train.record # Create test data: python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=test.record """ from __future__ import division from __future__ import print_function from __future__ import absolute_import import os import io import pandas as pd import tensorflow as tf from PIL import Image from object_detection.utils import dataset_util from collections import namedtuple, OrderedDict flags = tf.app.flags flags.DEFINE_string('csv_input', '', 'Path to the CSV input') flags.DEFINE_string('output_path', '', 'Path to output TFRecord') flags.DEFINE_string('image_dir', 'images', 'Path to images') FLAGS = flags.FLAGS # TO-DO replace this with label map def class_text_to_int(row_label): if row_label == 'left': return 1 else: return 0 # None 修改为0 def split(df, group): data = namedtuple('data', ['filename', 'object']) gb = df.groupby(group) return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)] def create_tf_example(group, path): with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid: encoded_jpg = fid.read() encoded_jpg_io = io.BytesIO(encoded_jpg) image = Image.open(encoded_jpg_io) width, height = image.size filename = group.filename.encode('utf8') image_format = b'jpg' xmins = [] xmaxs = [] ymins = [] ymaxs = [] classes_text = [] classes = [] for index, row in group.object.iterrows(): xmins.append(row['xmin'] / width) xmaxs.append(row['xmax'] / width) ymins.append(row['ymin'] / height) ymaxs.append(row['ymax'] / height) classes_text.append(row['class'].encode('utf8')) classes.append(class_text_to_int(row['class'])) tf_example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': dataset_util.int64_feature(height), 'image/width': dataset_util.int64_feature(width), 'image/filename': dataset_util.bytes_feature(filename), 'image/source_id': dataset_util.bytes_feature(filename), 'image/encoded': dataset_util.bytes_feature(encoded_jpg), 'image/format': dataset_util.bytes_feature(image_format), 'image/object/bbox/xmin': dataset_util.float_list_feature(xmins), 'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs), 'image/object/bbox/ymin': dataset_util.float_list_feature(ymins), 'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs), 'image/object/class/text': dataset_util.bytes_list_feature(classes_text), 'image/object/class/label': dataset_util.int64_list_feature(classes), })) return tf_example def main(_): writer = tf.python_io.TFRecordWriter(FLAGS.output_path) path = os.path.join(FLAGS.image_dir) examples = pd.read_csv(FLAGS.csv_input) grouped = split(examples, 'filename') for group in grouped: tf_example = create_tf_example(group, path) writer.write(tf_example.SerializeToString()) writer.close() output_path = os.path.join(os.getcwd(), FLAGS.output_path) print('Successfully created the TFRecords: {}'.format(output_path)) if __name__ == '__main__': tf.app.run()

