
梯度下降法解线性回归
梯度下降法解线性回归
回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。按照涉及的自变量的多少,可分为一元回归分析和多元回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。
假设现在的目标是开餐馆选址,自变量x是当地人口,因变量y是选址此处所获利润。拟合直线为 hθ(x)=θ0+θ1∗xhθ(x)=θ0+θ1∗x,我们用梯度下降法来确定θ。
代价函数(cost function)
我们的目标是找到合适的θ,让确定的直线与样本数据之间的差距最小,这个差距用代价函数来衡量。对第 i 个样本x(i)x(i),我们将代价定为估计值hθ(x(i))hθ(x(i))与实际值y(i)y(i)的差的平方(似乎定为点到直线的距离更好一点,后话)。假设我们的样本数为m个,于是代价函数为:
J(θ)=12m∑mi=1(hθ(x(i))−y(i))2J(θ)=12m∑i=1m(hθ(x(i))−y(i))2
其中1/2是为了接下来求导时消去常数项。需要注意的是,这里的自变量是θ而非x,可以看做x是已知的常数。
将θ看做二维平面坐标,J看做第三维的值。将J展开后,θ的每一维最高都是二次幂,也即从每个切面看,J(θ)都是一条抛物线,所以J构成的平面将会成为一个类似碗的形状,存在全局最小值(只是说线性回归这个问题有全局最小值,对其他类型的问题,可能存在许多局部最小值)。
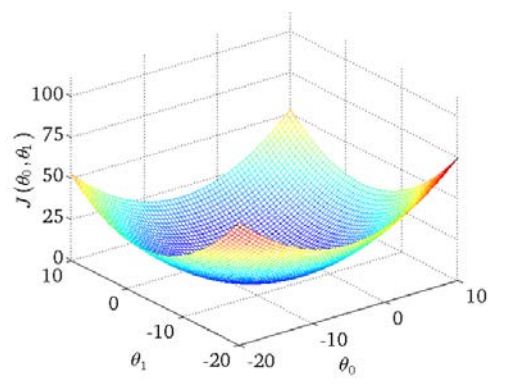
梯度下降(gradient descent)
从J的三维图中可以看出,假如θj偏大,那么J对θj的偏导数就为正,反之为负。我们利用这个特性来估计θ参数。对J求θ0与θ1的偏导数,再设置一个合适的学习率α对θ进行迭代,从而近似出最终的θ:
θj:=θj−α∗∂J(θ)∂θjθj:=θj−α∗∂J(θ)∂θj
展开得到:
θj:=θj−αm∑mi=1(hθ(x(i))−y(i))x(i)jθj:=θj−αm∑i=1m(hθ(x(i))−y(i))xj(i)
当接近最低点时,对应的偏导数绝对值也会变小,降低了θ的收敛速度,因此学习率α在迭代过程中不需要调整,不必担心矫枉过正。
注意,θ0与θ1需要同步更新,就是说求出新的θ0之后,得用原先的θ0更新θ1,而不能用更新之后的值带入求θ1,否则参数有偏,就不是同步更新了。
多维特征(multiple variable)
假如影响餐馆理论的自变量有好几个,我们仍能使用梯度下降法来拟合直线: hθ(x)=θ0∗x0+θ1∗x1+...+θn∗xnhθ(x)=θ0∗x0+θ1∗x1+...+θn∗xn
有一个小技巧,coding时常常将x0x0设为1,从而对θ0的的处理与对其他θj的处理相同。但是x0x0不需要进行特征缩放(因为他就是1)。
多项式回归(Polynomial Regression)
注意一个小技巧,当我们要拟合的不是关于x的直线,而是比如x的二次项,我们可以令x1=x20x1=x02来“骗过”梯度下降法,求出二次项的参数。这个时候需要对自变量进行特征缩放,否则收敛比较慢(假如x范围是0~10,那么x平方范围就是0~100,二者范围差距太大)。
特征缩放(feature scaling)
假如两个自变量中,一个的范围是0~5,另一个是0~50000,那么J的形状会非常扁,就像一道狭长的地缝,迭代的过程变得像在缝的两边来回跳(因为梯度方向离最低点的夹角很大,更像是指向缝的另一边),需要迭代许多次才能跳到最深处。特征缩放的目的是让J的形状更“圆”一些,从而迭代的次数可以少一点。一般特征缩放的方法是将 自变量x 减去其平均值μ, 再除以一个值,这个值可以是max-min,也可以是标准差(如果是标准差,那么缩放后的样本标准差就为1)。again,x0x0不需要进行特征缩放(因为他就是1)。
需要注意,拿特征缩放求出来的参数,来估计新的自变量对应的值时,新的自变量也要先进行特征缩放(假如新来的自变量把平均值挪得特别远怎么办?(那么用这个样本来估计就不合适了))。
学习率
学习率α 如果设置得太小,那么会收敛得很慢;如果设置得太大,那么可能不收敛,反而发散(步子迈太大,直接超过最低点了,过头之后算偏导数更大了,往回走还是超过最低点,导致在离最低点有一段距离的地方不断来回溜达)。可以在每次迭代之后,算出对应的代价函数值,看看代价函数值是不是走向收敛的路上。
学习率α 的调整可以设为0.01,0.03,0.1,0.3,1,3这样上去。
正规方程(normal equation)
除了梯度下降法,还有一种神奇的方法可以直接求出参数θ,而且求出来的还是精确值,但是求的过程中有一步是矩阵求逆,成为了这个方法的死穴。方法是:
θ=(XT∗X)−1∗XT∗yθ=(XT∗X)−1∗XT∗y
需要求一个 n*n 大小的矩阵的逆:
- 复杂度是O(n3),这里 n 是“特征的个数”,如果特征个数太多的话,这个方法就不实际了。
- 假如特征之间不独立(例如拿x与x^2同时作为特征,比如说房子的长和房子的面积很可能就是不独立的),那么逆矩阵将不存在,这个方法也就没法用了(matlab中可以用pinv求pseudo inverse来部分避免这个问题)。
排除以上两点的话,正规方程还是比梯度下降法方便许多的。正规方程的背景见线性代数学习笔记(五)。
matlab代码
输入是ex1data2.txt文件,前两列是自变量,最后一列是因变量,用逗号分隔,格式类似于:
2104,3,399900
1600,3,329900
……
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
%% Load Datadata = load('ex1data2.txt');X = data(:, 1:2);y = data(:, 3);m = length(y);%% ================ Part 1: Feature Normalization ================% Scale features and set them to zero meanmu = mean(X, 1);sigma = std(X);for i = 1:size(X,1) for j = 1:size(X,2) X(i, j) = ( X(i, j)-mu(1, j) ) / sigma(1, j); end;end;% Add intercept term to XX = [ones(m, 1) X];%% ================ Part 2: Gradient Descent ================% Choose some alpha valuealpha = 0.01;num_iters = 400;% Init Theta and Run Gradient Descenttheta = zeros(3, 1);for iter = 1:num_iters theta = theta - alpha / m * ( (X * theta - y)' * X )' ;% Estimate the price of a 1650 sq-ft, 3 br houseprice = [ 1, (1650-mu(1))/sigma(1), (3-mu(2))/sigma(2)] * theta;%% ================ Part 3: Normal Equations ================%% Load Datadata = csvread('ex1data2.txt');X = data(:, 1:2);y = data(:, 3);m = length(y);% Add intercept term to XX = [ones(m, 1) X];% Calculate the parameters from the normal equationtheta = pinv(X' * X) * X' * y;% Estimate the price of a 1650 sq-ft, 3 br houseprice = [1 1650 3] * theta; |
(代码类型没有matlab,注释没法高亮了。。凑合着看吧)
随机梯度下降(Stochastic Gradient Descent)
(2014年7月13日补充)

上述常规方法中,θ的更新需要累计所有样本的 估计值h 与 实际值y 的差值,这样假如 样本个数m 非常大的时候,我们需要等待所有样本都载入完毕,才能更新一次参数θ,速度实在太慢了。
随机梯度下降 一定程度上弥补了这个问题。其方法是:载入一个样本,更新θ的值,载入下一个样本,更新θ的值,以此类推。这种方法优点是更新速度快,缺点是虽然大体上是朝着最优目标前进的,但是一路上都在来回移动,如右图所示。

