
PLSA非对称模型与对称模型的EM推导
1.PLSA
概率潜在语义分析(Probabilistic Latent Semantic Analysis, PLSA)也称概率潜在语义索引(Probabilistic Latent Semantic Indexing, PLSI),是一种利用概率生成模型对文本集合进行话题(主题)分析的无监督学习。
PLSA有两种等价的模型,一个是非对称模型,另一个是对称模型(在李航的《统计学习方法》中称前者为生成模型,后者为共现模型)。
 |
 |
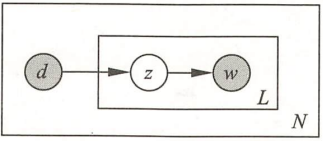
如上图所示,非对称模型描述生成文档的过程是:先根据概率\(P(d)\)选择一个文档\(d\),在\(文档d\)给定条件下依据条件概率\(P(z|d)\)选择一个主题\(z\),再在主题\(z\)给定条件下依据条件概率\(P(w|z)\)选择一个单词\(w\),重复(选择主题-选择单词)这个操作\(L\)次,将将生成的\(L\)个单词作为文档\(d\)的句子。重复\(N\)次以上过程,最终得到\(N\)个文档。
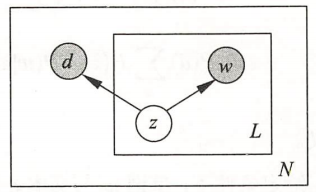
而对称模型描述生成文档的过程是:先根据概率\(P(z)\)选择一个主题\(z\),在主题\(z\)给定条件下根据条件概率\(P(d|z)\)和\(P(w|z)\)选择一个文档\(d\)和一个单词\(w\),重复选择单词\(L\)次,将生成的\(L\)个单词作为文档\(d\)的句子。重复\(N\)次以上过程,最终得到\(N\)个文档。
每个(单词-文档)对(w,d)的概率由以下公式决定:
\(\Large P(w,d) = P(d)\sum_{z}P(z|d)P(w|z)\)(非对称模型)
\(\Large P(w,d) = \sum_{z}P(z)P(d|z)P(w|z)\)(对称模型)
2.EM算法
EM(Expectation Maximization)算法是一种迭代算法,用于含有隐变量的概率模型参数的极大似然估计,或极大后验概率估计。
对于输入样本\(X\),对应的隐变量\(Z\),待估计的模型参数\(\theta\),EM算法通过迭代求\(L(\theta)=\log{P(X|\theta)}=\log\{\sum_{z}P(X,Z|\theta)\}\)的极大似然估计。每次迭代包含两步:E步,求期望;M步,求极大值。
EM算法迭代过程
(1)初始化:参数\(\theta^{old}\)随机初始化;
(2)E步:计算隐变量的后验概率\(P(Z|X,\theta^{old})\);
(3)M步:迭代参数\(\theta^{new}=\arg\max\limits_{\theta}{Q(\theta,\theta^{old})}\);
(4)重复(2)和(3),直到收敛。
其中,Q函数为显式变量\(X\),隐变量\(Z\)的对数联合分布在\(Z\)的后验分布下的期望,\(Q(\theta,\theta^{old})=\sum_{z}{P(Z|X,\theta^{old})\log{P(X,Z|\theta)}}\)。
3.PLSA的EM推导
假设文档个数为\(M\),主题个数为\(K\),单词词典大小为\(N\),则\(w_{i}\)表示第\(i\)个单词(\(i=1,2,...,M\)),\(z_{k}\)表示第\(k\)个主题(\(k=1,2,...,K\)),\(d_{j}\)表示第\(j\)篇文档(\(j=1,2,...,N\)),\(n(w_{i},d_{j})\)表示在第\(j\)个文档中出现第\(i\)个词的个数。
a. 非对称模型
\(\Large P(w,d) = P(d)\sum_{z}P(z|d)P(w|z)\)
对于\((w_{i},z,d_{j})\)这一对样本,有:
- 联合概率
\(P(w_{i},z_{k},d_{j}) = P(d_{j})P(z_{k}|d_{j})P(w_{i}|z_{k})\)
- 后验概率
\(P(z_{k}|w_{i},d_{j}) = \frac{P(d_{j})P(z_{k}|d_{j})P(w_{i}|z_{k})}{\sum^{K}_{k=1}{P(d_{j})P(z_{k}|d_{j})P(w_{i}|z_{k})}} = \frac{P(z_{k}|d_{j})P(w_{i}|z_{k})}{\sum^{K}_{k=1}{P(z_{k}|d_{j})P(w_{i}|z_{k})}}\)
- 一对样本的期望函数
\(\sum^{K}_{k=1}{P(z_{k}|w_{i},d_{j})\log{P(w_{i},z_{k},d_{j})}} = \sum^{K}_{k=1}{P(z_{k}|w_{i},d_{j})[\log{P(z_{k}|d_{j})P(w_{i}|z_{k})} + \log{P(d_{j})}]}\)
其中\(\log{P(d_{j})}\)是常数项,可将其去掉,故:
- 整体的期望函数
\(Q = \sum^{M}_{i=1}{\sum^{N}_{j=1}{n(w_{i},d_{j})\sum^{K}_{k=1}{P(z_{k}|w_{i},d_{j})[\log{P(z_{k}|d_{j})} + \log{P(w_{i}|z_{k})}]}}}\)
Q函数中有两组待优化参数:\(P(z_{k}|d_{j})\)和\(P(w_{i}|z_{k})\),满足
\(\sum^{M}_{i=1}{P(w_{i}|z_{k}) = 1}\) \(,k=1,2,...,K\)
\(\sum^{K}_{k=1}{P(z_{k}|d_{j}) = 1}\) \(,j=1,2,...,N\)
引入拉格朗日乘子\(\alpha_{k}\)和\(\beta_{j}\),定义拉格朗日函数\(\mathcal{L}\)
\(\mathcal{L} = Q + \sum^{K}_{k=1}{\alpha_{k}[1-\sum^{M}_{i=1}{P(w_{i}|z_{k})}]} + \sum^{N}_{j=1}{\beta_{j}[1-\sum^{K}_{k=1}{P(z_{k}|d_{j})}]}\)
分别对\(P(z_{k}|d_{j})\)和\(P(w_{i}|z_{k})\)求偏导,并令其为0,得
\(\sum^{N}_{j=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j}) - \alpha_{k}P(w_{i}|z_{k}) = 0}\) \(,i=1,2,...,M;\) \(k=1,2,...,K\) (1)
\(\sum^{M}_{i=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j}) - \beta_{j}P(z_{k}|d_{j}) = 0}\) \(,k=1,2,...,K;\) \(j=1,2,...,N\) (2)
对\(M\)个词累加,可得
\(\alpha_{k} = \sum^{M}_{i=1}{n(w_{i},d_{j})}\)
对\(K\)个主题方程求和,可得
\(\beta_{j} = \sum^{M}_{i=1}{\sum^{N}_{j=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}}\)
将\(\alpha_{k}\)和\(\beta_{j}\)回代公式(1)(2),得
\(\Large P(z_{k}|d_{j}) = \frac{\sum^{M}_{i=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}}{\sum^{M}_{i=1}{n(w_{i},d_{j})}}\)
\(\Large P(w_{i}|z_{k}) = \frac{\sum^{N}_{j=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}}{\sum^{M}_{i=1}{\sum^{N}_{j=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}}}\)
E步:计算后验概率\(P(z_{k}|w_{i},d_{j})\)。
M步:更新\(P(z_{k}|d_{j})\)和\(P(w_{i}|z_{k})\)。
b. 对称模型
\(\Large P(w,d) = \sum_{z}P(z)P(d|z)P(w|z)\)
对于\((w_{i},z,d_{j})\)这一对样本,有:
- 联合概率
\(P(w_{i},z_{k},d_{j}) = P(z_{k})P(d_{j}|z_{k})P(w_{i}|z_{k})\)
- 后验概率
\(P(z_{k}|w_{i},d_{j}) = \frac{P(z_{k})P(d_{j}|z_{k})P(w_{i}|z_{k})}{\sum^{K}_{k=1}{P(z_{k})P(d_{j}|z_{k})P(w_{i}|z_{k})}}\)
- 一对样本的期望函数
\(\sum^{K}_{k=1}{P(z_{k}|w_{i},d_{j})\log{P(w_{i},z_{k},d_{j})}} = \sum^{K}_{k=1}{P(z_{k}|w_{i},d_{j})[\log{P(z_{k})P(d_{j}|z_{k})P(w_{i}|z_{k})}]}\)
- 整体的期望函数
\(Q = \sum^{M}_{i=1}{\sum^{N}_{j=1}{n(w_{i},d_{j})\sum^{K}_{k=1}{P(z_{k}|w_{i},d_{j})[\log{P(z_{k})} + \log{P(d_{j}|z_{k})} + \log{P(w_{i}|z_{k})}]}}}\)
Q函数中有三组待优化参数:\(P(w_{i}|z_{k})\),\(P(d_{j}|z_{k})\)和\(P(z_{k})\),满足
\(\sum^{M}_{i=1}{P(w_{i}|z_{k}) = 1}\) \(,k=1,2,...,K\)
\(\sum^{N}_{j=1}{P(d_{j}|z_{k}) = 1}\) \(,k=1,2,...,K\)
\(\sum^{K}_{k=1}{P(z_{k}) = 1}\)
引入拉格朗日乘子\(\alpha_{k}\),\(\beta_{k}\)和\(\gamma\),定义拉格朗日函数\(\mathcal{L}\)
\(\mathcal{L} = Q + \sum^{K}_{k=1}{\alpha_{k}[1-\sum^{M}_{i=1}{P(w_{i}|z_{k})}]} + \sum^{K}_{k=1}{\beta_{k}[1-\sum^{N}_{j=1}{P(d_{j}|z_{k})}]} + \sum^{K}_{k=1}{\gamma [1-\sum^{K}_{k=1}{P(z_{k})}]}\)
分别对\(P(w_{i}|z_{k})\),\(P(d_{j}|z_{k})\)和\(P(z_{k})\)求偏导,并令其为0,得
\(\sum^{N}_{j=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j}) - \alpha_{k}P(w_{i}|z_{k}) = 0}\) \(,i=1,2,...,M;\) \(k=1,2,...,K\) (3)
\(\sum^{M}_{i=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j}) - \beta_{k}P(d_{j}|z_{k}) = 0}\) \(,j=1,2,...,N;\) \(k=1,2,...,K\) (4)
\(\sum^{M}_{i=1}{\sum^{N}_{j=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}}- \gamma P(z_{k}) = 0\) \(,k=1,2,...,K\) (5)
对\(M\)个词累加,可得
\(\alpha_{k} = \sum^{M}_{i=1}{\sum^{N}_{j=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}}\)
对\(N\)个文档累加,可得
\(\beta_{k} = \sum^{M}_{i=1}{\sum^{N}_{j=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}}\)
对\(K\)个主题方程求和,可得
\(\gamma = \sum^{M}_{i=1}{\sum^{N}_{j=1}{n(w_{i},d_{j})}}\)
将\(\alpha_{k}\),\(\beta_{k}\)和\(\gamma\)回代公式(3)(4)(5),得
\(\Large P(w_{i}|z_{k}) = \frac{\sum^{N}_{j=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}}{\sum^{M}_{i=1}{\sum^{N}_{j=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}}}\)
\(\Large P(d_{j}|z_{k}) = \frac{\sum^{M}_{i=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}}{\sum^{M}_{i=1}{\sum^{N}_{j=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}}}\)
\(\Large P(z_{k}) = \frac{\sum^{M}_{i=1}{\sum^{N}_{j=1}{n(w_{i},d_{j})P(z_{k}|w_{i},d_{j})}}}{\sum^{M}_{i=1}{\sum^{N}_{j=1}{n(w_{i},d_{j})}}}\)
E步:计算后验概率\(P(z_{k}|w_{i},d_{j})\)。
M步:更新\(P(w_{i}|z_{k})\),\(P(d_{j}|z_{k})\)和\(P(z_{k})\)。
4.参考资料
[1] 李航, 《统计学习方法 第二版》
[2] Hong, L., “A Tutorial on Probabilistic Latent Semantic Analysis”, arXiv e-prints, 2012.
[3] https://www.cnblogs.com/zjgtan/p/3887132.html
转载请注明原文地址:https://www.cnblogs.com/zheng-mx5265/p/16208979.html
