
ElasticSearch玩耍
现在是大数据的时代,大家对于ElasticSearch 简称 es这块应该并不陌生,但是说到es就要讲讲 Lucene 和 es 的前世今生 了。
Lucene 和 es 的前世今生
Elasticsearch 是基于 Lucene 实现的。Lucene 是一个开源的全文检索引擎库,它可以用于构建各种类型的搜索引擎,包括网页搜索引擎、文本搜索引擎、音乐搜索引擎等等。Elasticsearch 在 Lucene 的基础上进行了扩展,提供了更多的更丰富的查询语句,并且通过 RESTful API 可以更方便地与底层交互 。
lucene 是最先进、功能最强大的搜索库。如果直接基于 lucene 进行开发,即便写一些简单的功能,也要写大量的 Java 代码,非常复杂,必须深入理解原理。
elasticsearch 基于 lucene,隐藏了 lucene 的复杂性,提供了简单易用的 restful api / Java api 接口(另外还有其他语言的 api 接口)。
es的优势:
分布式的文档存储引擎
分布式的搜索引擎和分析引擎
分布式,支持 PB 级数据
我们为什么要用es,我觉得可以从三个点展开
1.为什么使用ElasticSearch
快,是在Lucene的基础上建立而成的。
2.什么是ElasticSearch
开源,高扩展的分布式全文检索引擎,可以实时的存储、检索数据。
3.ES的特点
基于Lucene进行封装,操作简单。
简单的Resultful ApI通信方式。
本身支持集群扩展,可扩展到上百台服务器。
能在分布式项目/集群中使用
好啦不说废话,直接上干货,es有一个可视化工具叫做kibana,Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。
这边用的是阿里云集群的es,以及kibana的工具,没有搭建的环节,需要看es如何安装和搭建的网上有很多教程可以参考。
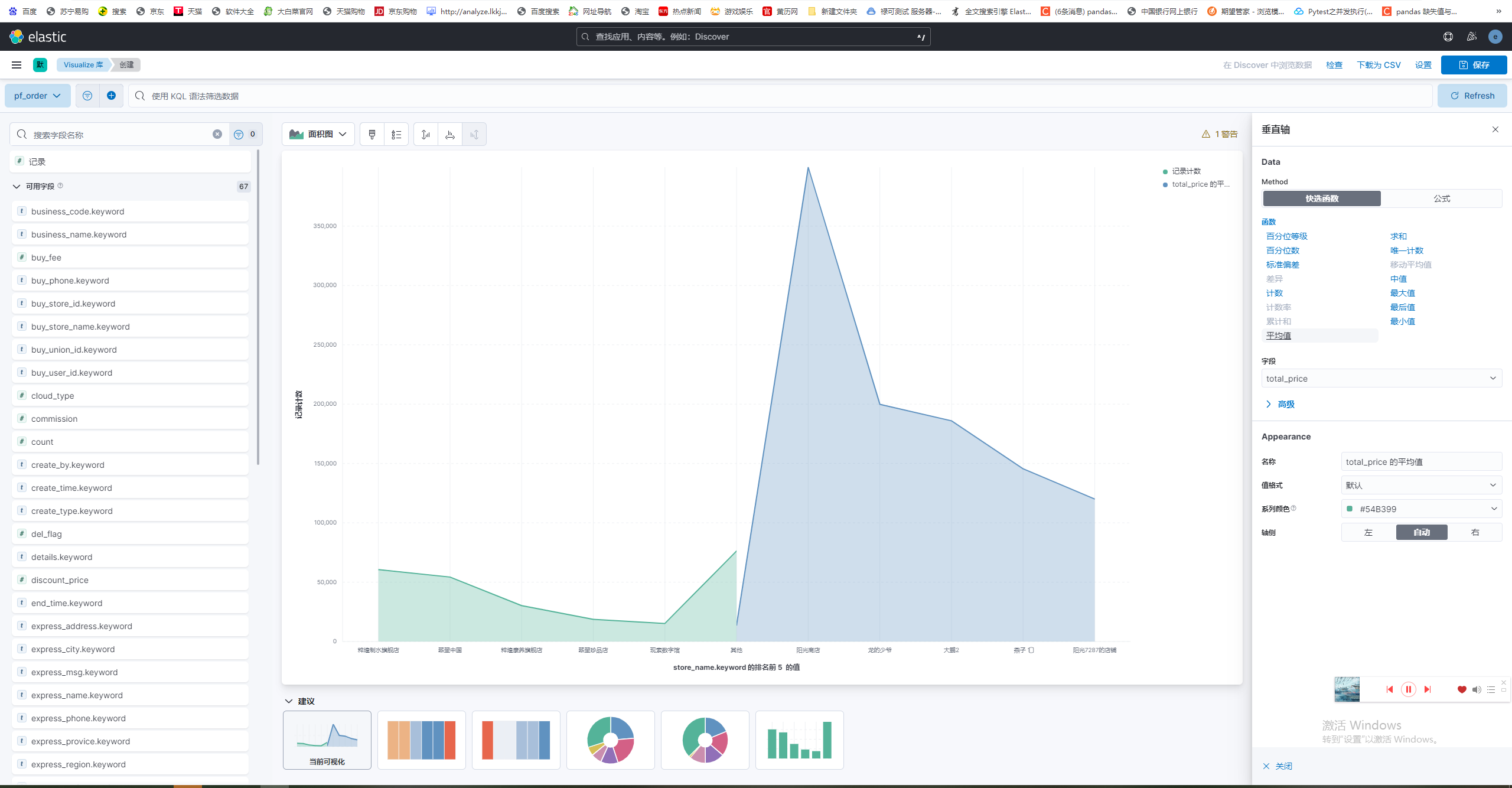
当然其实也支持数据可视化图标,选择横纵坐标,简单举个例子
第二步玩一些es操作
//访问Elasticsearch实例
get /
//创建一个名称为product_info的索引
PUT /product_info
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"productName": {
"type": "text",
"analyzer": "ik_smart"
},
"annual_rate":{
"type":"keyword"
},
"describe": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
//插入数据
POST /product_info/_bulk
{"index":{}}
{"productName":"理财产品A","annual_rate":"3.2200%","describe":"180天定期理财,最低20000起投,收益稳定,可以自助选择消息推送"}
{"index":{}}
{"productName":"理财产品B","annual_rate":"3.1100%","describe":"90天定投产品,最低10000起投,每天收益到账消息推送"}
{"index":{}}
{"productName":"理财产品C","annual_rate":"3.3500%","describe":"270天定投产品,最低40000起投,每天收益立即到账消息推送"}
{"index":{}}
{"productName":"理财产品D","annual_rate":"3.1200%","describe":"90天定投产品,最低12000起投,每天收益到账消息推送"}
{"index":{}}
{"productName":"理财产品E","annual_rate":"3.0100%","describe":"30天定投产品推荐,最低8000起投,每天收益会消息推送"}
{"index":{}}
{"productName":"理财产品F","annual_rate":"2.7500%","describe":"热门短期产品,3天短期,无须任何手续费用,最低500起投,通过短信提示获取收益消息"}
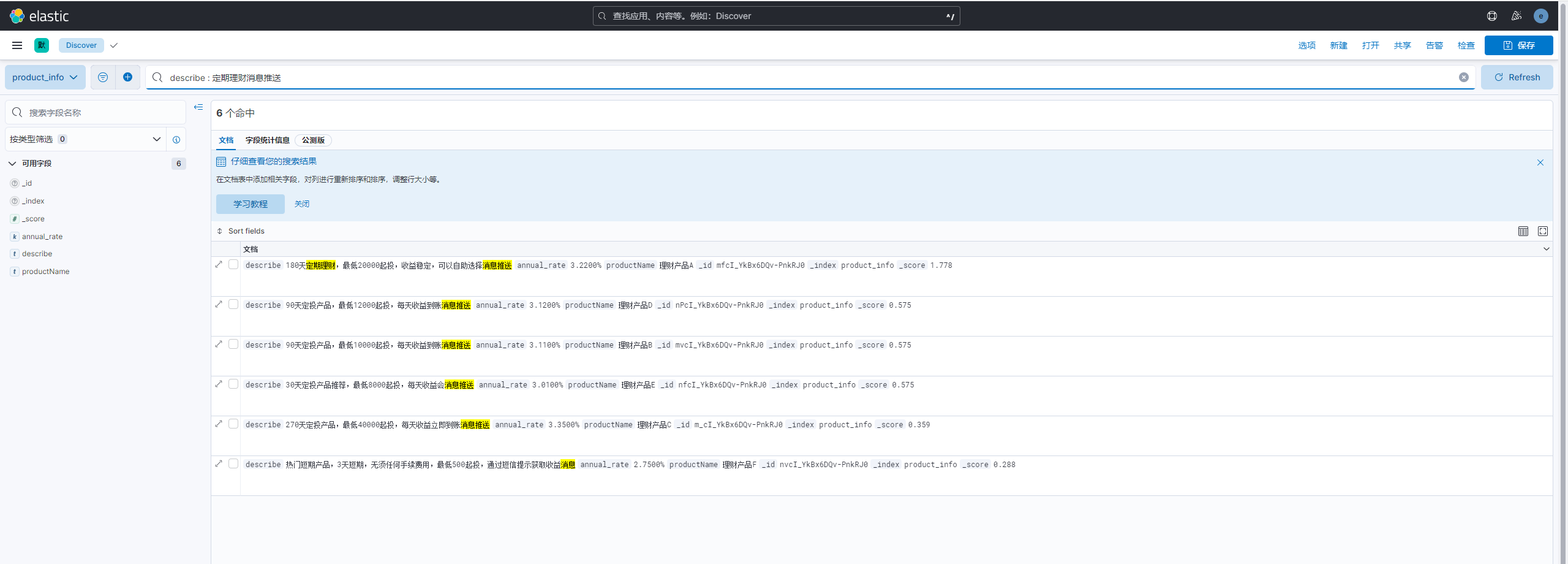
//搜索数据 搜索描述内容包含每天收益到账消息推送的所有产品
GET /product_info/_search
{
"query": {
"match": {
"describe": "每天收益到账消息推送"
}
}
}
//搜索年化率在3.0000%到3.1300%之间的产品
get /product_info/_search
{
"query":{
"range":{
"annual_rate": {
"gte": "3.0000%",
"lte": "3.1300%"
}
}
}
}
#删除索引
DELETE /product_info
第三步es分词器玩耍
#分词查询器
#keyword默认不分词,用于精准查询(term) text会被分词,比如“苹果笔记本”,可能会被拆分为“苹果”、“笔记本”。如果用term查询“苹果笔记本”,结果为空
GET _analyze
{
"analyzer": "standard",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
GET _analyze
{
"analyzer": "simple",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
GET _analyze
{
"analyzer": "keyword",
"text": "2 Running quick brown-foxes leap over lazy dog in the summer evening"
}
#ik_smart 是 IK 分词器的一种分词模式,它会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、人民大会堂” 。
GET _analyze
{
"analyzer": "ik_smart",
"text": "特朗普5日接受采访时表示取消佛罗里达州的议程,他可能在白宫接受共和党总统候选人提名并发表演讲。"
}
#ik_max_word 是 IK 分词器的一种分词模式,它会做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语 。
GET _analyze
{
"analyzer": "ik_max_word",
"text": "特朗普5日接受采访时表示取消佛罗里达州的议程,他可能在白宫接受共和党总统候选人提名并发表演讲。"
}
第四步我们也可以通过ksl语句查询
python SDK的使用
因为我本身是python语言,肯定调用es的地方有很多,也是用python sdk 去操作es。
首先肯定是es的连接创建了,使用完要记得关闭哦
es = Elasticsearch(hosts="host:port",basic_auth=("es账户", 'es密码'))
#查全量数据 query = { "query": { "match_all": {} } } result = es.search(index="product_info", body=query)
#查询条数
count = result["hits"]["total"]["value"]
#匹配describe带有 “收益推送” 的分词信息,结果根据分数排序 query = { "query": { "match": { "describe":"收益推送" } } } result = es.search(index="product_info", body=query) #查询annual_rate >=3.0000% and annual_rate <=3.1300% query = { "query": { "range": { "annual_rate":{ "gte":"3.0000%", "lte":"3.1300%" } } } } result = es.search(index="product_info", body=query) #查询所有,并按照total_price降序,查询2条 query = { "query":{ "match_all":{} }, "sort":{ "total_price":"desc" }, "from":1, "size":2 } #短语搜索match_phrase query={ "query":{ "match_phrase":{ "name":"清爽薄荷除螨皂手工皂精油皂洁面沐浴皂洗脸香皂滋润洁净学生清洁" } } } #拆词匹配 query={ "query":{ "match":{ "name":"清爽薄荷除螨皂手工皂精油皂洁面沐浴皂洗脸香皂滋润洁净学生清洁" } } } # 多条件查找bool query={ "query":{ "bool":{ "must":[ {"match":{"name":"清醒点沉香湿纸巾"}} ], "must_not":[ {"match":{'name':"80"}} ] } } } # fillter 查询 查询total_price>=0 and total_price <= 30 query = { "query": { "bool": { "filter": { "range": { "total_price": { "gte": "0", "lte": "30" } } } } } } # fillter 查询 查询total_price>=0 and total_price <= 30 查询数量为100条 不然默认10条 query = {"size": 100, "query":{ "bool":{ "filter":{ "range":{ "total_price":{ "gte": "0", "lte": "30" } } } } } } #查询total_price>=20 and total_price <= 30 并按total_price 降序排序 query = { "query": { "range": { "total_price":{ "gte":"20", "lte":"30" } } }, "sort":{ "total_price":"desc" } } #term查询 精确查找包含分词 query = { "query":{ "terms":{ "name":["80","香湿"] } } } #match 分词之后匹配 query = { "query":{ "match":{ "name":"沉香湿纸巾" } } }
#创建索引 忽略400--创建成功就忽略
result=es.indices.create(index="user",ignore=400)
插入数据
es.index(index='user',body={"name":"可可1", "age": 30})
es.index(index='user',body={"name":"可可2", "age": 19})
es.index(index='user',body={"name":"可可3", "age": 20})
es.index(index='user',body={"name":"可可4", "age": 21})
es.index(index='user',body={"name":"可可5", "age": 22})
es.index(index='user',body={"name":"可可6", "age": 23})
es.index(index='user',body={"name":"可可7", "age": 24})
es.index(index='user',body={"name":"可可8", "age": 25})
#根据条件删除指定数据
query = {
"query": {
"match": {
"id": "7ffcf7ad464c4a3b9ac7a78162f1adfe"
}
}
}
es.delete_by_query(index="pf_order",body=query)
#修改数据
query = {
"query": {
"match": {
"id":"ffbf66c3c8574e6fa5bb09a0c7190b4f"
}
}
}
result = es.search(index="pf_order",body=query)
print(result)
document = {'store_name': '粹煌制水旗舰店'}
es.update(index="pf_order", id="zp9jHIoB_8VsEPNQ662x", body={"doc": document})
#聚合查询
query = {
"size": 0,
"aggs": {
"group_by_store": {
"terms": {
"field": "store_id",
"size": 10
},
"aggs": {
"sum_count": {
"sum": {
"field": "count"
}
}
}
}
}
}
#我们写一个操作,从mysql读取数据并且插入进es
#伪代码
#pd_order_datas为我们读取的数据库表的数据 类型为数组
actions = [
{"_index":"pf_order","_source":d} for d in pd_order_datas
]
#批量插入
bulk(es,actions)
curl的方式
curl -u <user>:<password> http://<host>:<port>
#查看集群健康状况
curl -u <user>:<password> -XGET 'http://es-cn-vxxxxx****.elasticsearch.aliyuncs.com:9200/_cat/health?v'
#查看集群中包含的索引信息
curl -u <user>:<password> -XGET 'http://es-cn-vxxxxx****.elasticsearch.aliyuncs.com:9200/_cat/indices?v'
#创建索引
curl -u <user>:<password> -XPUT 'http://es-cn-vxxxxx****.elasticsearch.aliyuncs.com:9200/product_info'
#为索引创建mapping
curl -u <user>:<password> -XPUT 'http://es-cn-vxxxxx****.elasticsearch.aliyuncs.com:9200/product_info/_doc/_mapping?include_type_name=true' -H 'Content-Type: application/json' -d '
{
"_doc":{
"properties": {
"productName": {"type": "text","analyzer": "ik_smart"},
"annual_rate":{"type":"keyword"},
"describe": {"type": "text","analyzer": "ik_smart"}
}
}
}'
#创建单个文档
curl -u <user>:<password> -XPOST 'http://es-cn-vxxxxx****.elasticsearch.aliyuncs.com:9200/product_info/_doc/1?pretty' -H 'Content-Type: application/json' -d '
{
"productName":"testpro",
"annual_rate":"3.22%",
"describe":"testpro"
}'
#创建多个文档
curl -u <user>:<password> -XPOST http://es-cn-vxxxxx****.elasticsearch.aliyuncs.com:9200/_bulk -H 'Content-Type: application/json' -d'
{ "index" : { "_index": "product_info", "_type" : "_doc", "_id" : "1" } }
{"productName":"testpro","annual_rate":"3.22%","describe":"testpro"}
{ "index" : { "_index": "product_info", "_type" : "_doc", "_id" : "2" } }
{"productName":"testpro1","annual_rate":"3.26%","describe":"testpro"}'
#搜索文档
curl -u <user>:<password> -XGET 'http://es-cn-vxxxxx****.elasticsearch.aliyuncs.com:9200/product_info/_doc/1?pretty'
#删除索引
curl -u <user>:<password> -XDELETE 'http://es-cn-vxxxxx****.elasticsearch.aliyuncs.com:9200/product_info'
还有postman工具进行查询等,其实原理都是很类似的,万变不离其中。
在这个数据的时代,es还是非常重要的,简单举几个例子。
搜索引擎:Elasticsearch可以作为搜索引擎使用,通过建立索引来存储和搜索文本数据。它支持全文搜索、模糊搜索、聚合搜索等多种搜索方式,能够满足不同类型的搜索需求。
日志分析:Elasticsearch可以用于实时分析和查询大量的日志数据。通过创建索引并使用相关查询语句,可以轻松地对日志进行聚合、过滤和统计分析。
数据挖掘:Elasticsearch可以用于数据挖掘和预测分析。通过构建索引并使用聚类、分类、关联规则挖掘等算法,可以发现数据中的隐藏模式和关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号