


爬虫分页信息的获取(ruby+selenium python+selenium)
在爬虫的时候,我们会遇到一些问题,即使获取到全文的url,但是可能page的连接获取不完整,就会导致我们爬虫的时候,比如说爬商品信息,就会拿不完整商品信息。
页面信息大概有这两种情况:
第一种:
1,2,3,4,5,...,next,last
第二种:
1,2,3,4,5,>
实现语言:ruby or python(提供两种)
爬虫工具:selenium
先说说第一种情况:我们在当前层的时候可以拿到1,2,3,4,5,next,last对应的page页面的url,但是...的页面信息获取不到,可能这里面有好多页面,例如所有的页面可能是1,2,3,4,5,6,7,8,如果这种情况我们就拿不到6,7这两页,那怎么办呢?
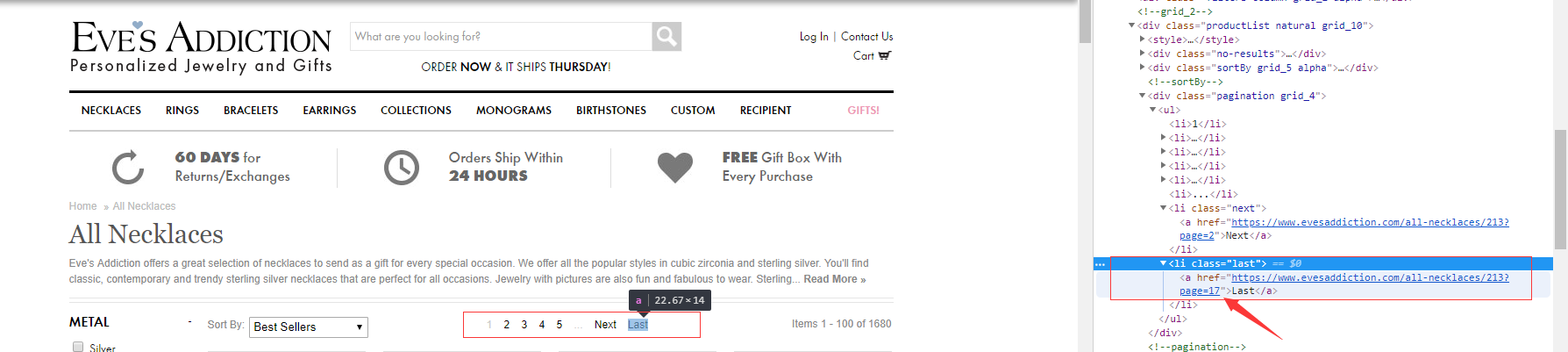
首先呢,如果last告诉我们最后一个page页面的信息,我们可以直接拿last的页面信息的对应的数字,就是所有的page总数,再提出一个网址page页面的前缀,我们即可以直接拼凑,来获取到page的页面数量,以及page的链接,我们来看一个例子:
url:https://www.evesaddiction.com/all-necklaces/213
#ruby实现的代码
def get_allpage(driver) #获取当前所有page页面对应的li page_mes=driver.find_element(:css,"div.pagination").find_elements(:tag_name,"li") #我们取到所有页面的数量 total_page_len = page_mes[page_mes.length-1].attribute("outerHTML").scan(/href=\"(.*?)\"/)[0][0].scan(/page=(\d+)/)[0][0] #提取page前面的url信息 #url前缀就是"https://www.evesaddiction.com/all-necklaces/213?" #url后缀就是page=1,2,3,4..total_page_len page_url = page_mes[page_mes.length-1].attribute("outerHTML").scan(/href=\"(.*?)\"/)[0][0].scan(/(.*?)page/)[0][0] #最后将结果返回 return page_url,total_page_len end
#python
def get_allpage(driver): page_mes=driver.find_element_by_css_selector("div.pagination").find_elements_by_tag_name("li") total_page_len=re.findall(r'page=(\d+)',page_mes[len(page_mes)-1].get_attribute("outerHTML"))[0] page_url=re.findall(r'href=\"(.*?)page',page_mes[len(page_mes)-1].get_attribute("outerHTML"))[0] return total_page_len,page_url
第二种情况,就是要一路点到底,才知道当前的页面数量
url:https://www.tous.com/us-en/watches/?p=8
当在第八页的时候是这样子的
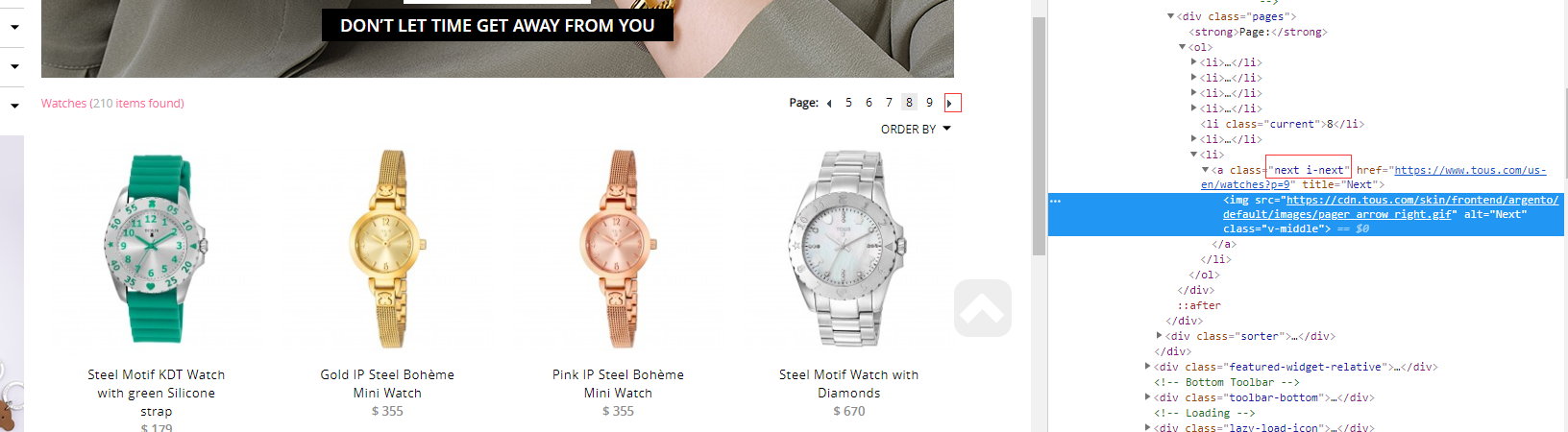
第九页的时候是这样子的
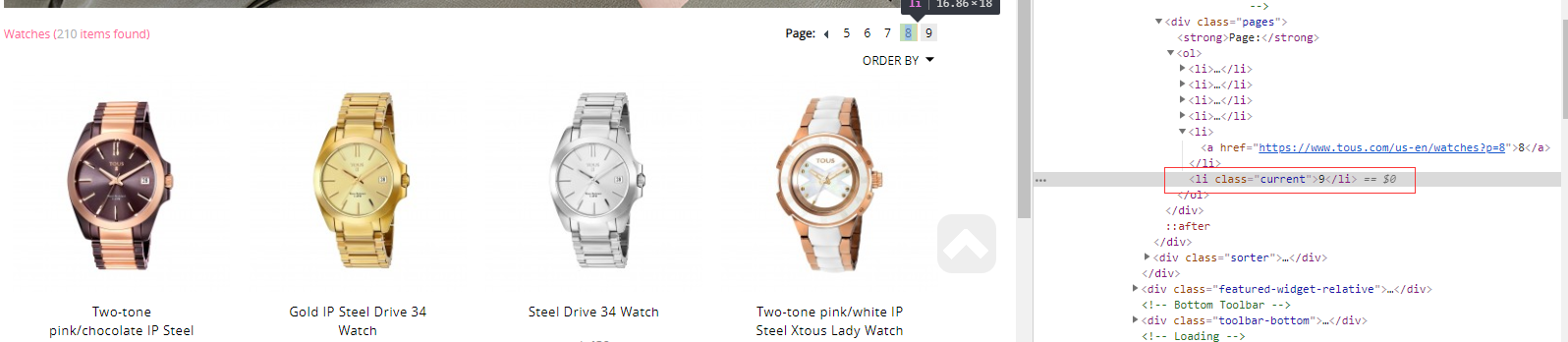
我们就用这个箭头的符号定位获取,判断他是否存在来判断是否我们已经点到最后了,也是实现拼接获取,前缀是url的前缀信息,后缀是page的页面
#ruby实现的代码
def get_all_page(driver) running=true total_page_len="" page_url="" while running page_mes=driver.find_element(:css,"div.pages").find_elements(:tag_name,"li") begin if page_mes[page_mes.length-1].attribute("outerHTML").scan(/next i-next/)[0][0].length > 0 driver.find_element(:css,"div.pages ol li a.next").click() end rescue total_page_len=page_mes[page_mes.length-1].text page_url=page_mes[page_mes.length-2].attribute("outerHTML").scan(/href=\"(.*?)\"/)[0][0].scan(/(.*?)p=/)[0][0] running = false end
end return total_page_len,page_url end
执行结果:然后拼接一下就可以啦
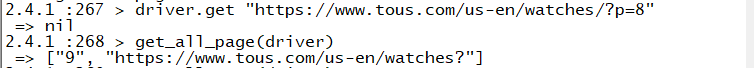
#python代码
def get_all_page(driver): running=True total_page_len="" page_url="" while running: page_mes=driver.find_element_by_css_selector("div.pages").find_elements_by_tag_name("li") if len(re.findall(r'next i-next',page_mes[len(page_mes)-1].get_attribute("outerHTML")))>0: driver.find_element_by_css_selector("div.pages ol li a.next").click() else: total_page_len=page_mes[len(page_mes)-1].text page_url=re.findall(r'href=\"(.*?)p=',page_mes[len(page_mes)-2].get_attribute("outerHTML"))[0] running=False return total_page_len,page_url
获取页面的page其实就是 page的url + page id

