linux 主从复制和读写分离
企业中高并发时,为了追求性价比,MySQL必须采用主从复制和读写分离,这样可以提供性能和高可用。
目录
一、
主从复制实验
三、
读写分离实验
五、总结
一、
1 MySQL的复制类型
-
基于语句的复制(STATEMENT, MySQL默认类型)
-
基于行的复制(ROW)
-
混合类型的复制(MIXED)
2 MySQL主从复制的工作过程
1、master服务器高并发,形成大量事务
2、网络延迟
3、主从硬件设备导致 cpu主频、内存io、硬盘io
4、本来就不是同步复制、而是异步复制 从库优化Mysql参数。比如增大innodb_buffer_pool_size,让更多操作在Mysql内存中完成,减少磁盘操作。 从库使用高性能主机。包括cpu强悍、内存加大。避免使用虚拟云主机,使用物理主机,这样提升了i/o方面性。 从库使用SSD磁盘 网络优化,避免跨机房实现同步
问题解决方法
半同步复制- 解决数据丢失的问题
4.
Mysql应用场景
[root@master ~]# yum install ntp -y [root@master ~]# vim /etc/ntp.conf [root@master ~]# yum -y install ntpdate ntp #安装ntp软件 [root@master ~]# ntpdate ntp.aliyun.com #时间同步 [root@master ~]# vi /etc/ntp.conf #编辑配置文件 fudge 127.127.1.0 stratum 10 #设置本机的时间层级为10级,0级表示时间层级为0级,是向其他服务器提供时间同步源的意思,不要设置为0级 server 127.127.1.0 #设置本机为时间同步源



2. 开启NTP服务、关闭防火墙和增强性安全功能



2.开启ntp服务,关闭防火墙、增强性安全功能

3.时间同步master服务器


3.MySQL手工编译安装(这里忽略)
2.重启服务

4.从服务器配置
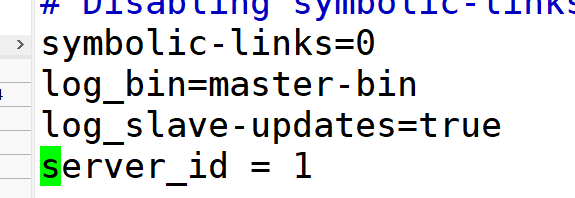
#开启二进制日志文件
#设置server id为22,slave2 为23
#从主服务器上同步日志文件记录到本地
#定义relay-log的位置和名称(index索引)


开启从服务器功能

进入MySQL
开启从服务器功能

查看表状态
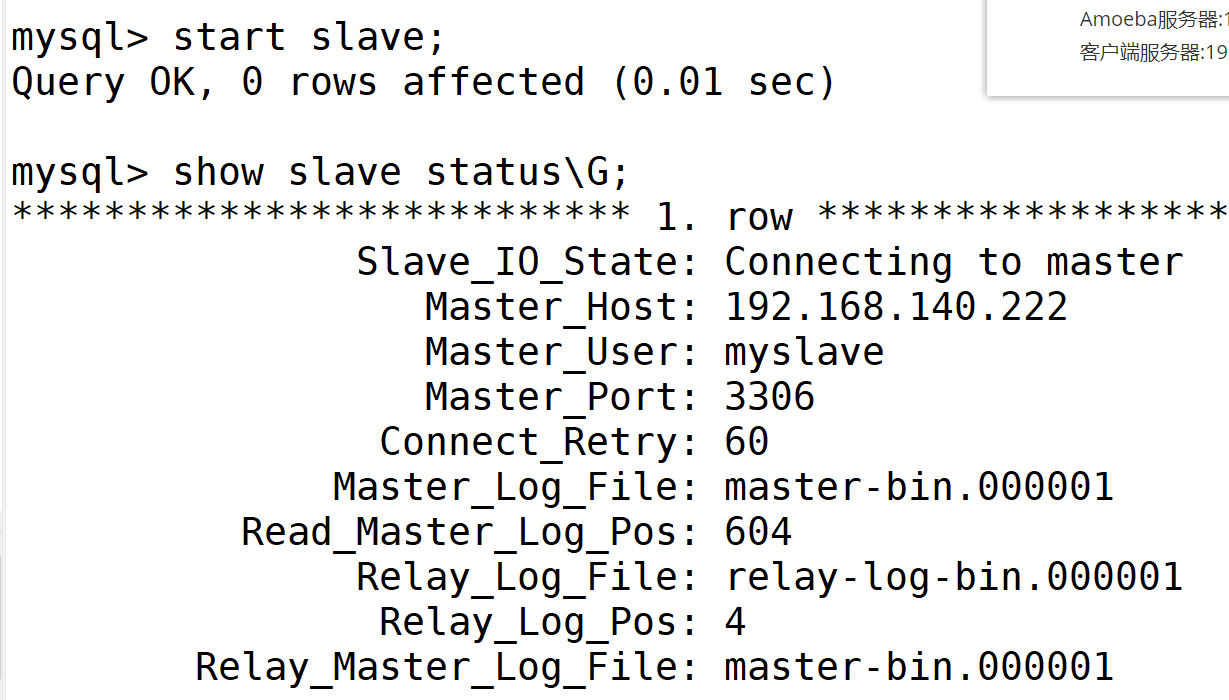
5.测试数据同步
在主服务器上创建一个数据库

在两台从服务器上直接查看数据库列表
第一台从服务器

第二台服务器

三、
1.读写分离概念
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
2.读写分离原因
企业 使用MySQL 读写分离场景
读写分离原理
读写分离就是只在主服务器上写,只在从服务器上读。基本的原理是让主数据库处理事务性操作,而从数据库处理 select 查询。数据库复制被用来把主数据库上事务性操作导致的变更同步到集群中的从数据库。
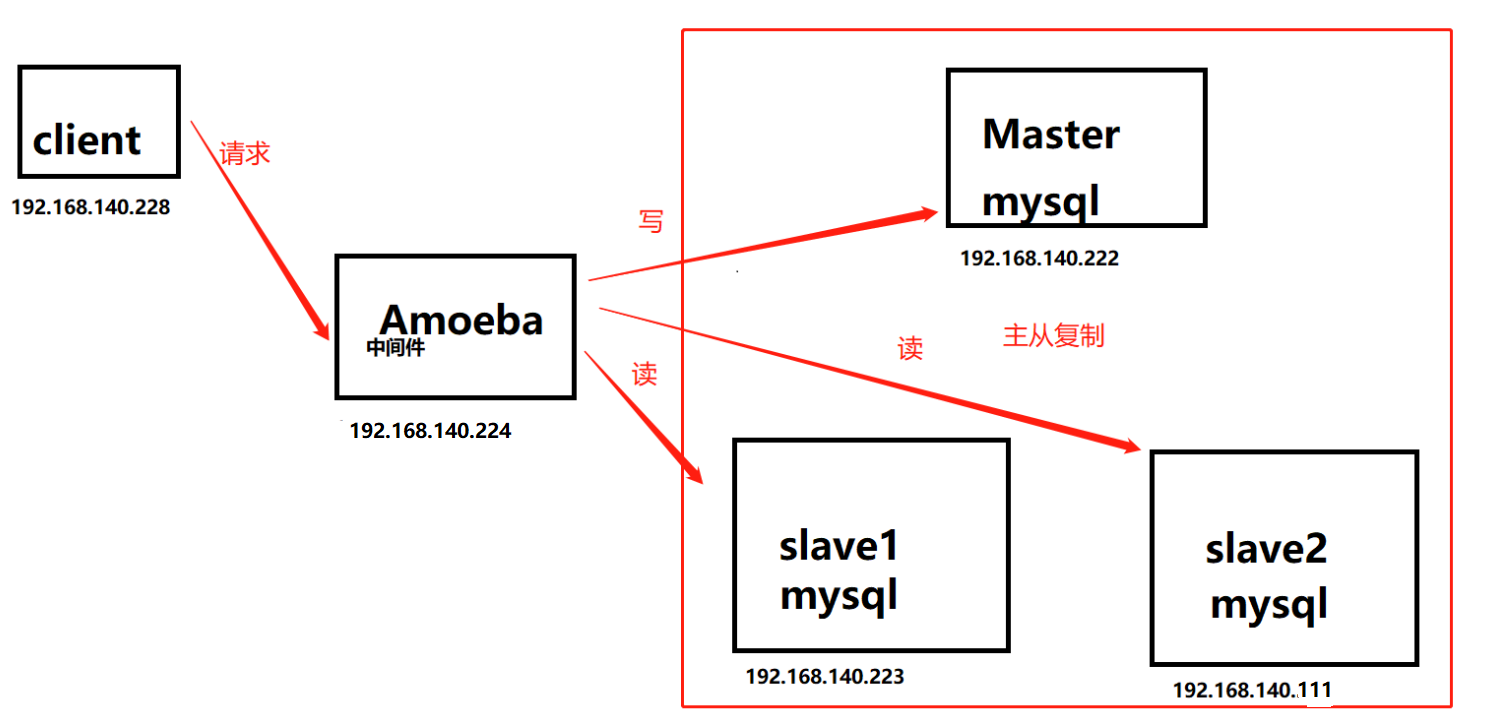
Amoeba服务器配置
1.安装 Java 环境
因为 Amoeba 基于是 jdk1.5 开发的,所以官方推荐使用 jdk1.5 或 1.6 版本,高版本不建议使用。
修改配置环境


查看java版本

安装 Amoeba软件

解压文件
//如显示amoeba start|stop说明安装成功

配置 Amoeba读写分离,两个 Slave 读负载均衡
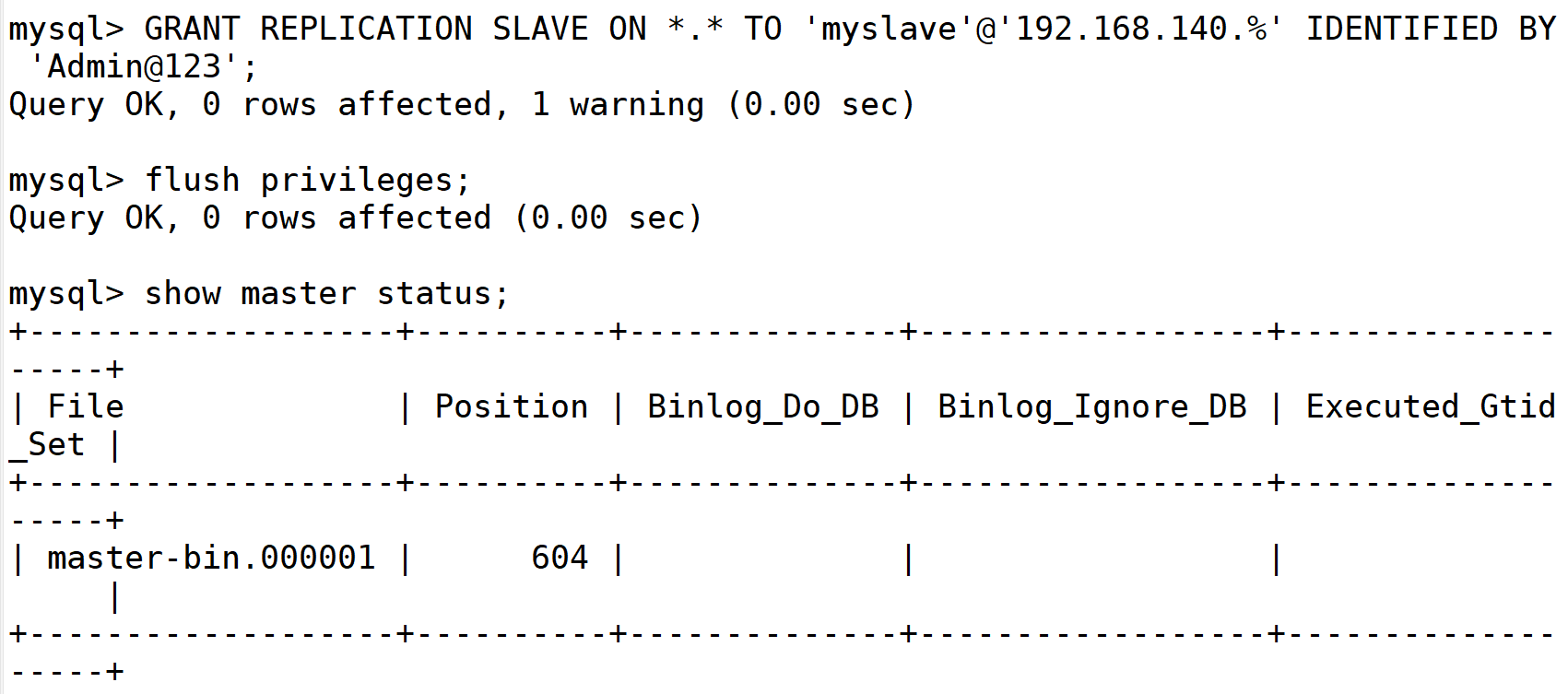
#先在Master、Slave1、Slave2 的mysql上开放权限给 Amoeba 访问

再回到amoeba服务器配置amoeba服务:
#修改amoeba配置文件



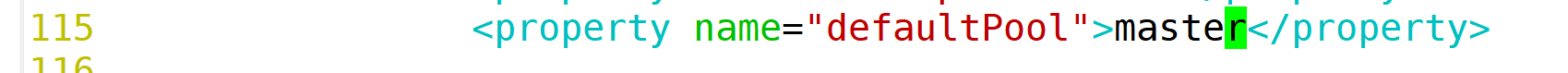

#修改数据库配置文件
取消注释

取消注释,添加密码


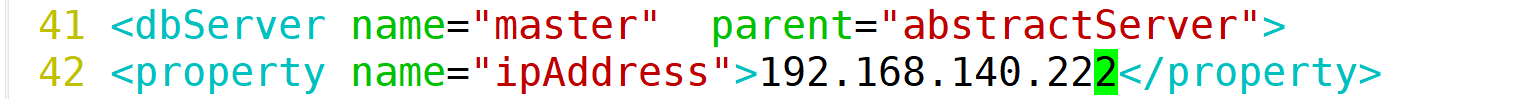


#启动Amoeba软件,按ctrl+c 返回

#查看8066端口是否开启,默认端口为TCP 8066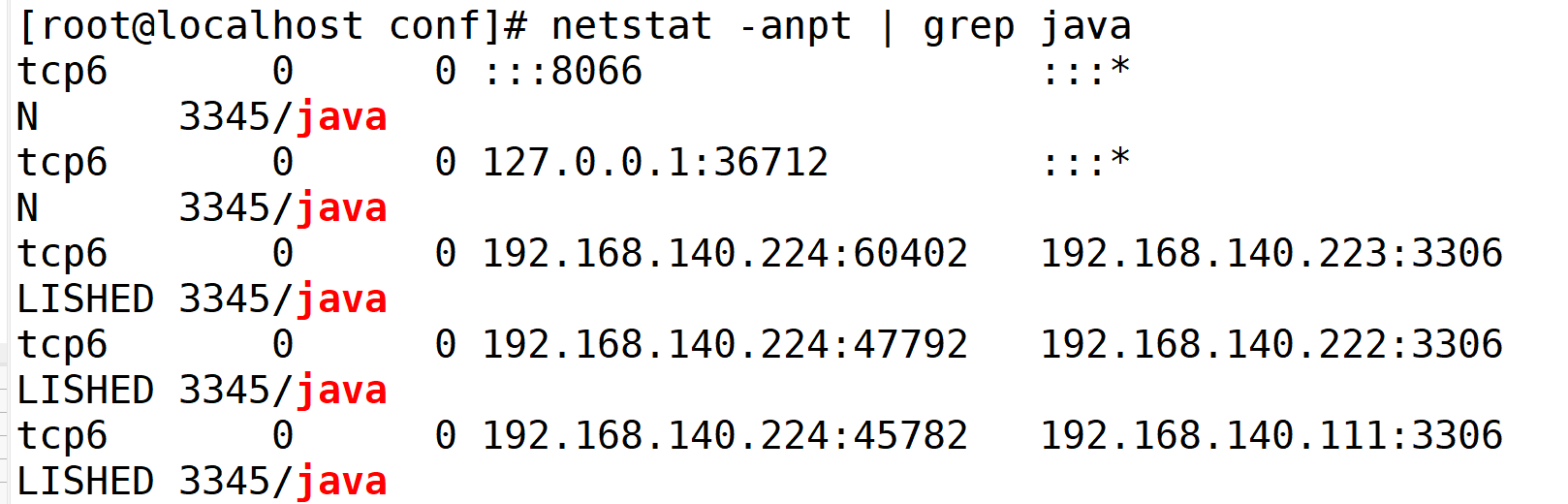
测试读写分离
#先安装数据库
通过amoeba服务器代理访问mysql ,在通过客户端连接mysql后写入的数据只有主服务会记录,然后同步给从--从服务器
为了看到读写分离,需要先关闭主从复制。

插入数据
//在slave1上:
insert into test values('1','zhangsan','this_is_slave1');
//在slave2上:
insert into test values('2','lisi','this_is_slave2');
//在主服务器上:
insert into test values('3','wangwu','this_is_master');
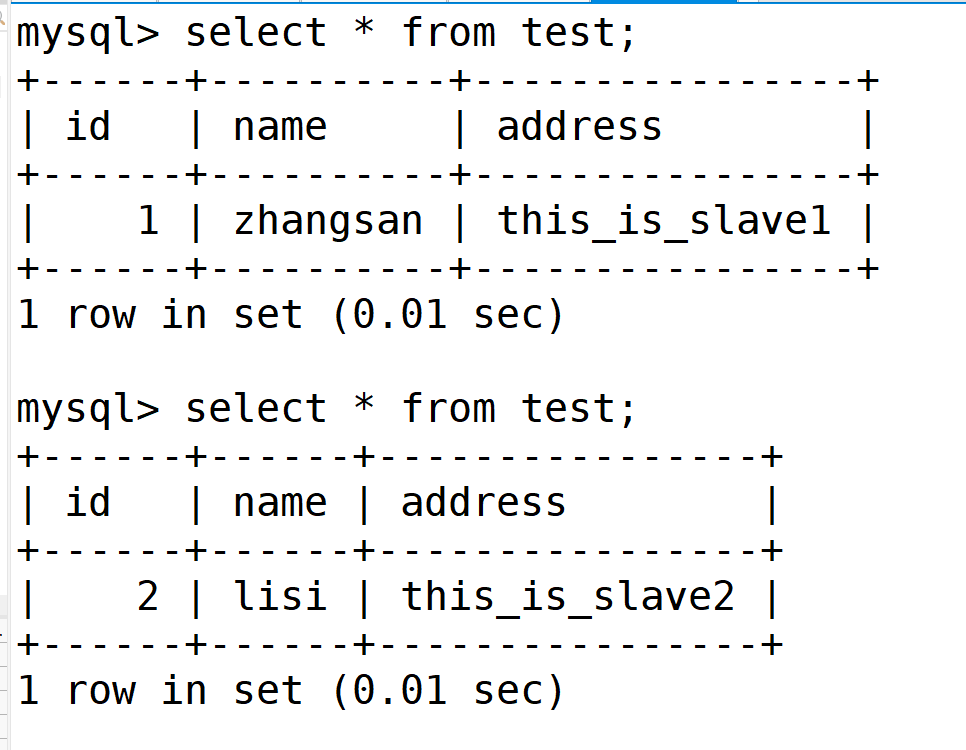
在客户端服务器上
可以看到读到的是从服务器的内容
在客户端插入数据
insert into test values('4','qianqi','this_is_client');
slave1看不到
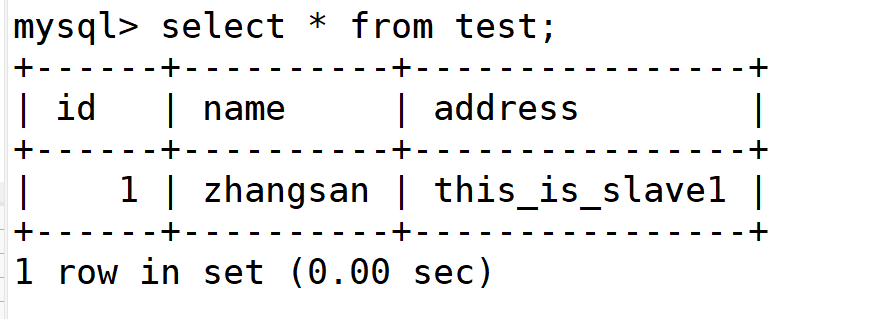
slave2也看不到
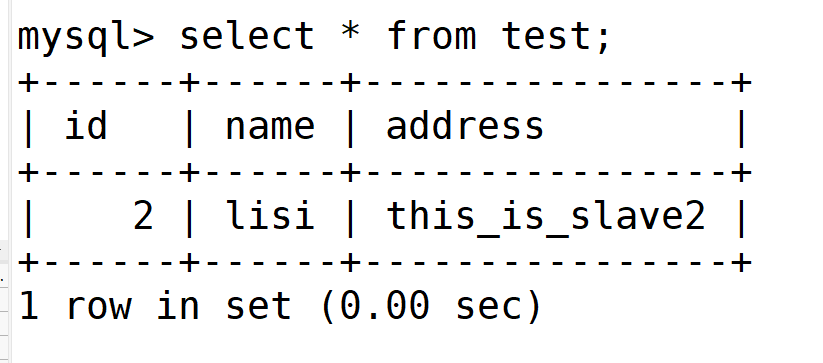
在master可以看到
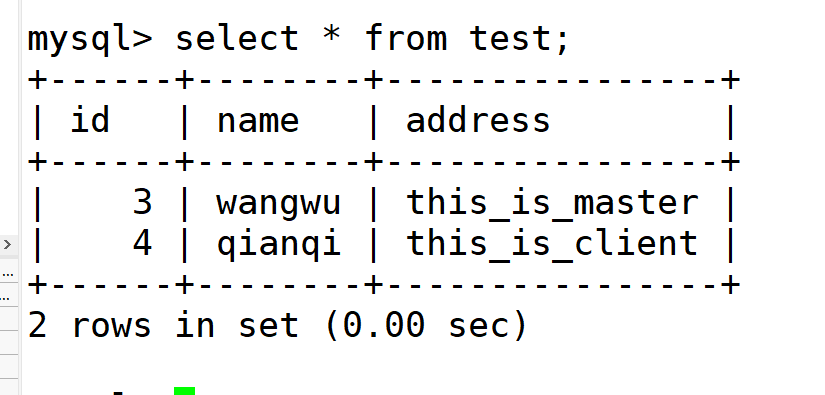
至此读写分离完成
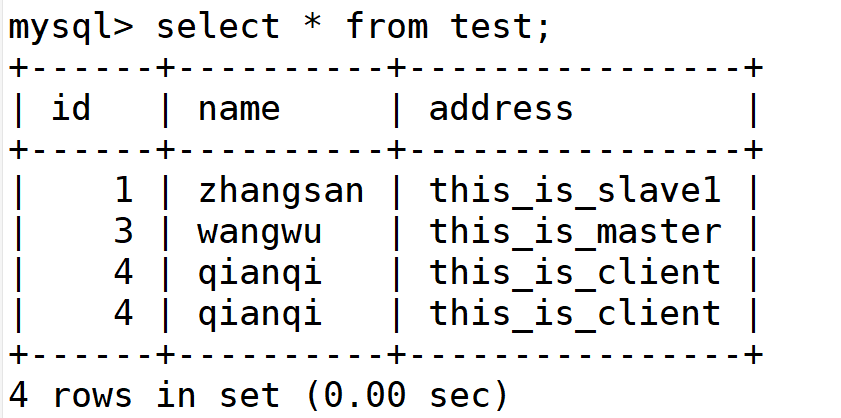
//在两个从服务器上执行 start slave; 即可实现同步在主服务器上添加的数据 start slave;
可以看到数据同步,至此实实现主从复制和读写分离
2.mycat搭建读写分离
1.配置安装Java环境
# vim /etc/profile export JAVA_HOME=/usr/local/java/jdk1.8.0_191 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib/rt.jar export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin # source /etc/profile # java -version
2.下载并解压Mycat
官网:Mycat1.

3.移动到/usr/local下并改名为mycat

4.创建用户并且加入组

5.配置Mycat环境变量

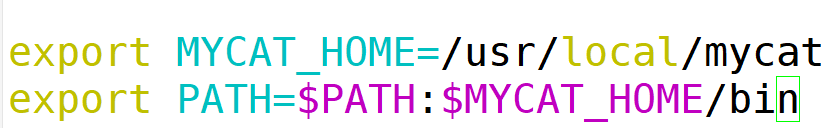
6.配置Mycat读写分离信息



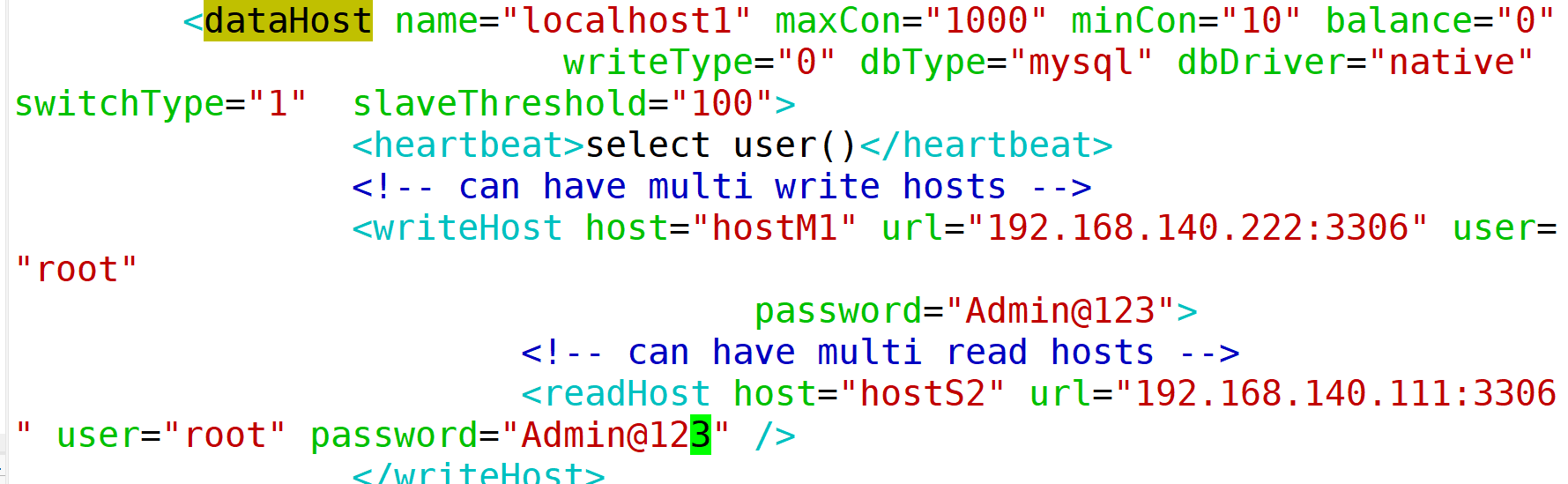
五、总结
读写分离是一种常见的数据库优化技术,它的核心思想是将数据库的读操作和写操作分别分配给不同的服务器处理,从而提高系统的性能和可靠性。通过读写分离,可以将读请求分散到多个从库上进行并发处理,从而缓解主库的负载压力,提高系统的读取速度和并发能力。同时,由于写操作只在主库上进行,可以保证数据的一致性和完整性,避免了因多个从库的并发写操作而引发的数据冲突和损坏。读写分离还可以提高系统的容错能力,当主库发生故障时,可以快速切换到从库进行读写操作,避免系统的宕机和数据丢失。总之,读写分离是一种非常有效的数据库优化技术,可以提高系统的性能、可靠性和容错能力,是现代大型网站和应用的基础架构之一。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号