
Caffeine
Caffeine 是java中的高性能本地缓存,提供了丰富的缓存功能。Caffeine 的目标是提供一个高吞吐量、低延迟、并发友好的缓存实现。
特点
- 高性能:Caffeine 是基于内存的本地缓存,访问速度非常快,并且在高并发环境下表现优秀。
- 低延迟:由于数据直接存储在应用程序的本地内存中,访问延迟几乎为零。
- 近乎零GC开销:设计上非常高效,垃圾回收(GC)开销非常小。
- 配置灵活:支持多种缓存失效策略,如基于时间的过期、基于容量的过期等。
- 易用性:简单易用的API,非常适合在Java应用程序中快速集成。
缓存策略配置
Caffeine 提供了多种缓存策略和配置选项,可以灵活地满足各种需求:
- 缓存过期策略:写入后过期expireAfterWrite、访问后过期expireAfterAccess
- 容量配置
- 自定义缓存加载:同步加载、异步加载
- 统计信息:监控缓存的使用情况和性能指标
使用
<dependency> <groupId>com.github.ben-manes.caffeine</groupId> <artifactId>caffeine</artifactId> <version>3.0.4</version> <!-- 请根据实际需要选择版本 --> </dependency>
private static Cache<String, String> localCache = Caffeine.newBuilder() .initialCapacity(5000) .maximumSize(100000) .expireAfterWrite(60, TimeUnit.SECONDS) .softValues() .build();
Caffeine和Redis对比
|
Redis |
Caffeine | |
|---|---|---|
|
概述 |
|
|
|
优点 |
|
|
|
缺点 |
|
|
|
使用场景 |
|
|
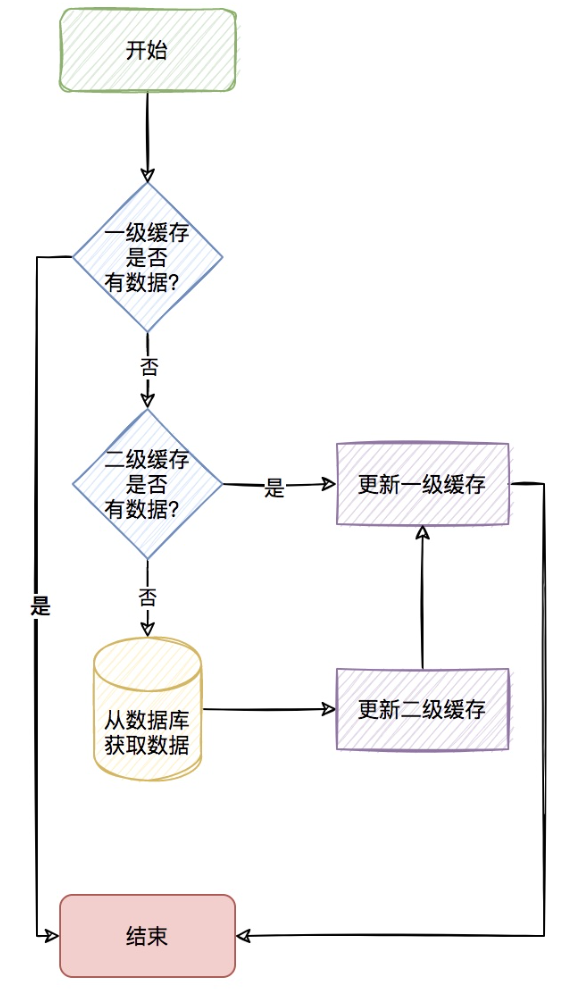
二级缓存:
一般将两者Caffeine和Redis结合起来,形成一二级缓存。使用流程大致如下:
- 1.一级缓存:先去本地缓存caffeine中查找数据(本地)
- 2.二级缓存:如果没有的话,去redis中查找数据(远程)
- 3.数据库:都没有,再去数据库中查找数据(磁盘)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?