

以TrueType为例谈字形描述
 在《深入理解“字符编码模型”》中,我们了解了字符完整的建模过程,但还留了一个悬念——如何从抽象字符转换为我们视觉所看到的“字形”。本文以 TrueType 字体为例,再和大家聊一聊如何描述字符的字形。
在《深入理解“字符编码模型”》中,我们了解了字符完整的建模过程,但还留了一个悬念——如何从抽象字符转换为我们视觉所看到的“字形”。本文以 TrueType 字体为例,再和大家聊一聊如何描述字符的字形。
以TrueType为例谈字形描述
作者:哲思
时间:2022.9.17
邮箱:zhe__si@163.com
GitHub:zhe-si (哲思) (github.com)
一、前言
在深入理解“字符编码模型”中,我们了解了字符完整的建模过程,但还留了一个悬念——如何从抽象字符转换为我们视觉所看到的“字形”。
本文以 TrueType 字体为例,再和大家聊一聊如何描述字符的字形。
二、什么是字形
“字形”故名思意,是字符的形体。字符本身是一种抽象的概念,代表了一种特定的符号。为了让我们可以从视觉上感知这个抽象字符,需要将它以某种形体画出来,这个形体就是“字形”。
字符与字形不是一对一的关系,而是多对多的关系。每个字符都可能有不同的写法,比如汉字“山”有楷书、行书、草书、隶书等风格的字形,如下图;l(小写L)和I(大写i)在很多风格的字形上十分接近(甚至相同)。

每种风格的字形,我们将它们集成在一起对某个抽象字符集进行描述,就是字体。
三、如何描述字形
字形的概念很容易理解,那么该如何描述字形呢?
3.1 点阵
我们都知道,显示屏其实是由许多小点组成的,小点越密集,就说分辨率越高,图案就越清晰。字符的字形在显示屏上显示,也要转化为用无数个小点组成的描述形式,我们称它为点阵。点阵用一个元素为0/1的方阵表述,字形所经过的地方用1表示,空白处用0表示,如下图。

点阵描述字形的好处在于简单直接,可以直接映射到显示屏、打印机等设备上打印出来而无需二次转换(当然,还需要缩放、上色等步骤)。但该描述形式在不同分辨率下只能对点阵的每一个点进行缩放,在更高的分辨率下会出现模糊、失真等问题。同时,该描述所占空间随着分辨率的增加呈几何提升,描述效率较低。
3.2 曲线矢量
为了更高效、准确的描述字形,人们提出了使用曲线矢量对字形进行描述。曲线矢量本身描述了字形的轮廓,基于矢量的某种规则(如:顺时针填充,逆时针为空)描述填充范围。
曲线矢量一般采用数学方程(样条函数曲线)进行描述,如:Type1 使用三次贝塞尔曲线来描述字形,TrueType 使用二次贝塞尔曲线描述。
众所周知,两点确定一条直线。而在两点之间添加一个曲线外点即可描述一条抛物曲线,曲线上的两点为曲线的终点,曲线外点为控制点,三点共同控制曲线的形状。
上述曲线中,比较有代表性的是二次贝塞尔曲线,形式如下图。
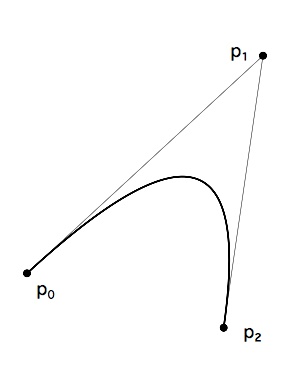
该曲线定义如下:给定三个点 p0、p1、p2,它们定义了从点 p0 到点 p2 的曲线,其中 p1 是曲线外点,位于曲线在 p0 的切线与曲线在 p2 的切线的交点处。也就是说,直线 p0p1 相切曲线于 p0,直线 p2p1 相切曲线于 p2。该曲线从 p0 到 p2 的参数方程如下:
多条相连的二次贝塞尔曲线可以表示更复杂的曲线。当两条曲线在连接点一阶连续(两曲线连接点的切线共线)时,如下图,
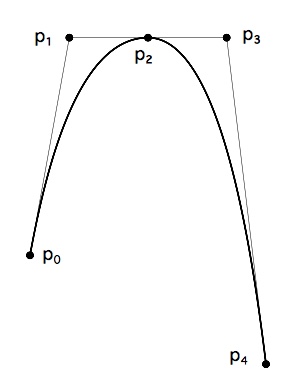
可以去除点 p2 来简化对曲线的描述,并在需要的时候根据其他点的信息对 p2 点进行重建。
通过组合曲线和直线,形成闭合曲线,即可描述复杂字形的轮廓,如下图所示:
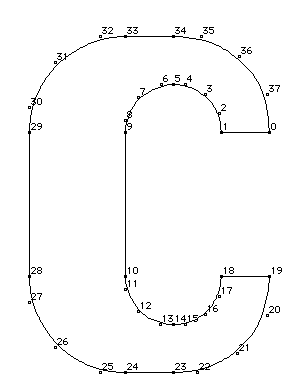
其中,黑色小圆点表示在曲线上的点,空心圆圈表示曲线外点。
但光是这样就可以描述所有的字形了吗?比如下图使用曲线描述字符“B”的情况,
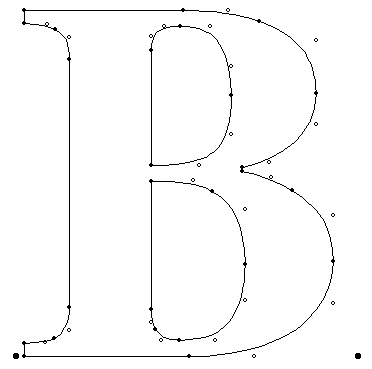
相信机制的小伙伴已经发现,在外轮廓内部还存在内轮廓。由于在字形“C”中只有单一的一个闭合图形,所以填充范围比较明确,让我们忽略了填充的问题。但在存在多层轮廓的字形中,基于这些封闭图形的轮廓,需要考虑哪部分需要填充、哪部分需要空白。
设计字形描述的前辈自然考虑到了这个问题,所以我们从一开始就说我们使用矢量描述的轮廓,也就是说轮廓存在方向性,有起点和终点。基于该方向性即可定义规则确定填充范围,比如:顺时针填充/逆时针空白、非零绕组数规则等。
当然,即使采用曲线矢量描述字形,在显示屏或打印机将字形渲染出来时,也要转化为点阵描述,但总是可以根据实际分辨率以最佳清晰度展示。
四、字形描述的典范——TrueType
到这里,我们已经对字形的描述有了整体的认识。接下来,我们以 TrueType 为例来看看字形描述的具体实现方式。
4.1 TrueType简介
TrueType 是 Apple 公司开发的轮廓字体标准,以为字体开发人员提供高度控制,可在不同字体大小下正确显示著称。现已成为 mac os、windows 等操作系统上最常见的字体格式。一般的文件拓展名为“.ttf”。
为了提高不同字体间相同字形的复用率,拓展 TrueType 字体格式,将多种字体组合到一个文件中,称为 TrueType Collection,常见的拓展名为“.ttc”。
4.2 TrueType的基本格式
TrueType 字体标准采用二进制数据描述,内部分成多个表格来描述不同种类的数据。这里的表格,类似一个个对象,在表格的第一个字段说明自身的数据种类,每种数据都有着对应的字段内容和顺序。在读取时,先确定表格对应哪个种类,在按照该种类表格的数据格式进行读取。
TrueType 的第一个表格是字体目录,一个特殊的表,在加载字体时首先被读取(可能部分读取),进而基于该目录访问其他的表格。字体目录分为两部分:Offset Subtable 和 Table Directory。
第一部分 Offset Subtable 的格式如下,
| 类型 | 名称 | 描述 |
|---|---|---|
| uint32 | scaler type | 指示用于光栅化此字体的 OFA 缩放器的标签 |
| uint16 | numTables | 当前字体的表格数(除字体目录) |
| uint16 | searchRange | (maximum power of 2 <= numTables)*16 |
| uint16 | entrySelector | log2(maximum power of 2 <= numTables) |
| uint16 | rangeShift | numTables*16-searchRange |
- scaler type 为 0x74727565(“true”,在苹果的系统)或者0x00010000(在 Windows 系统或者 Adobe 产品)都表示 TTF 格式。
- 我们基于 numTables 进而读取对应数目 Table Directory 的数据。
- 后三个字段用于使用二分搜索提高搜索 Table Directory 速度。
紧跟着 Offset Subtable 是 Table Directory,有 numTables 个目录项,分别对应字体中除字体目录外的每个表格,同时根据标签采用升序排序,方便二分快速搜索。每个表项格式如下,
| Type | Name | Description |
|---|---|---|
| uint32 | tag | 4 字节的表类型标识符 |
| uint32 | checkSum | 该表的校验和 |
| uint32 | offset | 该表在文件中的偏移量 |
| uint32 | length | 该表的长度 |
TTF 格式要求,必须要在字体的正文存在以下 9 种表格,来描述 TTF 字体所必须的信息:
| 标签 | 标签名称 | 描述 |
|---|---|---|
'cmap' |
字符到字形映射 | 将字符代码映射到字形索引。特定字体的编码取决于预期平台使用的约定。若要在不同编码约定的平台运行字体,需要多个编码表,每一种编码约定对应一个“cmap”子表。 |
'head' |
字体头 | 包含有关字体的全局信息。它记录了字体版本号、创建和修改日期、修订号和适用于整个字体的基本排版数据等以及验证字体数据完整性的校验和。 |
'hhea' |
水平布局头 | 包含布局其字符水平书写的字体所需的信息,如:从左到右或从右到左、基于基线上升/下降、倾斜等。 |
'hmtx' |
水平度量 | 包含字体中每个字形的水平布局的度量信息。 |
'glyf' |
字形数据 | 描述每个字形外观,包括构成字形轮廓的点以及该字形对应的指令。支持简单字形和复合字形。 |
'loca' |
位置索引 | 存储每个字形相对于“glyf”表起始的偏移位置,来提供对特定字形数据的快速随机访问。字形数据的长度可通过下一个字形的偏移计算得到。 |
'maxp' |
最大指标 | 确定了字体的内存要求。它以表版本号开头,描述了字形的数量和许多参数的最大限制。 |
'name' |
命名 | 包含人类可读的功能和设置名称、版权声明、字体名称、样式名称以及其他字体相关的信息。 |
'post' |
PostScript | 包含在 PostScript 打印机上使用 TrueType 字体所需的信息。 |
4.3 从抽象字符到字形
了解了 TrueType 的基本格式,我们来进一步研究 TrueType 是如何实现抽象字符到字形的映射的。
从抽象字符到字形的映射要解决两个主要问题:字符码位到字形索引的映射、字形的描述。
4.3.1 字符码位到字形索引映射
逻辑上我们是在抽象字符的基础上描述字形,但由于计算机使用数字描述字符,所以实际采用字符的编码(码位)来代指字符。由于在字体文件中我们不总是要描述所用字符集中所有的字符,同时针对不同字符集的编码顺序也不尽相同,为了解耦字符编码与字形索引,字形索引要单独编码,所以字体文件首先要描述字符码位到字形索引的映射关系。
TTF 使用 “cmap” 表格描述这种映射关系。由于一个字符文件需要适配多种字符编码方式,所以会包含多个编码子表分别描述这些字符编码到字形索引的映射。“cmap” 以表的版本号开头,后跟编码子表的数量,如下:
| 类型 | 名称 | 描述 |
|---|---|---|
| UInt16 | version | 版本号(设置为零) |
| UInt16 | numberSubtables | 编码子表数 |
接下来是按照平台标识符和平台内的编码标识符升序排序的编码子表(平台标识符和平台内编码标识符共同描述了一种编码方式),如下:
| 类型 | 名称 | 描述 |
|---|---|---|
| UInt16 | platformID | 平台标识符,对应 Unicode、Windows等 |
| UInt16 | platformSpecificID | 特定于平台的编码标识符,如在 Unicode 下的各个版本 |
| UInt32 | offset | 实际映射表的偏移量 |
目前“cmap”的字符编码到字形索引的映射表有九种可用的格式,分别对应不同场景下的映射描述,这里介绍一种比较有代表性的格式:format 4。
format 4
一种两字节编码格式。用于字体包含的字符码位落在几个连续的范围内的场景,来最大程度压缩多个连续的区间。
具体格式如下:
| Type | Name | Description |
|---|---|---|
| UInt16 | format | 格式编号设置为 4 |
| UInt16 | length | 子表的长度(以字节为单位) |
| UInt16 | language | 语言代码 |
| UInt16 | segCountX2 | 2 * segCount(段数) |
| UInt16 | searchRange | 2 * (2**FLOOR(log2(segCount))) |
| UInt16 | entrySelector | log2(searchRange/2) |
| UInt16 | rangeShift | (2 * segCount) - searchRange |
| UInt16 | endCode[segCount] | 每个段的结束字符代码,last = 0xFFFF |
| UInt16 | reservedPad | 此值应为零 |
| UInt16 | startCode[segCount] | 每个段的起始字符代码 |
| UInt16 | idDelta[segCount] | 段中所有字符代码到字形索引的增量 |
| UInt16 | idRangeOffset[segCount] | glyphIndexArray 的下标偏移量,或 0(一般为0,表示不使用 glyphIndexArray) |
| UInt16 | glyphIndexArray[variable] | 字形索引数组 |
该格式描述了 segCount 个分段的字符编码到字形索引的映射。核心描述字段为:
- endCode[segCount]:字符编码分段的结束码位
- startCode[segCount]:字符编码分段的开始码位
- idDelta[segCount]:字符编码到字形索引的增量
因此,根据分段的开始和结束码位确定分段,则:该段某字符的字形索引 = 字符码位 + idDelta。
以官方的例子进行说明:
| Name | Segment 1 Chars 10-20 | Segment 2 Chars 30-90 | Segment 3 Chars 100-153 | Segment 4 Missing Glyph |
|---|---|---|---|---|
| endCode | 20 | 90 | 153 | 0xFFFF |
| startCode | 10 | 30 | 100 | 0xFFFF |
| idDelta | -9 | -18 | -27 | 1 |
| idRangeOffset | 0 | 0 | 0 | 0 |
-
找码位为12的字形索引
12 在 [10, 20] 区间内,偏移为 -9,所以:字形索引 = 12 - 9
-
字符码位 [30, 90] 区间 --映射到-> 字形索引 [12, 72] 区间
12 = 30 - 18
72 = 90 - 18
4.3.2 字形描述
第二个问题就是字形的描述。TTF 采用上文介绍的二次贝塞尔曲线矢量描述字形,同时辅助字形调整指令来完善字形的最终展示。
TTF 使用 “glyf” 表格来描述某个字符的字形。我们通过字符编码在 “cmap” 表格查找到了对应字形的索引,通过字形索引进一步在 “loca” 字形索引表格查找,可以得到该字形对应的 “glyf” 字形描述表格的起始偏移位置和表格长度,读取该 “glyf” 表得到对应字形的描述。
以下是简单和复合字形通用的 “glyf” 表数据定义。
| 类型 | 名称 | 描述 |
|---|---|---|
| int16 | numberOfContours | 如果轮廓数为正数或零,则为单个字形; 如果轮廓数小于零,则字形为复合字形 |
| FWord | xMin | 坐标数据的最小 x |
| FWord | yMin | 坐标数据的最小 y |
| FWord | xMax | 坐标数据的最大 x |
| FWord | yMax | 坐标数据的最大 y |
以下是简单字形的数据定义,主要通过 xCoordinates、yCoordinates、endPtsOfContours 和 flags 确定字形的每个轮廓已经矢量方向,然后通过 instructionLength、instructions 描述的指令调整字形的最终显示。
| 类型 | 名称 | 描述 |
|---|---|---|
| uint16 | endPtsOfContours[n] | 每个轮廓的最后一个点的数组;n 是轮廓的数量;数组项是每个点的索引 |
| uint16 | instructionLength | 指令所需的总字节数 |
| uint8 | instructions[instructionLength] | 此字形的指令数组 |
| uint8 | flags[variable] | 标志数组,描述是否在曲线上、是否重复等情况 |
| uint8 或 int16 | xCoordinates[] | x 坐标数组;第一个是相对于(0,0),其他是相对于前一点 |
| uint8 或 int16 | yCoordinates[] | y 坐标数组;第一个是相对于(0,0),其他是相对于前一点 |
复杂字形的描述暂不讨论。
4.3.3 小结
深入理解“字符编码模型”中,我们完成了对抽象字符的建模,可以在抽象字符到计算机底层存储间相互映射。而 TrueType 等字体则是在抽象字符的基础上向上建模,描述字符如何转化为人类视觉理解上的字形图案。至此,我们已经明白了从人类直观看到的字符到计算机底层对字符描述的完整建模链路,如下图,
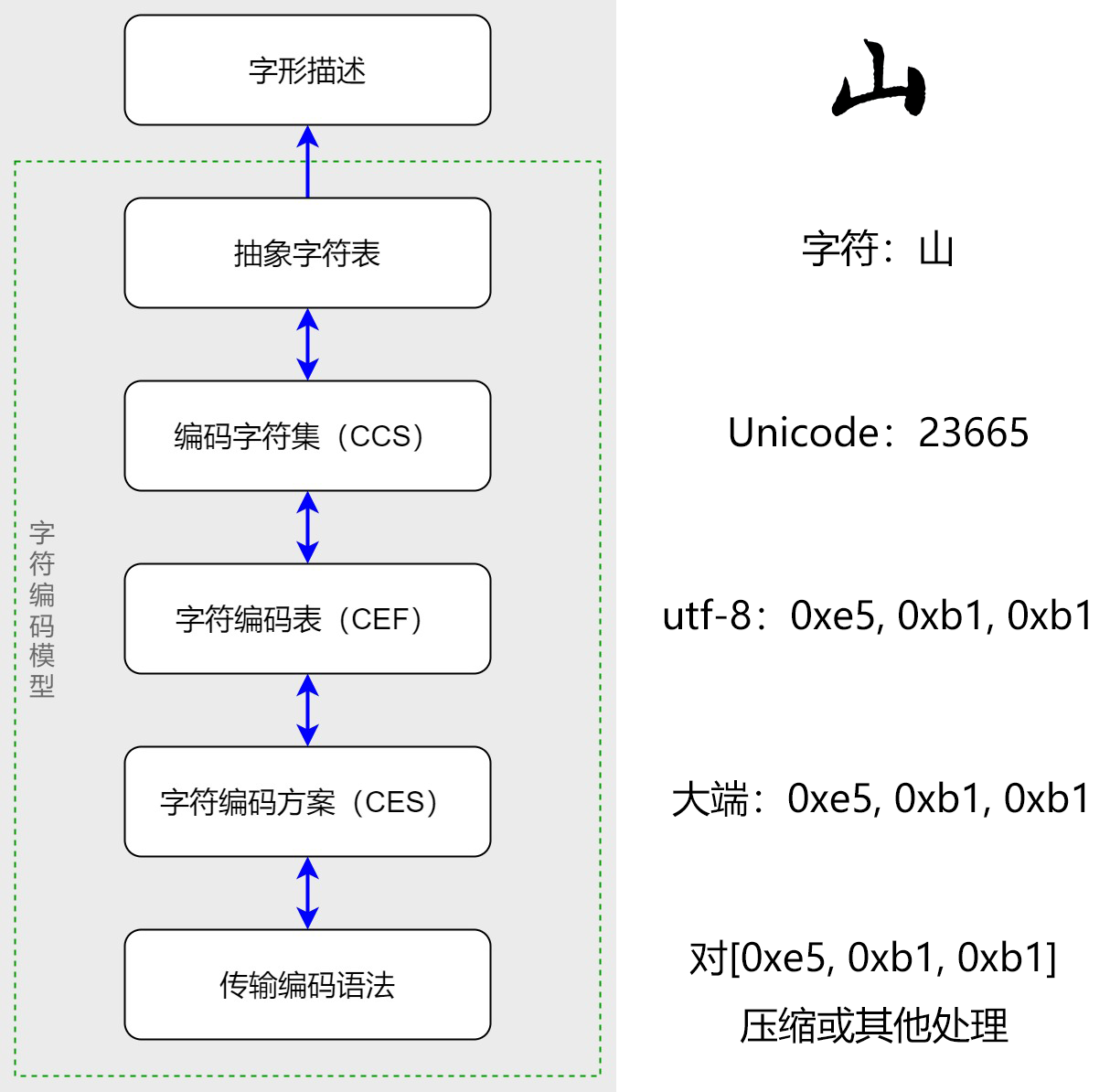
细心的小伙伴会发现,从“抽象字符表”到“字形描述”是单向转换,这是因为字符与字形间是多对多关系,字符到字形的映射是在字体中明确定义的,但从字形到字符的映射需要一种对字形的“理解”,无法直接简单根据字形映射到字符。而仿照人的思维对图案进行处理,就涉及到一个非常热门的领域——人工智能(计算机视觉),属于文字识别(OCR)任务。
五、后记
终于把深入理解“字符编码模型”留的坑给填上了。经过本次学习和总结,对字符这个概念有了系统的认识,也为电子文档的学习打下了坚实的基础。
有个小伙伴问我,为啥要研究字符建模的这些东西?可能是想下次做文档生成时更得心应手,可能是想举一反三学习计算机建模的思想,也可能只是对这些触手可及的东西到底是怎么实现的一点点好奇心罢了。
本文来自博客园,作者:_哲思,转载请注明原文链接:https://www.cnblogs.com/zhe-si/p/16712194.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号