
pandas真是数据分析的好东西,使得代码简洁了不少
利用python做了爬虫,服务端,自动化测试,也都做了相应的编码以及架构处理,近期就想来玩玩数据分析,这个才是好前景呀!
我们来看看这个网站,url = "http://www.compassedu.hk/qs",爬取里面的table数据, 今天就来爬虫这个地址,并保存csv以及自动创建数据库
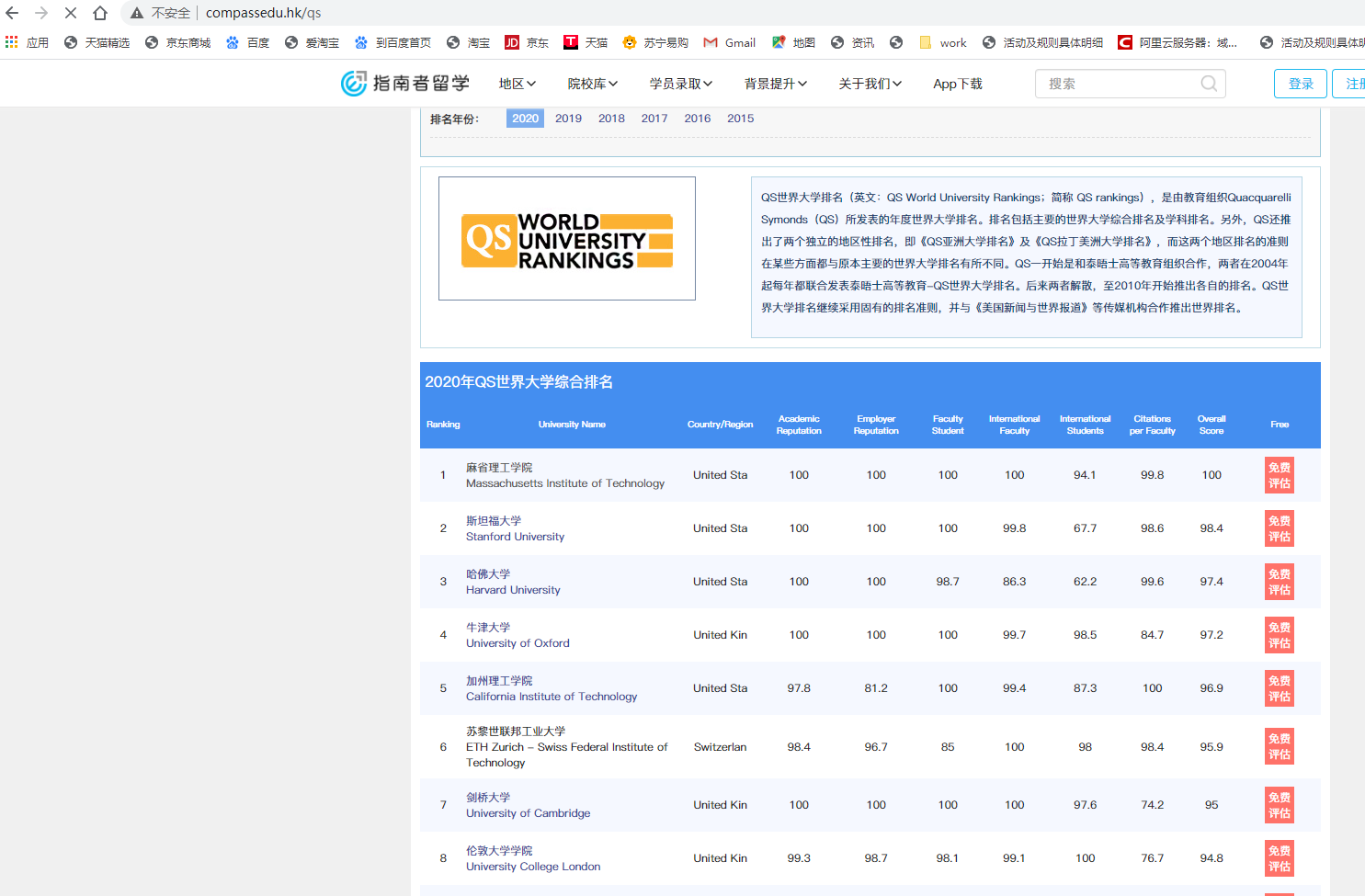
在还没学习数据分析前,像这种静态网站我们一般使用requests+BeautifulSoup进行请求和解析,以下是我的代码,不使用pandas的
# -*- coding: utf-8 -*- import requests import pandas as pd from bs4 import BeautifulSoup from sqlalchemy import create_engine import pymysql import numpy as np import traceback from openpyxl import Workbook url = "http://www.compassedu.hk/qs" res = requests.get(url) #提取表格数据 soup = BeautifulSoup(res.content,"lxml") table = soup.select("table#rk")[0] table_datas = [] #提取列名 one_tr = table.select("tr")[0] tr_datas = [] for th in one_tr.select("th"): tr_datas.append(th.get_text()) table_datas.append(tr_datas) for tr in table.select("tr"): tr_datas = [] for th in tr.select("td"): tr_datas.append(th.get_text()) if tr_datas: table_datas.append(tr_datas) #保存excel wb = Workbook() ws = wb.active for table in table_datas: ws.append(table) wb.save("result3.xlsx") mysql_conf = { "host": '127.0.0.1', "port": 3306, "user": 'root', "password": '你自己的数据库密码', "db": 'analysis', "charset": "utf8", "cursorclass": pymysql.cursors.DictCursor } def get_connection(): try: conn = pymysql.connect(**mysql_conf) return conn except: return None #创建数据库连接 conn = get_connection() ok_table_datas = [] for i in range(1,len(table_datas)): ok_table_datas.append(tuple(table_datas[i])) try: with conn.cursor() as cursor: #以元组形式插入 一次插入完 这个快 sql = '''insert into university2020three values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)''' cursor.executemany(sql,ok_table_datas) conn.commit() #分条插入 分条提交 效率比较慢 # for i in range(1,len(table_datas)): # print(table_datas[i]) # sql = '''insert into university2020three values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)''' # cursor.execute(sql,(table_datas[i])) # conn.commit() except Exception as e: print(traceback.format_exc()) print(e) finally: conn.close()
在我学习完pandas之后,我就觉得这个写法太笨了,我就解析还是用BeautifulSoup,保存excel和sql用pandas
# -*- coding: utf-8 -*- import requests import pandas as pd from bs4 import BeautifulSoup from sqlalchemy import create_engine import pymysql import numpy as np import traceback from openpyxl import Workbook url = "http://www.compassedu.hk/qs" res = requests.get(url) soup = BeautifulSoup(res.content,"lxml") table = soup.select("table#rk")[0] table_datas = [] #获取列标题 one_tr = table.select("tr")[0] tr_datas = [] for th in one_tr.select("th"): tr_datas.append(th.get_text()) table_datas.append(tr_datas) #获取table的数据 for tr in table.select("tr"): tr_datas = [] for th in tr.select("td"): tr_datas.append(th.get_text()) if tr_datas: table_datas.append(tr_datas) # data = pd.DataFrame(table_datas) #指定标题 上面是不指定标题 # data = pd.DataFrame(table_datas,columns=['Ranking', 'University Name','Country/Region','Academic Reputation','Employer Reputation','Faculty Student','International Faculty','International Students','Citations per Faculty','Overall Score','Free']) #转numpy.ndarray data = np.array(table_datas) #获取列名称 并转数据类型 和上面注释的data一样 data = pd.DataFrame(data[1:],columns=data[0]) data.to_csv("results_2.csv",index=None,encoding='utf_8_sig') conn = create_engine("mysql+pymysql://root:数据库密码@127.0.0.1:3306/analysis") data.to_sql("university2020-2",con=conn,if_exists='append',index=False)
最后我发现pandas不止可以用来csv,和sql简化很多,还可以直接读取就完事了,请看接下来的表演
# -*- coding: utf-8 -*- import requests import pandas as pd from bs4 import BeautifulSoup from sqlalchemy import create_engine import pymysql import numpy as np import traceback from openpyxl import Workbook url = "http://www.compassedu.hk/qs" res = requests.get(url) # 比较简便 还会根据数据类型创建数据库 html=res.content.decode(encoding=res.apparent_encoding) soup = BeautifulSoup(html,"lxml") table = soup.find("table",id="rk") datas = pd.read_html(table.prettify()) data = datas[0] data.to_csv("results.csv",encoding='utf_8_sig',index=False) conn = create_engine("mysql+pymysql://root:数据库地址@127.0.0.1:3306/analysis") data.to_sql("university2020",con=conn,if_exists='append',index=False)
第三种简简单单就搞定了,利用python有时候已经很方便了,但是会数据分析之后,有些东西不管爬虫还是什么的都会更加便捷,加油,未来可期。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号