

一、自己经历过的面试题碎片化整理
1.什么是事务、事务特性、事务隔离级别、spring事务传播特性
a.什么是事务:
事务是程序中一系列严密的操作,所有操作执行必须成功完成,否则在每个操作所做的更改将会被撤销,这也是事务的原子性(要么成功,要么失败)。
b.事务的四大特性:
1.原子性(Atomicity):一个事务中所有对数据库的操作是一个不可分割的操作序列,要么全做要么全不做
2.一致性(Consistency):数据不会因为事务的执行而遭到破坏
3.隔离性(Isolation):一个事务的执行,不受其他事务的干扰,即并发执行的事务之间互不干扰
4.持久性(Durability):一个事务一旦提交,它对数据库的改变就是永久的
参考链接:https://www.cnblogs.com/zhangqian1031/p/6542037.html
https://www.cnblogs.com/think-in-java/p/7763443.html
http://blog.csdn.net/a19881029/article/details/7893622
2.简述hibernate的一级缓存?
Hibernate中缓存分为:一级缓存、二级缓存
第一级别的缓存是 Session 级别的缓存,它是属于事务范围的缓存。这一级别的缓存由 hibernate 管理的
第二级别的缓存是 SessionFactory 级别的缓存,它是属于进程范围的缓存
A.为什么要用缓存?
目的:减少对数据库的访问次数!从而提升hibernate的执行效率!
B.概念
1)Hibenate中一级缓存,也叫做session的缓存,它可以在session范围内减少数据库的访问次数! 只在session范围有效! Session关闭,一级缓存失效!
2)当调用session的save/saveOrUpdate/get/load/list/iterator方法的时候,都会把对象放入session的缓存中。
3)Session的缓存由hibernate维护,用户不能操作缓存内容; 如果想操作缓存内容,必须通过hibernate提供的evict/clear方法操作。
C.特点
只在(当前)session范围有效,作用时间短,效果不是特别明显!
在短时间内多次操作数据库,效果比较明显!
a.缓存相关几个方法的作用:
session.flush(); 让一级缓存与数据库同步
session.evict(arg0); 清空一级缓存中指定的对象
session.clear(); 清空一级缓存中缓存的所有对象
b.批量操作怎样使用上面方法?
Session.flush(); // 先与数据库同步
Session.clear(); // 再清空一级缓存内容
c.不同的session是否会共享缓存数据?
不会 。不同的session使用不同的缓存区,不能共享。
参考链接:详解Hibernate中的一级缓存
hibernate笔记--缓存机制之 一级缓存(session缓存)(这篇文章比较容易理解)
3.hibernate的二级缓存?
二级缓存是属于SessionFactory级别的缓存机制。第一级别的缓存是Session级别的缓存,是属于事务范围的缓存,由Hibernate管理,一般无需进行干预。第二级别的缓存是SessionFactory级别的缓存,是属于进程范围的缓存。
参考链接:详解Hibernate中的二级缓存
4.spring都有哪些注解?
@Configuration把一个类作为一个IoC容器,它的某个方法头上如果注册了@Bean,就会作为这个Spring容器中的Bean。
@Scope注解 作用域
@Lazy(true) 表示延迟初始化
@Service用于标注业务层组件、
@Controller用于标注控制层组件(如struts中的action)
@Repository用于标注数据访问组件,即DAO组件。
@Component泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
@Scope用于指定scope作用域的(用在类上)
@PostConstruct用于指定初始化方法(用在方法上)
@PreDestory用于指定销毁方法(用在方法上)
@DependsOn:定义Bean初始化及销毁时的顺序
@Primary:自动装配时当出现多个Bean候选者时,被注解为@Primary的Bean将作为首选者,否则将抛出异常
@Autowired 默认按类型装配,如果我们想使用按名称装配,可以结合@Qualifier注解一起使用。如下:
@Autowired @Qualifier("personDaoBean") 存在多个实例配合使用
@Resource默认按名称装配,当找不到与名称匹配的bean才会按类型装配。
@PostConstruct 初始化注解
@PreDestroy 摧毁注解 默认 单例 启动就加载
@Async异步方法调用
5.jsp的九个内置对象及其作用?
答:request--请求对象
response--响应对象
page--页面对象
pageContext--页面上下文对象
session--会话对象
application--应用程序对象
out--输出对象
config--配置对象
exception--例外对象
参考链接:jsp内置对象(百度百科)
6.Query的两个方法,list()和iterate(),两个方法都是把结果集列出来,他们有3点不一样
1.返回的类型不一样。list()返回List,iterate()返回Iterator,
2.获取数据的方式不一样。
a.list()会直接查数据库,iterate()会先到数据库中把id都取出来,然后真正要遍历某个对象的时候先到缓存中找,如果找不到,以id为条件再发一条sql到数据库,这样如果缓存中没有数据,则查询数据库的次数为n+1。因此:对于list()方式的查询通常只会执行一个SQL语句,而对于iterator()方法的查询则可能需要执行N+1条SQL语句(N为结果集中的记录数).
b.list()方法无法利用一级缓存和二级缓存(对缓存只写不读),它只能在开启查询缓存的前提下使用查询缓存;
iterate()方法可以充分利用缓存,如果目标数据只读或者读取频繁,使用 iterate()方法可以减少性能开销。
c.list()中返回的List中每个对象都是原本的对象,iterate()中返回的对象是代理对象.(debug可以发现)
3.结果集的处理方法不同:
list()方法会一次取出所有的结果集对象,而且他会依据查询的结果初始化所有的结果集对象。如果在结果集非常庞大的时候会占据非常多的内存,甚至会造成内存溢出的情况发生。
iterator()方法在执行时不会一次初始化所有的对象,而是根据对结果集的访问情况来初始化对象。一次在访问中可以控制缓存中对象的数量,以避免占用过多的缓存,导致内存溢出情况的发生。
总结:
list()方法在执行时,直接运行查询结果所需要的查询语句。
iterator()方法则是先执行得到对象ID的查询,然后在根据每个ID值去取得所要查询的对象。
7.过滤器和拦截器的区别:
Filter也称之为过滤器,它是Servlet技术中最实用的技术,Web开发人员通过Filter技术,对web服务器管理的所有web资源:例如Jsp,Servlet, 静态图片文件或静态 html 文件等进行拦截,从而实现一些特殊的功能。例如实现URL级别的权限访问控制、过滤敏感词汇、压缩响应信息等一些高级功能。
Filter实现方式?
答:在HttpServletRequest到达 Servlet 之前,拦截客户的HttpServletRequest 。根据需要检查HttpServletRequest,也可以修改HttpServletRequest 头和数据。
在HttpServletResponse到达客户端之前,拦截HttpServletResponse 。根据需要检查HttpServletResponse,也可以修改HttpServletResponse头和数据。
①拦截器是基于java的反射机制的,而过滤器是基于函数回调。
②拦截器不依赖与servlet容器,过滤器依赖与servlet容器。
③拦截器只能对action请求起作用,而过滤器则可以对几乎所有的请求起作用。
④拦截器可以访问action上下文、值栈里的对象,而过滤器不能访问。
⑤在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次。
⑥拦截器可以获取IOC容器中的各个bean,而过滤器就不行,这点很重要,在拦截器里注入一个service,可以调用业务逻辑。
参考文章:
Java三大器之拦截器(Interceptor)的实现原理及代码示例

8.jsp页面的执行过程
1.客户端发送请求给web容器
2.web容器将jsp首先转译成servlet源代码
3.web容器将servlet源代码编译成.class 文件
4.web容器执行.class 文件5.web容器将结果响应给客户端
参考链接:
9、多线程有两种实现方法:
方法一:继承Thread类,重写方法run();
方法二:实现Runnable接口,实现方法run();
实现同步有几种方法:例如:synchronized,wait,notify都可以实现同步。
10、垃圾回收器的基本原理是什么?垃圾回收器可以马上回收内存吗?有什么办法主动通知虚拟机进行垃圾回收?
对于GC来说,当程序员创建对象时,GC就开始监控这个对象的地址、大小以及使用情况。通常,GC采用有向图的方式记录和管理堆(heap)中的所有对象。通过这种方式确定哪些对象是"可达的",哪些对象是"不可达的"。当GC确定一些对象为"不可达"时,GC就有责任回收这些内存空间。可以。程序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行。强制执行垃圾回收:System.gc()。Runtime.getRuntime().gc()
静态类:static的是属于类的,而不是属于对象的,相当于是全局的,不可能被回收
静态变量本身不会被回收,但是它所引用的对象应该是可以回收的。
gc只回收heap里的对象,对象都是一样的,只要没有对它的引用,就可以被回收(但是不一定被回收). 对象的回收和是否static没有什么关系!
如:static Vector pane = new Vector(); pane = null; 如果没有其它引用的话,原来pane指向的对象实例就会被回收。
Java程序员在编写程序的时候不再需要考虑内存管 理。由于有个垃圾回收机制,Java中的对象不再有"作用域"的概念,只有对象的引用才有"作用域"。垃圾回收可以有效的防止内存泄露,有效的使用可以使用的内存。垃圾回收器通常是作为一个单独的低级别的线程运行,不可预知的情况下对内存堆中已经死亡的或者长时间没有使用的对象进行清楚和回收,程序员不能实时的调用垃圾回收器对某个对象或所有对象进行垃圾回收。
参考文章:http://www.cnblogs.com/sstarena/p/6004274.html
11、redirect和forward的区别
1.从地址栏显示来说
forward 是服务器请求资源,服务器直接访问目标地址url,把那个url的响应内容读取过来,然后把这些内容再发给浏览器,浏览器根本不知道服务器发送的内容从哪里来的,所以他的地址还是原来的地址。
redirect是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址,所以地址栏显示的是新的地址。
所以redirect等于客户端向服务器端发出两次request,同时也接受两次response。
2,从数据共享来看
forward:转发页面和转发到的页面可以共享request里面的数据
redirect:不能共享数据
3.从运用地方来说
forward:一般用于用户登录的时候,根据角色转发到相应的模块。
redirect:一般用于用户注销登录时返回主页面,和跳转到其他网站。
4.从效率来说
forward:高
redirect:低
12、常见的sql优化方法?
a.比如在频繁查询更新较少的情况下使用索引
b.尽量不要做全表扫描
c.慎用子查询和Union All
d.多表join时尽量用小表去join大表
e.善用不同的存储引擎,MySQL有多种不同的存储引擎,InnoDB,Aria,MEMORY根据需要给不同的表选择不同的存储引擎,比如要支持transaction的话用InnoDB等
13、关系型数据库和非关系型数据库之间的区别
1.关系型数据库通过外键关联来建立表与表之间的关系,
2.非关系型数据库通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定
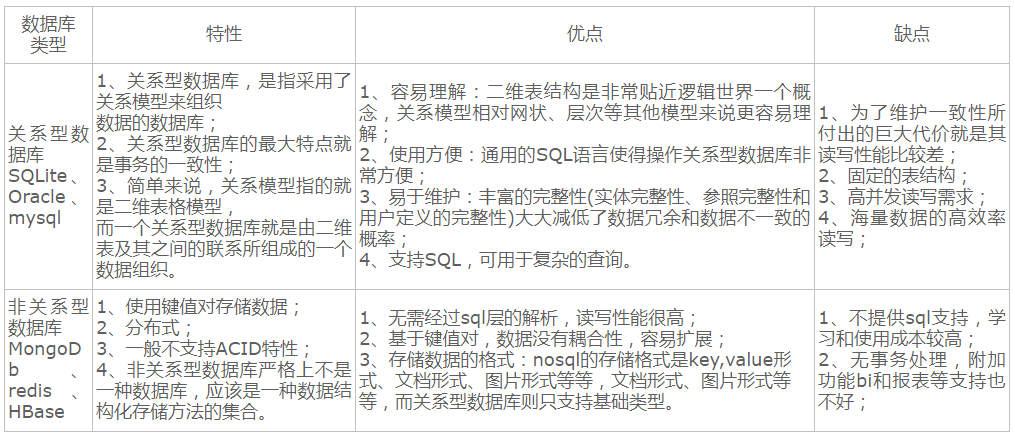
参考文章:
14、uml类图(Class Diagram)中类与类之间的关系及表示方式
- 依赖关系
- 关联关系
- 聚合关系
- 组合关系
- 继承关系
参考链接:uml类图(Class Diagram)中类与类之间的关系及表示方式
